Кодировка текста ascii (windows 1251, cp866, koi8-r) и юникод (utf 8, 16, 32)
Содержание:
- Why is it important?
- C0 Controls
- Кодировки стандарта UNICODE
- Принципы работы
- Неправильная кодировка результатов из базы данных MySQL
- Важность кодировки
- Переход к Unicode
- Неправильная кодировка HTML страниц
- Структура URL
- Резюме
- История создания
- Кодировки на основе Unicode
- Группа значений атрибута NAME
- Базы банных
- Range: Decimal 688-767. Hex 02B0-02FF.
- Range: Decimal 768-879. Hex 0300-036F.
- Is it a ranking factor for SEO?
- Немного теории
- description (краткое описание)
- keywords (ключевые слова)
Why is it important?
When you think of the fact that every single time text is transmitted, it needs to be encoded in a specific charset and decoded on the other side, the importance of charset is quite obvious. This means that without proper character coding, a browser will display garbage text because it simply does not understand what is being put into it and has to make a quick uninformed guess.
It is also important in html forms because when you input text into text boxes on sites or social media platforms, it has to be encoded carefully. If this information is unavailable for any reason, the incorrect mapping could lead to the loss of vital information.
What a character set does is to provide a key to unlock and crack a code that passes between the user and the website.
It is a set of structured mappings between the bytes in the computer and the characters in the character set. If this key is missing, the data looks like written garbage. This means that when you input text through a keyboard, the character set links the characters you choose to specific bytes in computer memory, and then to display the text it reads the bytes back into the characters.
C0 Controls
The control characters were originally designed to control
hardware devices.
Control characters (except horizontal tab, carriage return, and line feed)
have nothing to do inside an HTML document.
| Char | Dec | Hex | Description |
|---|---|---|---|
| NUL | 0000 | null character | |
| SOH | 1 | 0001 | start of header |
| STX | 2 | 0002 | start of text |
| ETX | 3 | 0003 | end of text |
| EOT | 4 | 0004 | end of transmission |
| ENQ | 5 | 0005 | enquiry |
| ACK | 6 | 0006 | acknowledge |
| BEL | 7 | 0007 | bell (ring) |
| BS | 8 | 0008 | backspace |
| HT | 9 | 0009 | horizontal tab |
| LF | 10 | 000A | line feed |
| VT | 11 | 000B | vertical tab |
| FF | 12 | 000C | form feed |
| CR | 13 | 000D | carriage return |
| SO | 14 | 000E | shift out |
| SI | 15 | 000F | shift in |
| DLE | 16 | 0010 | data link escape |
| DC1 | 17 | 0011 | device control 1 |
| DC2 | 18 | 0012 | device control 2 |
| DC3 | 19 | 0013 | device control 3 |
| DC4 | 20 | 0014 | device control 4 |
| NAK | 21 | 0015 | negative acknowledge |
| SYN | 22 | 0016 | synchronize |
| ETB | 23 | 0017 | end transmission block |
| CAN | 24 | 0018 | cancel |
| EM | 25 | 0019 | end of medium |
| SUB | 26 | 001A | substitute |
| ESC | 27 | 001B | escape |
| FS | 28 | 001C | file separator |
| GS | 29 | 001D | group separator |
| RS | 30 | 001E | record separator |
| US | 31 | 001F | unit separator |
| DEL | 127 | 007F | delete (rubout) |
❮ Previous
Next ❯
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы
Кодирование URL
Принципы работы
UTF-8 является лишь представлением Unicode в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом (Латинский алфавит, простейшие знаки препинания и арабские цифры), а так как в Unicode они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII.
Символы с кодами от:
- 128 — 2-мя байтами.(Кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит, сирийское письмо, некоторые знаки препинания).
- 2048 — 3-мя байтами (Все другие современные формы письменности, сложные знаки препинания; математические и другие специальные символы).
- 65536 — 4-мя байтами (Музыкальные символы, смайлы, редкие китайские иероглифы, вымершие формы письменности).
5 и 6 байтов не используется в Unicode.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Важность кодировки
Поскольку кодирование и декодирование входной строки зависит от формата, мы должны быть осторожны при этих операциях. Если мы используем неправильный формат, это приведет к неправильному выводу и может вызвать ошибки.
Первое декодирование неверно, так как оно пытается декодировать входную строку, которая закодирована в формате UTF-8. Второй правильный, поскольку форматы кодирования и декодирования совпадают.
a = 'This is a bit möre cömplex sentence.'
print('Original string:', a)
# Encoding in UTF-8
encoded_bytes = a.encode('utf-8', 'replace')
# Trying to decode via ASCII, which is incorrect
decoded_incorrect = encoded_bytes.decode('ascii', 'replace')
decoded_correct = encoded_bytes.decode('utf-8', 'replace')
print('Incorrectly Decoded string:', decoded_incorrect)
print('Correctly Decoded string:', decoded_correct)
Вывод
Original string: This is a bit möre cömplex sentence. Incorrectly Decoded string: This is a bit m��re c��mplex sentence. Correctly Decoded string: This is a bit möre cömplex sentence.
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Структура URL
Изначально локатор URL был разработан как система для максимально естественного указания на местонахождение определенного ресурса в сети. URL должен был быть легко расширяемым и использовать лишь ограниченный набор символов ASCII (к примеру, пробел никогда не применяется в URL). В связи с этим, возникла следующая традиционная форма записи URL-адреса:
- схема — определяет тип интернет-сервиса (наиболее распространенным является HTTP или HTTPS)
- логин — имя пользователя, используемое для доступа к ресурсу
- пароль — пароль указанного пользователя
- хост — полностью прописанное доменное имя хоста в системе DNS или IP-адрес хоста в форме четырёх групп десятичных чисел, разделённых точками (например, wm-school.ru)
- порт — определяет номер порта на хосте (по умолчанию для HTTP является 80)
- URL-путь — определяет путь на сервере (если пропущен: корневой каталог сайта)
- параметры — строка запроса с передаваемыми на сервер (методом GET) параметрами. Начинается с символа , разделитель параметров — знак . Пример:
- якорь — идентификатор «якоря» с предшествующим символом диез . Якорем может быть указан заголовок внутри документа или атрибут id элемента. По такой ссылке браузер откроет страницу и переместит окно к указанному элементу. Например, ссылка на этот раздел статьи: .
Стандарт URL использует набор символов ASCII.
Кодирование в URL заменяет небезопасные символы ASCII на символ «%» и следующие две шестнадцатеричные цифры соответствующего значения в наборе символов ISO-8859-1.
C момента своего изобретения и по сей день стандарт URL обладает серьёзным недостатком — в нём можно использовать только ограниченный набор символов: латинские буквы, цифры и лишь некоторые знаки пунктуации. Все другие символы необходимо перекодировать.
Например, перекодироваться должны буквы кириллицы, буквы с диакритическими знаками, лигатуры, иероглифы.
Перекодирующая кодировка называется URL-encoding, URLencoded или percent‐encoding.
URL-адреса не могут содержать пробелы. Кодирование URL-адрес, как правило заменяет каждый пробел знаком плюс (+), или %20. Символы кириллицы URL кодирование заменяет на соответствующие комбинации % и код символа.
Например, строка вида:
кодируется как:
Преобразование происходит в два этапа: сначала каждый символ кириллицы кодируется в UTF-8 в последовательность из двух байтов, а затем каждый байт этой последовательности записывается в шестнадцатеричном представлении с предшествующим знаком процента (%):
К → D0 и 9C → %d0%9a о → D0 и B8 → %d0%be д → D0 и BA → %d0%b4 и → D1 и 80 → %d0%b8, и т. д.
URL-коды символов UTF-8 представлены в Таблице URL кодов символов UTF-8
URL-коды специальных управляющих символов таблицы ASCII (диапазон 00-31, плюс 127), символов ISO-Latin (диапазон 128-255), зарезервированных символов (знак доллара, амперсанд, плюс, слэш, двоеточие, точка с запятой, знак равенства, знак вопроса, знак эт (собака)), небезопасных символов (пробел, кавычки, знак меньше, знак больше, знак диез, знак проценты, фигурные скобки, прямой слэш, обратный слэш, тильда, квдратные скобки, гравис) представлены в Таблице символов кодирования URL
Резюме
- Кодировка — это соответствие между визуальными символами и числами.
- Кодировки необходимы, так как компьютеры созданы для работы с числами и не понимают текст.
- До 1990-х годов не существовало единой кодировки, это приводило к тому, что текст, написанный в одной кодировке, становится совершенно нечитаемым на других.
- Unicode — единый стандарт кодирования символов. Развитие интернета и необходимость обмена большим количеством текстовой информации приводило к тому, что сейчас все пользуются этим стандартом.
- UTF-8, UTF-16, UTF-32 и т.п. — это варианты кодировок, основанные на Unicode. Отличаются они тем, что по-разному хранят информацию.
- UTF-8 — самая популярная кодировка. Особенность её в том, что самые популярные символы кодируются 1-2 байтами, а редко встречающиеся занимают 3-4 байта. Это приводит к существенной экономии памяти, например, при работе с английским текстом.
Ильнар Шафигуллин
История создания
До появления Unicode UTF-8 широко использовались другие кодировки (ASCII, ISO/IEC 646, ISO/IEC 8859, KOI8, Windows-125x).
Впервые кодировка UTF-8 была официально представлена на конференции USENIX в Сан Диего в январе 1993. От других мультибайтных кодировок ее отличала полная совместимость с ASCII: все символы ASCII в UTF-8 кодируются 7 битами. Каждый символ кодировки, отличный от ASCII, состоит из ведущего байта, указывающего длину последовательности, и одного или нескольких продолжающих байт. Такой принцип позволяет определить длину последовательности только по первому байту. Коды символов ASCII, ведущих и продолжающих байт не пересекаются, что позволяет легко найти начало последовательности простым откатом назад максимум на пять байт.
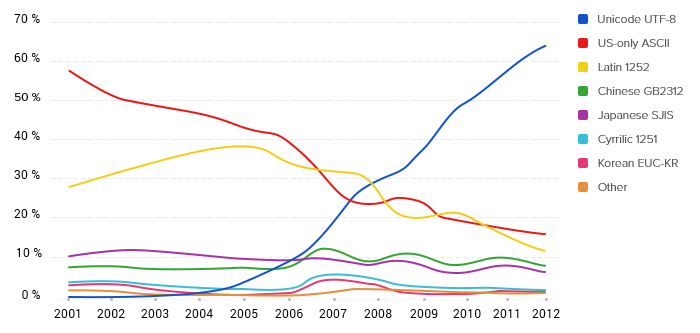 График изменения популярности кодировок в интернете
График изменения популярности кодировок в интернете
В ноябре 2003 года стандартом RFC-3629 максимальная длина последовательности UTF-8 была ограничена четырьмя байтами, однако потенциально UTF-8 позволяет использовать последовательности вплоть до шести байт.
На сегодняшний день самой распространенной кодировкой является UTF-8. Она включает в себя более двух миллионов символов: все возможные современные алфавиты, цифры, знаки препинания, математические и специальные символы, музыкальные знаки и символы вымерших форм письменности. А резерва UTF-8 хватит для размещения более двух миллиардов символов. Так что о смене кодировки в ближайшее время задумываться не придётся.
Однако торжество современных технологий — явление относительно новое. Согласно Google, самой распространенной в интернете кодировкой UTF-8 стала только в 2008 году — тогда ее использовали чуть более чем 25% проиндексированных веб-страниц. А еще в 2006 UTF-8 использовали менее чем 10% веб-страниц.
Стремительный рост популярности кодировки UTF-8 связан с целым рядом ее преимуществ перед предшественницами.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Группа значений атрибута NAME
«keywords» (ключевые слова)
Keywords поисковые системы используют для того, чтобы определить релевантность страницы тому или иному запросу. При формировании данного значения необходимо использовать только те слова, которые обязательно встречаются в самом документе. Использование тех слов, которых нет на странице, не рекомендуется. Ключевые слова нужно добавлять по одному, через запятую, в единственном числе. Рекомендованное количество слов в «keywords» — не более десяти. Кроме того, выявлено, что разбивка этого значения на несколько строк влияет на оценку ссылки поисковыми машинами. Некоторые поисковые системы не индексируют сайты, в которых в значении «keywords» повторяется одно и то же слово для увеличения позиции в списке результатов.
Если раньше «keywords» имел определённую роль в ранжировании сайта, то в последнее время поисковые системы относятся к нему нейтрально.
HTML-код с «keywords»:
«description» (описание страницы)
Description используется при создании краткого описания конкретной страницы Вашего сайта. Практически все поисковые системы учитывают его при индексации, а также при создании аннотации в выдаче по запросу. При отсутствии «description» поисковые системы выдают в аннотации первую строку документа или отрывок, содержащий ключевые слова. Отображается после ссылки при поиске страниц в поисковике, поэтому желательно не просто указывать краткое описание документа, но сделать его содержание привлекательным рекламным сообщением.
Таким образом, правильный description обязательно должен содержать ключевое слово, коротко и точно описывать то, о чём данная веб-страница. «Description» вместе с «title» образуют очень важную пару значений, от которых зависит то, перейдёт пользователь из поисковой выдачи на веб-страницу или нет! Поэтому «description» и «title» нужно прописывать для каждой веб-страницы!
HTML-код с «description»:
«Author» и «Copyright»
Эти значения, как правило, не используются одновременно. Функция author и copyright — идентификация автора или принадлежности контента на странице. «Author» содержит имя автора веб-страницы, но в случае, если веб-сайт принадлежит какой-либо организации, целесообразнее использовать значение «Copyright».
HTML-код с «author»:
«Robots»
Robots — формирует информацию о гипертекстовых документах, которая поступает к роботам поисковых систем.
У «robots» могут быть следующие значения:
- index — страница должна быть проиндексирована;
- noindex — страница не индексируется;
- follow — гиперссылки на странице учитываются;
- nofollow — гиперссылки на странице не учитываются
- all — включает значения index и follow, включен по умолчанию;
- none — включает значения noindex и nofollow.
HTML-код с «robots»:
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Range: Decimal 688-767. Hex 02B0-02FF.
If you want any of these characters displayed in HTML, you can use the HTML entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec) or hexadecimal (hex) reference.
Will display as:
I will display a
I will display ʰ
I will display aʰ
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| ʰ | 688 | 02B0 | MODIFIER LETTER SMALL H | |
| ʱ | 689 | 02B1 | MODIFIER LETTER SMALL H WITH HOOK | |
| ʲ | 690 | 02B2 | MODIFIER LETTER SMALL J | |
| ʳ | 691 | 02B3 | MODIFIER LETTER SMALL R | |
| ʴ | 692 | 02B4 | MODIFIER LETTER SMALL TURNED R | |
| ʵ | 693 | 02B5 | MODIFIER LETTER SMALL TURNED R WITH HOOK | |
| ʶ | 694 | 02B6 | MODIFIER LETTER SMALL CAPITAL INVERTED R | |
| ʷ | 695 | 02B7 | MODIFIER LETTER SMALL W | |
| ʸ | 696 | 02B8 | MODIFIER LETTER SMALL Y | |
| ʹ | 697 | 02B9 | MODIFIER LETTER PRIME | |
| ʺ | 698 | 02BA | MODIFIER LETTER DOUBLE PRIME | |
| ʻ | 699 | 02BB | MODIFIER LETTER TURNED COMMA | |
| ʼ | 700 | 02BC | MODIFIER LETTER APOSTROPHE | |
| ʽ | 701 | 02BD | MODIFIER LETTER REVERSED COMMA | |
| ʾ | 702 | 02BE | MODIFIER LETTER RIGHT HALF RING | |
| ʿ | 703 | 02BF | MODIFIER LETTER LEFT HALF RING | |
| ˀ | 704 | 02C0 | MODIFIER LETTER GLOTTAL STOP | |
| ˁ | 705 | 02C1 | MODIFIER LETTER REVERSED GLOTTAL STOP | |
| ˂ | 706 | 02C2 | MODIFIER LETTER LEFT ARROWHEAD | |
| ˃ | 707 | 02C3 | MODIFIER LETTER RIGHT ARROWHEAD | |
| ˄ | 708 | 02C4 | MODIFIER LETTER UP ARROWHEAD | |
| ˅ | 709 | 02C5 | MODIFIER LETTER DOWN ARROWHEAD | |
| ˆ | 710 | 02C6 | ˆ | MODIFIER LETTER CIRCUMFLEX ACCENT |
| ˇ | 711 | 02C7 | CARON | |
| ˈ | 712 | 02C8 | MODIFIER LETTER VERTICAL LINE | |
| ˉ | 713 | 02C9 | MODIFIER LETTER MACRON | |
| ˊ | 714 | 02CA | MODIFIER LETTER ACUTE ACCENT | |
| ˋ | 715 | 02CB | MODIFIER LETTER GRAVE ACCENT | |
| ˌ | 716 | 02CC | MODIFIER LETTER LOW VERTICAL LINE | |
| ˍ | 717 | 02CD | MODIFIER LETTER LOW MACRON | |
| ˎ | 718 | 02CE | MODIFIER LETTER LOW GRAVE ACCENT | |
| ˏ | 719 | 02CF | MODIFIER LETTER LOW ACUTE ACCENT | |
| ː | 720 | 02D0 | MODIFIER LETTER TRIANGULAR COLON | |
| ˑ | 721 | 02D1 | MODIFIER LETTER HALF TRIANGULAR COLON | |
| ˒ | 722 | 02D2 | MODIFIER LETTER CENTRED RIGHT HALF RING | |
| ˓ | 723 | 02D3 | MODIFIER LETTER CENTRED LEFT HALF RING | |
| ˔ | 724 | 02D4 | MODIFIER LETTER UP TACK | |
| ˕ | 725 | 02D5 | MODIFIER LETTER DOWN TACK | |
| ˖ | 726 | 02D6 | MODIFIER LETTER PLUS SIGN | |
| ˗ | 727 | 02D7 | MODIFIER LETTER MINUS SIGN | |
| ˘ | 728 | 02D8 | BREVE | |
| ˙ | 729 | 02D9 | DOT ABOVE | |
| ˚ | 730 | 02DA | RING ABOVE | |
| ˛ | 731 | 02DB | OGONEK | |
| ˜ | 732 | 02DC | ˜ | SMALL TILDE |
| ˝ | 733 | 02DD | DOUBLE ACUTE ACCENT | |
| ˞ | 734 | 02DE | MODIFIER LETTER RHOTIC HOOK | |
| ˟ | 735 | 02DF | MODIFIER LETTER CROSS ACCENT | |
| ˠ | 736 | 02E0 | MODIFIER LETTER SMALL GAMMA | |
| ˡ | 737 | 02E1 | MODIFIER LETTER SMALL L | |
| ˢ | 738 | 02E2 | MODIFIER LETTER SMALL S | |
| ˣ | 739 | 02E3 | MODIFIER LETTER SMALL X | |
| ˤ | 740 | 02E4 | MODIFIER LETTER SMALL REVERSED GLOTTAL STOP | |
| ˥ | 741 | 02E5 | MODIFIER LETTER EXTRA-HIGH TONE BAR | |
| ˦ | 742 | 02E6 | MODIFIER LETTER HIGH TONE BAR | |
| ˧ | 743 | 02E7 | MODIFIER LETTER MID TONE BAR | |
| ˨ | 744 | 02E8 | MODIFIER LETTER LOW TONE BAR | |
| ˩ | 745 | 02E9 | MODIFIER LETTER EXTRA-LOW TONE BAR | |
| ˪ | 746 | 02EA | MODIFIER LETTER YIN DEPARTING TONE MARK | |
| ˫ | 747 | 02EB | MODIFIER LETTER YANG DEPARTING TONE MARK | |
| ˬ | 748 | 02EC | MODIFIER LETTER VOICING | |
| ˭ | 749 | 02ED | MODIFIER LETTER UNASPIRATED | |
| ˮ | 750 | 02EE | MODIFIER LETTER DOUBLE APOSTROPHE | |
| ˯ | 751 | 02EF | MODIFIER LETTER LOW DOWN ARROWHEAD | |
| ˰ | 752 | 02F0 | MODIFIER LETTER LOW UP ARROWHEAD | |
| ˱ | 753 | 02F1 | MODIFIER LETTER LOW LEFT ARROWHEAD | |
| ˲ | 754 | 02F2 | MODIFIER LETTER LOW RIGHT ARROWHEAD | |
| ˳ | 755 | 02F3 | MODIFIER LETTER LOW RING | |
| ˴ | 756 | 02F4 | MODIFIER LETTER MIDDLE GRAVE ACCENT | |
| ˵ | 757 | 02F5 | MODIFIER LETTER MIDDLE DOUBLE GRAVE ACCENT | |
| ˶ | 758 | 02F6 | MODIFIER LETTER MIDDLE DOUBLE ACUTE ACCENT | |
| ˷ | 759 | 02F7 | MODIFIER LETTER LOW TILDE | |
| ˸ | 760 | 02F8 | MODIFIER LETTER RAISED COLON | |
| ˹ | 761 | 02F9 | MODIFIER LETTER BEGIN HIGH TONE | |
| ˺ | 762 | 02FA | MODIFIER LETTER END HIGH TONE | |
| ˻ | 763 | 02FB | MODIFIER LETTER BEGIN LOW TONE | |
| ˼ | 764 | 02FC | MODIFIER LETTER END LOW TONE | |
| ˽ | 765 | 02FD | MODIFIER LETTER SHELF | |
| ˾ | 766 | 02FE | MODIFIER LETTER OPEN SHELF | |
| ˿ | 767 | 02FF | MODIFIER LETTER LOW LEFT ARROW |
❮ Previous
Next ❯
Range: Decimal 768-879. Hex 0300-036F.
If you want any of these characters displayed in HTML, you can use the HTML entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec) or hexadecimal (hex) reference.
Will display as:
I will display a
I will display ̃
I will display ã
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| ò | 768 | 0300 | GRAVE ACCENT | |
| ó | 769 | 0301 | ACUTE ACCENT | |
| ô | 770 | 0302 | CIRCUMFLEX ACCENT | |
| õ | 771 | 0303 | TILDE | |
| ō | 772 | 0304 | MACRON | |
| o̅ | 773 | 0305 | OVERLINE | |
| ŏ | 774 | 0306 | BREVE | |
| ȯ | 775 | 0307 | DOT ABOVE | |
| ö | 776 | 0308 | DIAERESIS | |
| ỏ | 777 | 0309 | HOOK ABOVE | |
| o̊ | 778 | 030A | RING ABOVE | |
| ő | 779 | 030B | DOUBLE ACUTE ACCENT | |
| ǒ | 780 | 030C | CARON | |
| o̍ | 781 | 030D | VERTICAL LINE ABOVE | |
| o̎ | 782 | 030E | DOUBLE VERTICAL LINE ABOVE | |
| ȍ | 783 | 030F | DOUBLE GRAVE ACCENT | |
| o̐ | 784 | 0310 | CANDRABINDU | |
| ȏ | 785 | 0311 | INVERTED BREVE | |
| o̒ | 786 | 0312 | TURNED COMMA ABOVE | |
| o̓ | 787 | 0313 | COMMA ABOVE | |
| o̔ | 788 | 0314 | REVERSED COMMA ABOVE | |
| o̕ | 789 | 0315 | COMMA ABOVE RIGHT | |
| o̖ | 790 | 0316 | GRAVE ACCENT BELOW | |
| o̗ | 791 | 0317 | ACUTE ACCENT BELOW | |
| o̘ | 792 | 0318 | LEFT TACK BELOW | |
| o̙ | 793 | 0319 | RIGHT TACK BELOW | |
| o̚ | 794 | 031A | LEFT ANGLE ABOVE | |
| ơ | 795 | 031B | HORN | |
| o̜ | 796 | 031C | LEFT HALF RING BELOW | |
| o̝ | 797 | 031D | UP TACK BELOW | |
| o̞ | 798 | 031E | DOWN TACK BELOW | |
| o̟ | 799 | 031F | PLUS SIGN BELOW | |
| o̠ | 800 | 0320 | MINUS SIGN BELOW | |
| o̡ | 801 | 0321 | PALATALIZED HOOK BELOW | |
| o̢ | 802 | 0322 | RETROFLEX HOOK BELOW | |
| ọ | 803 | 0323 | DOT BELOW | |
| o̤ | 804 | 0324 | DIAERESIS BELOW | |
| o̥ | 805 | 0325 | RING BELOW | |
| o̦ | 806 | 0326 | COMMA BELOW | |
| o̧ | 807 | 0327 | CEDILLA | |
| ǫ | 808 | 0328 | OGONEK | |
| o̩ | 809 | 0329 | VERTICAL LINE BELOW | |
| o̪ | 810 | 032A | BRIDGE BELOW | |
| o̫ | 811 | 032B | INVERTED DOUBLE ARCH BELOW | |
| o̬ | 812 | 032C | CARON BELOW | |
| o̭ | 813 | 032D | CIRCUMFLEX ACCENT BELOW | |
| o̮ | 814 | 032E | BREVE BELOW | |
| o̯ | 815 | 032F | INVERTED BREVE BELOW | |
| o̰ | 816 | 0330 | TILDE BELOW | |
| o̱ | 817 | 0331 | MACRON BELOW | |
| o̲ | 818 | 0332 | LOW LINE | |
| o̳ | 819 | 0333 | DOUBLE LOW LINE | |
| o̴ | 820 | 0334 | TILDE OVERLAY | |
| o̵ | 821 | 0335 | SHORT STROKE OVERLAY | |
| o̶ | 822 | 0336 | LONG STROKE OVERLAY | |
| o̷ | 823 | 0337 | SHORT SOLIDUS OVERLAY | |
| o̸ | 824 | 0338 | LONG SOLIDUS OVERLAY | |
| o̹ | 825 | 0339 | RIGHT HALF RING BELOW | |
| o̺ | 826 | 033A | INVERTED BRIDGE BELOW | |
| o̻ | 827 | 033B | SQUARE BELOW | |
| o̼ | 828 | 033C | SEAGULL BELOW | |
| o̽ | 829 | 033D | X ABOVE | |
| o̾ | 830 | 033E | VERTICAL TILDE | |
| o̿ | 831 | 033F | DOUBLE OVERLINE | |
| ò | 832 | 0340 | GRAVE TONE MARK | |
| ó | 833 | 0341 | ACUTE TONE MARK | |
| o͂ | 834 | 0342 | GREEK PERISPOMENI (combined with theta) | |
| o̓ | 835 | 0343 | GREEK KORONIS (combined with theta) | |
| ö́ | 836 | 0344 | GREEK DIALYTIKA TONOS (combined with theta) | |
| oͅ | 837 | 0345 | GREEK YPOGEGRAMMENI (combined with theta) | |
| o͆ | 838 | 0346 | BRIDGE ABOVE | |
| o͇ | 839 | 0347 | EQUALS SIGN BELOW | |
| o͈ | 840 | 0348 | DOUBLE VERTICAL LINE BELOW | |
| o͉ | 841 | 0349 | LEFT ANGLE BELOW | |
| o͊ | 842 | 034A | NOT TILDE ABOVE | |
| o͋ | 843 | 034B | HOMOTHETIC ABOVE | |
| o͌ | 844 | 034C | ALMOST EQUAL TO ABOVE | |
| o͍ | 845 | 034D | LEFT RIGHT ARROW BELOW | |
| o͎ | 846 | 034E | UPWARDS ARROW BELOW | |
| o͏ | 847 | 034F | GRAPHEME JOINER | |
| o͐ | 848 | 0350 | RIGHT ARROWHEAD ABOVE | |
| o͑ | 849 | 0351 | LEFT HALF RING ABOVE | |
| o͒ | 850 | 0352 | FERMATA | |
| o͓ | 851 | 0353 | X BELOW | |
| o͔ | 852 | 0354 | LEFT ARROWHEAD BELOW | |
| o͕ | 853 | 0355 | RIGHT ARROWHEAD BELOW | |
| o͖ | 854 | 0356 | RIGHT ARROWHEAD AND UP ARROWHEAD BELOW | |
| o͗ | 855 | 0357 | RIGHT HALF RING ABOVE | |
| o͘ | 856 | 0358 | DOT ABOVE RIGHT | |
| o͙ | 857 | 0359 | ASTERISK BELOW | |
| o͚ | 858 | 035A | DOUBLE RING BELOW | |
| o͛ | 859 | 035B | ZIGZAG ABOVE | |
| ͜o | 860 | 035C | DOUBLE BREVE BELOW | |
| ͝o | 861 | 035D | DOUBLE BREVE | |
| ͞o | 862 | 035E | DOUBLE MACRON | |
| ͟o | 863 | 035F | DOUBLE MACRON BELOW | |
| ͠o | 864 | 0360 | DOUBLE TILDE | |
| ͡o | 865 | 0361 | DOUBLE INVERTED BREVE | |
| ͢o | 866 | 0362 | DOUBLE RIGHTWARDS ARROW BELOW | |
| oͣ | 867 | 0363 | LATIN SMALL LETTER A | |
| oͤ | 868 | 0364 | LATIN SMALL LETTER E | |
| oͥ | 869 | 0365 | LATIN SMALL LETTER I | |
| oͦ | 870 | 0366 | LATIN SMALL LETTER O | |
| oͧ | 871 | 0367 | LATIN SMALL LETTER U | |
| oͨ | 872 | 0368 | LATIN SMALL LETTER C | |
| oͩ | 873 | 0369 | LATIN SMALL LETTER D | |
| oͪ | 874 | 036A | LATIN SMALL LETTER H | |
| oͫ | 875 | 036B | LATIN SMALL LETTER M | |
| oͬ | 876 | 036C | LATIN SMALL LETTER R | |
| oͭ | 877 | 036D | LATIN SMALL LETTER T | |
| oͮ | 878 | 036E | LATIN SMALL LETTER V | |
| oͯ | 879 | 036F | LATIN SMALL LETTER X |
❮ Previous
Next ❯
Is it a ranking factor for SEO?
The character set is not a ranking factor for search engine optimization. Most search engines focus on the important goal of delivering relevant, useful content to those who seek it and as such does not consider other outside factors that do not contribute to that goal.
So your character set matters because of how you transmit information but search engines are not interested in it. Using other charsets apart from Utf-8 will not decrease your SEO ranking because to a large extent it doesn’t matter what character encoding you use as long as the search engine is able to get information to the end users.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
description (краткое описание)
Значение description используется для краткого описания содержимого, расположенного на текущей странице. Рекомендуемая максимальная длина такого описания не должна превышать 180 символов:
<meta name="description" content="Описание содержимого на данной странице">
Краткое описание страницы может быть использовано поисковыми система на странице с результатами поиска под названием страницы и URL-адреса:
Также краткое описание используется на сайтах некоторых соцсетей, при добавлении ссылки:
При составлении краткого описания следует учитывать следующие моменты:
- в описании нужно указывать именно ту информацию, которая отражает содержимое, опубликованное на данной странице;
- описание должно быть уникальным и не должно повторяться для разных страниц;
- старайтесь в описание страницы также включать необходимые ключевые слова, которые будут учитываться в поисковых запросах.
Примечание: краткое описание, расположенное под ссылкой на странице с результатами поиска, называется сниппетом.
keywords (ключевые слова)
У любого сайта есть набор ключевых слов и словосочетаний, по которым поисковые системы ищут нужные ресурсы в сети. Именно эти слова и должны составлять содержимое keywords.
Самый простой способ подобрать нужные ключевые слова для текущей страницы — это определить по каким словам вы сами стали бы искать материал, представленный на ней? Вот это и будут нужные ключевые слова. Пример:
<meta name="keywords" content="мета тег, meta, метаданные, keywords, description">
Ключевые слова указываются через запятую или пробел и могут быть написаны в любом регистре. Рекомендуется указывать не более 10-15 ключевых слов или словосочетаний.
В настоящее время поисковые системы стали более продвинутые и определяют категорию, к которой относится информация, по содержимому веб-страницы, а ключевые слова отошли на второй план или полностью игнорируются.














