Уроки 57 — 59базы данныхсистемы управления базами данных (субд)
Содержание:
- Модели баз данных — иерархическая база данных
- Состав частей реляционной модели данных
- Объектно-ориентированные субд
- Концептуальная модель базы данных
- Сетевые
- Структура реляционной модели данных
- Операторы поиска данных
- Основные свойства типа hierarchyidKey Properties of hierarchyid
- Язык описания данных иерархической модели
- Язык манипулирования данными в сетевой модели
- Недостатки
- Внешние модели
- Ключи в БД
Модели баз данных — иерархическая база данных
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Состав частей реляционной модели данных
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
Структурная часть
Структурная часть (аспект), отвечает за принцип построения структуры реляционной базы данных на нормализированном наборе n-арных отношений, в форме таблиц
Важно что реляционная база данных, структурно может представляться только в виде отношений
Манипуляционная часть
В манипуляционной части модели утверждаются операторы манипулирования отношениями — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
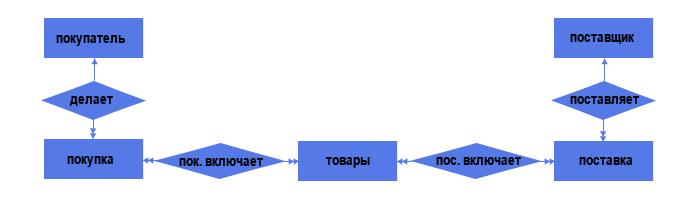
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
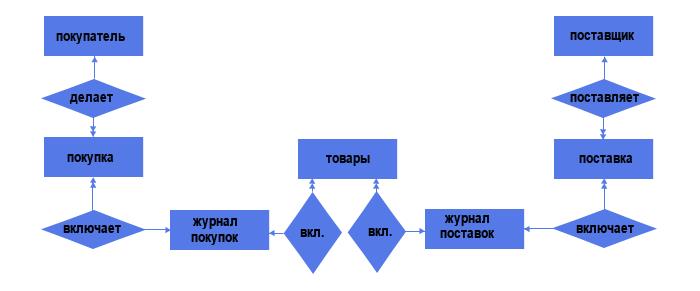
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:

Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Операторы поиска данных
Синтаксис:
GET UNIQUE <имя
сегмента> WHERE <список поиска>;
список поиска
состоит из последовательности условий вида:
<имя сегмента>.<имя
поля>ОС <constant или имя другого поля данного сегмента или имя переменной>:
ОС — операция
сравнения;
условия могут
быть соединены логическими операциями И и ИЛИ {& , V}.
Назначение:
Получить
единственное значение.
Пример:
Найти типовую
модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
GET UNIQUE ТИПОВЫЕ
МОДЕЛИ
WHERE Типовые
модели.Стоимость <= $600
AND Типовые модели,Количество
на складе >= 10
Данная команда
всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента,
удовлетворяющий условиям поиска.
Синтаксис:
GET NEXT <имя
сегмента> WHERE <список аргументов поиска>
Назначение:
Получить
следующий экземпляр сегмента для тех же условии.
Пример:
Напечатать
полный список заказов стоимостью не менее $500.
GET UNIQUE ИНДИВИДУАЛЬНЫЕ
МОДЕЛИ
WHERE Индивидуальные
модели.Стоимость >- $500
WHILE NOT EAIL
(пока не конец поиска) DO
PRINT № заказа.
Стоимость, Количество
GET NEXT ИНДИВИДУАЛЬНЫЕ
МОДЕЛИ
END
Синтаксис:
GET NEXT <имя
сегмента> WITHIN PARENT
Назначение:
Получить
следующий для того же исходного.
Пример:
Получить
перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10
с объемом 10 Гбайт.
GET UNIQUE СКЛАД
WHERE Склад.Номер = 1
GET NEXT ИЗДЕЛИЕ
WITHIN PARENT
WHERE Изделие.Наименование
= «Винчестер»
GET NEXT ХАРАКТЕРИСТИКИ
WITHIN PARENT
WHERE ХАРАКТЕРИСТИКИ.Параметр
= 10 AND
ХАРАКТЕРИСТИКИ.Единицы
Измерения = Гб AND
ХАРАКТЕРИСТИКИ.Величина
> 10
While Not Fail
(пока поиск не завершен) DO
Get Next Within
Parent
end
Основные свойства типа hierarchyidKey Properties of hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии.A value of the hierarchyid data type represents a position in a tree hierarchy. Значения hierarchyid обладают следующими свойствами.Values for hierarchyid have the following properties:
-
Исключительная компактностьExtremely compact
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла.The average number of bits that are required to represent a node in a tree with n nodes depends on the average fanout (the average number of children of a node). Для структур с низкой степенью ветвления (0-7) объем занимаемой памяти равен примерно 6*logA n бит, где A — среднее ветвление.For small fanouts, (0-7) the size is about 6*logA n bits, where A is the average fanout. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит.A node in an organizational hierarchy of 100,000 people with an average fanout of 6 levels takes about 38 bits. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.This is rounded up to 40 bits, or 5 bytes, for storage.
-
Сравнение проводится в порядке приоритета глубиныComparison is in depth-first order
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину.Given two hierarchyid values a and b, a<b means a comes before b in a depth-first traversal of the tree. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом.Indexes on hierarchyid data types are in depth-first order, and nodes close to each other in a depth-first traversal are stored near each other. Например, потомки некоторой записи хранятся рядом с этой записью.For example, the children of a record are stored adjacent to that record.
-
Поддержка произвольных вставок и удаленийSupport for arbitrary insertions and deletions
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами.By using the GetDescendant method, it is always possible to generate a sibling to the right of any given node, to the left of any given node, or between any two siblings. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее.The comparison property is maintained when an arbitrary number of nodes is inserted or deleted from the hierarchy. Большинство операций вставки и удаления сохраняют свойство компактности.Most insertions and deletions preserve the compactness property. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.However, insertions between two nodes will produce hierarchyid values with a slightly less compact representation.
Язык описания данных иерархической модели
В рамках
иерархической модели выделяют языковые средства описания данных (DDL, Data Definition
Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая
база описывается набором операторов, определяющих как ее логическую структуру,
так и структуру хранения БД. Описание начинается с оператора определения базы — DBD (Data Base
Definition):
DBD Name = <
имя БД>, ACCESS = < способ доступа>
Способ доступа
определяет способ организации взаимосвязи физических записей.
Определено 5 способов доступа:
HSAM
—
hierarchical sequential access method (иерархически
последовательный метод),
HISAM
—
hierarchical index sequential access method
(иерархически индексно-последовательный метод),
EDAM
—
hierarchical direct access method (иерархически прямой метод),
HID AM
—
hierarchical index direct access method (иерархически индексно-прямой метод),
INDEX
—
индексный метод.
Далее идет
описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>. DEVICE =< устройство хранения БД>,
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться
и превысит исходную длину записи до модификации. В этом случае при определенных
методах хранения может понадобиться дополнительное пространство хранения, где
и будут размещены дополнительные данные. Это пространство и называется областью
переполнения.
После описания
всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш
с иерархией. Описание сегментов всегда начинается с описания корневого сегмента.
Общая схема описания типа сегмента такова:
SEGM NAME =
< имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя
частота реализаций сегмента под одним исходным>
PARENT = <имя
родительского сегмента>
Параметр
FREQ определяет среднее количество экземпляров данного сегмента, связанных с
одним экземпляром родительского сегмента. Для корневого сегмента это число возможных
экземпляров корневого сегмента.
Для корневого
сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание
полей:
FIELD NAME =
{(<имя поля> .{U M}) | <имя поля> }.
START = <
номер байта, с которого начинается значения поля >,
BYTES = <размер
поля в байтах>,
TYPE = {X |
Р | С}
Признак SEQ
— задается для ключевого поля, если экземпляры данного сегмента физически упорядочены
в соответствии со значениями данного поля.
Параметр
U задается, если значения ключевого поля уникальны для всех экземпляров данного
сегмента, М — в противном случае. Если поле является ключевым, то его описание
задается в круглых скобках, в противном случае имя поля задается без скобок.
Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены
только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С
— символьный.
Заканчивается
описание схемы вызовом процедуры генерации:
- DBDGEN — указывает
на конец последовательности управляющих операторов описания БД; - FINISH — устанавливает
ненулевой код завершения при обнаружении ошибки; - END — конец.
В системе
может быть несколько физических БД (ФБД), но каждая из них описывается отдельно
своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один
корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
Язык манипулирования данными в сетевой модели
Все операции
манипулирования данными в сетевой модели делятся на навигационные операции
и операции модификации.
Навигационные
операции осуществляют перемещение по БД путем прохождения по связям, которые
поддерживаются в схеме БД. В этом случае результатом является новый единичный
объект, который получает статус текущего объекта.
Операции
модификации осуществляют как добавление новых экземпляров отдельных типов записей,
так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию
отдельных составляющих внутри конкретных экземпляров записей. Средства модификации
данных сведены в табл. 3.1:
Таблица
3.1. Операторы манипулирования данными в сетевой модели
|
Операция |
Назначение |
||
|
READY |
Обеспечение |
||
|
FINISH |
Окончание работы |
||
|
FIND |
Группа операций, |
||
|
GET |
Передача найденного |
||
|
STORE |
Помещение в |
||
|
CONNECT |
Включение текущей |
||
|
DISCONNECT |
Исключение текущей |
||
|
MODIFY |
Обновление текущей |
||
|
ERASE |
Удаление экземпляра |
||
В рабочей
области пользователя хранятся шаблоны записей, программные переменные и три
типа указателей текущего состояния:
- текущая запись процесса
(код или ключ последней записи, с которой работала данная программа); - текущая запись типа
записи (для каждого типа записи ключ последней записи, с которой работала
программа); - текущая запись типа
набор (для каждого набора с владельцем Т1 и членом Т2 указывается, Т1 или
Т2 были последней обрабатываемой записью).
На рис. 3.7
представлена концептуальная модель торгово-посреднической организации.
Рис.
3.7. Схема БД «Торговая фирма»
При необходимости
возможно описание элементов данных, которые не принадлежат непосредственно данной
записи, но при ее обработке часто используются. Для этого используется тип VIRTUAL
с обязательным указанием источника данного элемента данных.
RECORD Цены
02 Цена TYPE
REAL
02 Товар VIRTUAL
SOURCE IS Товары.НаименованиеТовара
OF OWNER OF
Товар-Цены SET
Наиболее
интересна операция поиска (FIND), так как именно она отражает суть навигационных
методов, применяемых в сетевой модели. Всего существует семь типов операций
поиска:
- По ключу (запись должна
быть описана через CALC USING …):FIND <Имя записи>
RECORD BY CALC KEY <Имя параметра> - Последовательный просмотр
записей данного типа:FIND DUPLICATE <Имя
записи> RECORD BY CALC KEY - Найти владельца текущего
экземпляра набора:FIND OWNER OF CURRENT
<Имя набора> SET - Последовательный просмотр
записей—членов текущего экземпляра набора:FIND (FIRST | NEXT) <Имя
записи> RECORD IN CURRENT <Имя набора> SET - Просмотр записей—членов
экземпляра набора, специфицированных рядом нолей:FIND <Имя
записи> RECORD IN CURRENT <Имя набора> SET USING <Список полей> - Сделать текущей записью
процесса текущий экземпляр набора:FIND CURRENT OF <Имя
набора> SET - Установить текущую
запись процесса:FIND CURRENT OF <Имя
записи> RECORD
Например,
алгоритм и программа печати заказов, сделанных Петровым, будут выглядеть так:
ФИО = "Петров" FIND Люди RECORD BY CALC KEY FIND FIRST Заказы RECORD IN CURRENT Люди-Заказы SET WHILE NOT FAIL DO FIND OWNER OF CURRENT Товары-Заказы SET GET Товары PRINT НаимТовара FIND NEXT Заказы RECORD IN CURRENT Люди-Заказы SET END
к алгоритмизации
алгоритмы, струкутуры данных и программирование
СУБД
ЯиМП
3GL
4GL
5GL
технологии прогр.
Знаете ли Вы, что любой разумный человек скажет, что не может быть улыбки без кота и дыма без огня, что-то там, в космосе, должно быть, теплое, излучающее ЭМ-волны, соответствующее температуре 2.7ºК. Действительно, наблюдаемое космическое микроволновое излучение (CMB) есть тепловое излучение частиц эфира, имеющих температуру 2.7ºK. Еще в начале ХХ века великие химики и физики Д. И. Менделеев и Вальтер Нернст предсказали, что такое излучение (температура) должно обнаруживаться в космосе. В 1933 году проф. Эрих Регенер из Штуттгарта с помощью стратосферных зондов измерил эту температуру. Его измерения дали 2.8ºK — практически точное современное значение. Подробнее читайте в FAQ по эфирной физике.
НОВОСТИ ФОРУМАРыцари теории эфира |
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
Внешние модели
При работе
с иерархической моделью каждая программа, пользователь или приложение определяет
свою внешнюю модель. Внешняя модель представляет собой совокупность поддеревьев
для физических баз данных, с которыми работает данный пользователь. Каждый подграф
внешней модели в обязательном порядке должен содержать корневой тип сегмента
соответствующей физической базы данных концептуальной модели.
Представление
внешней модели называется логической базой данных и определяется совокупностью
блоков связи данного приложения с физическими БД, входящими в концептуальную
схему БД. Блок связи — РСВ, program communication bloc — описывает связь
с одной физической БД по следующим правилам:
DBD NAME = <
имя логической БД (подсхемы)> , ACCESS = LOGICAL
DATA SET = LOGICAL.
SEGM NAME =
<имя сегмента в подсхеме>,
PARENT =<имя
родительского сегмента в подсхеме>,
SOURSE =(Имя
соответствующего сегмента ФБД. имя ФБД)
DBDGEN
FINISH
END
Совокупность
блоков РСВ образует полное внешнее представление данного приложения, называемое
«блоком спецификации программ» (PSB, program specification block).
Рассмотрим
пример иерархической БД.
Наша организация
занимается производством и продажей компьютеров, в рамках производства мы комплектуем
компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько
базовых моделей, которые мы продаем без предварительных заказов по наличию на
складе. В организации существуют несколько филиалов (рис. 3.4) и несколько складов,
на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции.

Рис.
3.4. Физическая БД «Филиалы»
Какие задачи
нам надо решать в ходе разработки приложения?
- При приеме заказа
мы должны выяснить, какую модель заказывает заказчик: типичную или индивидуальную
комплектацию. - Если заказывается типичная
модель, то выясняется, какая модель и есть ли она в наличии, если модель есть,
то надо уменьшить количество компьютеров данной модели в данном филиале на
покупаемое количество. На этом будем считать заказ выполненным, однако при
оформлении заказа может потребоваться задание полной спецификации покупаемого
изделия. - Если заказывается индивидуальная
модель, то требуется описать весь состав новой модели.
Для того
чтобы можно было бы принимать заказы на индивидуальные модели, нам понадобится
информация о наличие конкретных деталей на складе, в этом случае нам необходимо
второе дерево — Склады (см. рис. 3.5).

Рис.
3.5. Физическая модель «Склады»
Ключи в БД
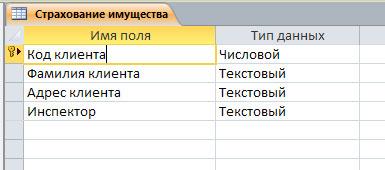
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.
Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:
Итак, наша база данных фактически готова. Схематично она выглядит так:
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.