Как озвучить любой текст: онлайн-сервисы и программы
Содержание:
- Популярные голосовые движки
- Библиотека pyttsx3
- Управляем речью через Speech Dispatcher в Linux
- ПК синтезаторы
- Голосовые движки: мужские и женские
- Онлайн сервисы озвучивания текстов
- Решение от Voximplant
- Текст в аудио онлайн бесплатно, переводим apihost.ru
- Онлайн-сервисы для озвучивания
- Мобильные приложения
- Acapela — бесплатная программа по озвучке текста
- Синтезатор речи Google для озвучки текста
- Готовим поляну
- Преимущества и недостатки продукта от Google
Популярные голосовые движки
Звучание голоса в синтезаторе речи зависит от того, какой в нем используется движок. Например, в русских версиях Windows установлен “электронный диктор” Microsoft Irina. Если в синтезаторе речи нет другого движка, то по умолчанию будет говорить именно она. При этом выбор голосов на самом деле очень богатый. Среди популярных русских движков можно выделить:
- Alyona от Acapela Group
- Татьяна и Максим от Ivona
- Ольга и Дмитрий от Loquendo
- Милена, Катерина и Юрий от Nuance
- Николай от Speech Cube Elan
Движки отличаются тембром голоса, эмоциональной окраской, количеством встроенных словарей, которые определяют правильность речи. Например, Николай читает текст практически без эмоций, поэтому с ним сложно воспринимать художественные тексты, а Ольга и Дмитрий от Loquendo, наоборот, используют разные стили речи. Все перечисленные движки работают по стандарту SAPI 5, который применяется на Windows, начиная с версии XP.
Большинство движков представлены в двух вариантах — мужской и женский голос. Детских голосов мало. Даже на сайте Acapela Group, одного из лидеров индустрии, меньше 10 языков, для которых доступны голоса детей.
Как сказано выше, голосовые движки облегчают процесс изучения иностранных языков. Например, Lernout&Hauspie предлагает для этого бесплатные голоса с американским и британским акцентами английского,а также голландским, испанским, итальянским и другим произношением. Большое количество движков разработала компания Cepstral. У них также есть бесплатная версия электронного диктора, однако при ее использовании постоянно появляется окно с предложением перейти на платный тариф.
Несмотря на то, что голосовые движки становятся всё более технологичными, добиться 100% совпадения с живой человеческой речью не удалось пока никому. Вам достаточно услышать несколько предложений, чтобы понять, что говорит робот. При изучении иностранных слов не стоит полагаться только на произношение программ — они нередко ошибаются. Но если ваша задача — простое озвучивание информации на русском, то можно использовать любой движок, в базе которого есть этот язык.
Чтобы добавить голосовой движок в Windows, достаточно его скачать и установить как обычную программу. После этого он появится в списке доступных. Но для использования голосов необходима сторонняя программа или веб-сервис, так как сами движки не имеют графического интерфейса.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
import pyttsx3
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
voices = tts.getProperty(‘voices’)
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘=======’)
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:

В Linux картина будет похожей, но с другими идентификаторами.

Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
import pyttsx3
tts = pyttsx3.init()
voices = tts.getProperty(‘voices’)
# Задать голос по умолчанию
tts.setProperty(‘voice’, ‘ru’)
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
tts.runAndWait()
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait(). Выбор голоса по ID
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
tts.setProperty(‘voice’, voice.id)
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС
Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
tts = pyttsx3.init()
EN_VOICE_ID = «HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\MS-Anna-1033-20DSK»
RU_VOICE_ID = «HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\TokenEnums\RHVoice\Anna»
# Использовать английский голос
tts.setProperty(‘voice’, EN_VOICE_ID)
tts.say(«Can you hear me say it’s a lovely day?»)
# Теперь — русский
tts.setProperty(‘voice’, RU_VOICE_ID)
tts.say(«А напоследок я скажу»)
tts.runAndWait()
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
import speechd
tts_d = speechd.SSIPClient(‘test’)
tts_d.set_output_module(‘rhvoice’)
tts_d.set_language(‘ru’)
tts_d.set_rate(50)
tts_d.set_punctuation(speechd.PunctuationMode.SOME)
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
tts_d.close()
Ура! Наконец-то наше Linux-приложение говорит голосом, похожим на человеческий
Обратите внимание на метод .set_output_module() — он позволяет выбрать любой установленный движок, будь то espeak, rhvoice или festival. После этого синтезатор прочтет текст голосом, предписанным для данного движка по умолчанию
Если задан только язык — голосом по умолчанию для данного языка.
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
import platform
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
print(system)
print(bit)
Пример результата:
Windows
64bit
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
ПК синтезаторы
Robot Talk
Бесплатное приложение магазина Windows. В программе всего 5 голосов: 3 мужских и 2 женских. Можно изменять тембр голоса и скорость речи. Полученный на выходе аудиофайл можно сохранить.
Балаболка
Умная и непривередливая программа, которая читает тексты практически любых форматов – DOC, PDF, PPTX, XLS и многих других. Для озвучки используются движки синтезаторов речи, которые уже присутствуют в вашем компьютере. Помимо распознавания текста в речь, софт предлагает проверку орфографии. По окончании работы аудиофайл можно экспортировать.
Говорилка
Словари произношений в этой программе постоянно пополняются, поэтому орфоэпических ошибок можно не бояться. Считывает текстовые файлы и прокручивает текст на экране, как телевизионный суфлер. Ограничений по объему текстов нет, поэтому это отличный вариант для тех, кто предпочитает аудиокниги электронным: достаточно загрузить книгу в программу – и можно слушать.
2nd Speech Center
Предельно понятный интерфейс и все та же возможность экспорта файла в MP3 и WAV. Программа поддерживает файлы в формате TXT, DOC, PDF, EML, RTF, HTM, HTML. Можно регулировать скорость получившегося текста – удобно, чтобы послушать учебные материалы на иностранном языке.
Голосовые движки: мужские и женские
Движки синтеза речи — это специальное ПО, своего рода драйвера, необходимые для того, чтобы компьютер мог «заговорить» (т.е. для преобразования текста в речь). Движков сейчас в сети сотни: есть как платные, так и бесплатные. Наилучшее качество чтения, конечно же, показывают платные движки.
Важное замечание: движок синтеза речи не имеет никакого дизайна или интерфейса. После его установки в систему — вы не заметите ровным счетом никаких изменений! Чтобы работать с движком — вам нужна какая-нибудь программа для чтения текстов: Балаболка, Говорун, Ice Reader и пр., чуть выше я приводил те, которые «мне по душе» )
Вот поэтому, кстати, часто пользователи ругают ту или иную программу, что она не может прочитать русский текст (или вообще не может). Просто они забывают о необходимости установки речевого движка.
Пару слов про стандарты…
Голосовые движки могут быть выполнены в разных стандартах (так называемых), самые основные три: SAPI 4, SAPI 5 или Microsoft Speech Platform (примечание: почти в каждой программе для чтения, вы можете выбрать речевой движок).
SAPI 4
Добротный стандарт, был актуален десяток лет назад. На сегодняшний день устарел, и на современных компьютерах/ноутбуках его использование не оправдано.
SAPI 5
Почти все современные голосовые движки построены на этом стандарте (как платные, так и бесплатные). Наиболее популярный стандарт, можно найти движок с мужским, женским, детским голосами.
Microsoft Speech Platform
Microsoft Speech Platform – большой набор инструментов для разработчиков, которые позволяют реализовывать возможность преобразования текста в речь.
это набор инструментов, позволяющих разработчикам различных приложений, реализовывать в них возможность преобразования текста в голос.
Примечание! Чтобы синтезатор речи работал, необходимо:
Microsoft Speech Platform — Runtime – серверная часть платформы, предоставляющая API для программ;
Microsoft Speech Platform — Runtime Languages – языки для работы серверной части.
Более подробно об этом здесь — https://msdn.microsoft.com/en-us/library/hh361572.aspx
Несколько голосовых движков
Тext-to-speech engines Дигало // Николай
Сайт: http://www.digalo.com/index.htm
Очень популярный русский голосовой движок (голос мужской!). Подойдет для большинства программ, которые умеют читать текст голосом. На мой скромный взгляд, один из лучших общедоступных движков для синтеза речи (на русском языке). Кроме русского, кстати, на сайте разработчика доступны движки еще для нескольких языков. Минус: без регистрации работает всего две недели.
Acapela // Голосовой движок (модуль) Алена
Сайт: http://www.acapela-group.com/
Алёнка — относительно новый русский женский речевой движок от компании Acapela. Работает по стандарту SAPI-5 с частотой 22 КГц. Некоторые пользователи считают, что голос у «Алены» приятнее, чем у «Николая».
Голосовой движок (модуль) Катерина 2
Компания разработчик: ScanSoft RealSpeak
Довольно неплохой речевой движок с женским голосом. После доработки движка, он стал сопоставим с «Николаем». Существенному обновлению подверглась фонетическая база движка, изменен алгоритм постановки ударений (что положительно сказалось на звучании), устранена проблема со скоростью произношения.
RHVoice
Сайт: http://tiflo.info/rhvoice/
RHVoice — это многоязычный синтезатор речи с открытым исходным кодом. Можно использовать в ОС Windows и Linux. Синтезатор совместим с SAPI5. Разработчик синтезатора — Ольга Яковлева.
Кстати, движок основан на речевой базе, записанной дикторами. Русские голоса «Елена» и «Ирина» доступны для скачивания на официальном сайте.
IVONA Tatyana/Maxim
Сайт: https://www.ivona.com/us/about-us/voice-portfolio/
Станет ли движок самым используемым — не знаю, время покажет!
Кстати, как думаете, будет ли когда-нибудь разработан речевой движок, который не отличишь от голоса обычного человека? Или может он уже есть, а я о нем не слышал… (скиньте название!)
Онлайн сервисы озвучивания текстов
В сети можно найти десятки различных онлайн сервисов для озвучивания текстов. Большинство их них иностранные, но встречаются и русские. Лидерство в этой области нужно отдать двум монстрам: Яндексу и Google. Именно они дальше всех продвинулись в области технологии TTS – text-to-speech.
Убедиться в этом можно, открыв онлайн переводчики этих сайтов. Озвучка введенного в окно переводчика текста производится нажатием на значок динамика. И, кстати, делается это с очень неплохим качеством, хотя имеются и ограничения по длине введенного текста:
- для Google – 5 000 знаков;
- для Яндекса – 10 000 знаков.
онлайн синтезаторы речи
Имеется также масса иностранных платных онлайн сервисов, предоставляющих услуги перевода текстовых файлов в звуковые:
- Acapela;
- IVONA;
- Naturalreaders;
- Linguatec;
- Ispeech и другие.
Большинство из них озвучивает текст на русском довольно качественно, хотя и с характерными ошибками в ударениях и ритмике речи. Бесплатная озвучка фраз ограничивается 200-500 знаками.
Решение от Voximplant
Voximplant предоставляет API, позволяющий легко интегрировать функциональность TTS в свое приложение или веб-сайт. Компании используют TTS для обработки входящих и исходящих вызовов, а также для управления голосовыми уведомлениями, при этом не требуется никакого оборудования или сложного программирования.
Voximplant поддерживает TTS на базе таких сервисов, как Amazon Polly, Google WaveNet, Dialogflow, IBM Watson, Яндекс SpeechKit, Tinkoff VoiceKit и Microsoft Azure. WaveNet также используется онлайн-сервисами Google: Google Assistant, Google Search и Google Translate. WaveNet генерирует необработанные аудиосигналы с помощью нейронной сети, обученной на большом количестве речевых образцов. Вся необходимая информация для генерации речи хранится в параметрах модели, а тон голоса можно контролировать с помощью настроек модели.
Особенности решения от Voximplant:
- Многоязычность: широкий охват различных языков, включая американский и британский английский, китайский, арабский и другие.
- Движок WaveNet, который можно использовать для обучения бота в соответствии с потребностями бизнеса.
- Естественные голоса: мужские и женские голоса высокого качества.
Текст в аудио онлайн бесплатно, переводим apihost.ru
Давайте переведем текст в аудио онлайн бесплатно. Для этого перейдите на сервис – «apihost.ru». Далее скопируйте из документа текст на 1000 символов и вставьте его в поле на сервисе (скрин 1).
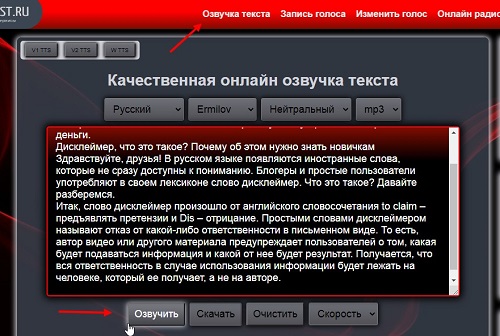
После чего нажмите кнопку «Озвучить», чтобы прослушать голос данного текста.
Основные настройки синтезатора речи онлайн apihost.ru
Рассмотрим основные настройки ресурса Апихост:
- выбор языка для озвучки, например, русский;
- установка мужского или женского голоса;
- тип голосов: нейтральный, дружеский, раздражен;
- настройка форматов для скачивания – mp3 или wav;
- распределение скорости голоса, рекомендуется оставить по умолчанию или 0,9 секунд;
- быстрая очистка поля от текста.
Данные настройки позволяют сделать качественную озвучку текста.
Настройка текста в аудио онлайн бесплатно женским голосом
Когда вставите текст на сервис apihost.ru, кликните на раздел «Ermilov» и выберите из списка женский голос, например, «Oksana» (скрин 2).
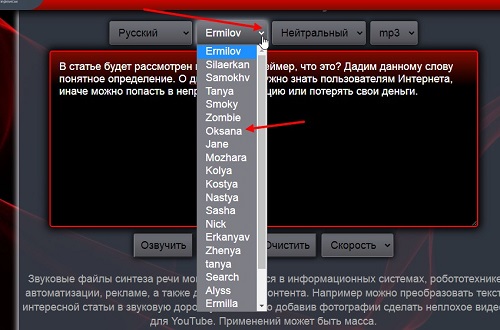
Далее нажмите «Озвучить», чтобы прослушать вставленный текст женским голосом.
Для преобразования текста в аудио мужским голосом, используйте те параметры, которые рассмотрели выше. Только в настройках выбираете мужские имена, например, Kolya, Kostya и другие (скрин 3).
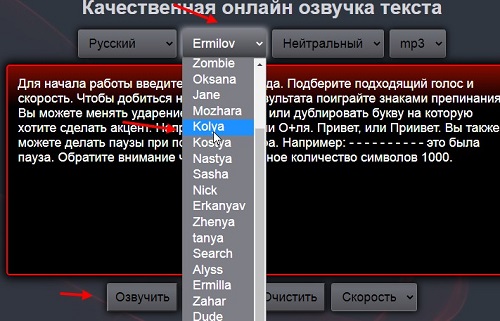
Чтобы прослушать текст мужским голосом, так же нажимаете кнопку озвучки.
Как изменить голос
В некоторых случаях озвученный голосом текст может не подойти. Поэтому, на сервисе apihost.ru предусмотрена функция по изменению голоса.
Нажмите раздел «Изменить голос». Далее кликните красную кнопку «Upload», чтобы загрузить на сервис аудио-файл с компьютера (скрин 4).
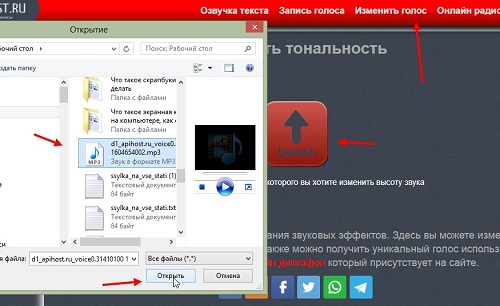
В открывшемся окне можно изменить тональность вашей записи. Удерживая внизу ползунок левой кнопкой мыши, двигайте ей по шкале влево или вправо (скрин 5).
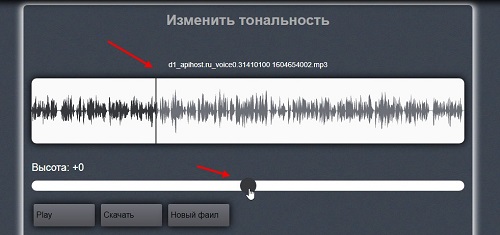
Тем самым вы выберите новые голоса и их установите в аудио-файл. Обработанный файл загрузите на компьютер через кнопку Скачать.
Как скачать аудио, записанное в apihost.ru voice
Записанное аудио на сервисе Апихост легко загружается на компьютер. Если вы уже перевели текст в аудио, отредактировали его, нажмите кнопку внизу «Скачать» (скрин 6).
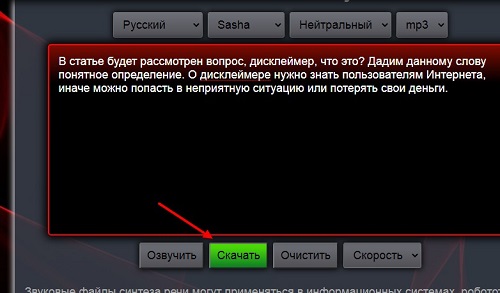
По умолчанию файл скачивается на компьютер в формате mp3, но вы можете изменить значение формата. Наведите на данный формат вверху сервиса и выберите, например, wav. После этого, скачаете аудио в другом формате.
В заключении, разберем еще несколько сервисов и программу, которые переводят текст в аудио:
- ttsdemo.com;
- text-to-speech.imtranslator.net/speech.asp;
- 5btc.ru/voice/;
- программа Говорилка;
- и другие ресурсы.
Перечисленные сервисы и программа работают по похожему принципу, что и сервис Апихост.
Онлайн-сервисы для озвучивания
Acapela
Acapela – это иностранный сервис, способный озвучить текст на 35 языках и диалектах. Примечательно, что портал озвучивает иностранные слова с характерным акцентом (например, русские слова читает англичанин). На сайте представлена демонстрационная версия продукта с ограниченным размером до 300 символов. Еще одним минусом послужит требования каждый раз соглашаться с условиями сайта. Для русской локализации предлагается один вариант озвучки текста – голосовой движок Alyona.
Linguatec
Сервис Linguatec предлагает ознакомиться с демонстрационной версией продукта. Здесь также имеется до 40 вариантов озвучки текста голосом. В сравнении с предыдущим сайтом на Linguatec представлено два голоса: женский «Милена» и мужской «Юрий». Ограничение на количество символом в демо-версии 250 знаков.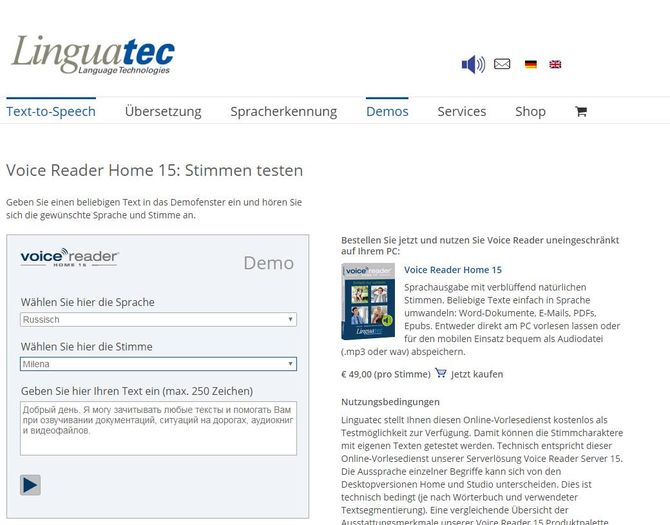
Text-to-Speech
Text-to-Speech – еще один портал, способный озвучить текст голосом онлайн. Обладает более продвинутыми настройками: скорость речи диктора, размер шрифта, машинный перевод. Для людей с ограниченными возможностями предоставлена экранная клавиатура. К сожалению, для русскоговорящего пользователя предоставлен всего один женский голос.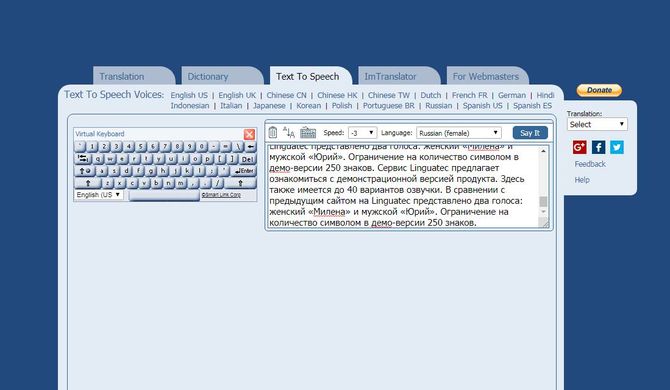
Google Translator
Google Translator – фирменный переводчик от корпорации Google. Одной из функций сервиса является озвучивание переведенного или оригинального предложения. При наличии микрофона можно набирать слова голосом. Если вы желаете сохранить результат перевода и его звуковое сопровождение в «избранные», то авторизуйтесь в Gmail. Сервис Google Translator переводит и озвучивает тексты в пределах 5000 символов. Единственный минус – это голосовой движок, который больше походит на речь робота.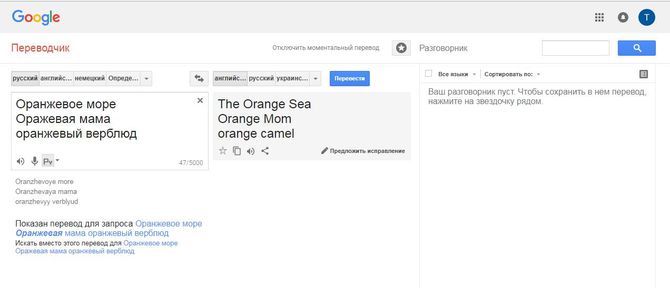
IVONA
Сайт IVONA – это презентационная страница, демонстрирующая голосовые движки. Данный сервис является польской разработкой и предлагает четыре варианта озвучки. Во всех язык по 2-3 голоса. В русском сегменте присутствует два голосовых движка «Максим» и «Татьяна». К сожалению, возможность опробовать сервис бесплатно отсутствует. Единственное, что может пользователь без покупки подписки – прослушать шаблонное приветствие голосовых движков.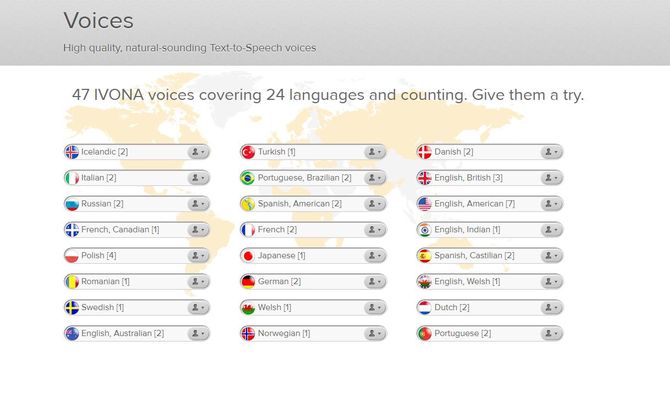
Яндекс переводчик
Яндекс переводчик – отечественный аналог переводчика от Google. Имеет в распоряжении аналогичные инструменты: перевод, озвучивание перевода и генератор голоса, экранная клавиатура и сохранение в избранное. Единственно, что отличает Яндекс переводчик от зарубежного аналога – максимальное количество символов, достигающие отметки в 10 000 знаков.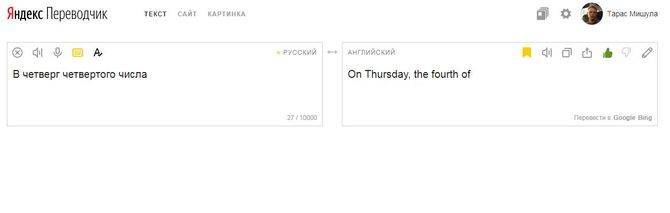
Oddcast
Портал Oddcast – наиболее интересный онлайн синтезатор речи для озвучивания с точки зрения интерфейса. Здесь помимо сухого звука присутствуют анимированные дикторы. Кроме того виртуальные дикторы следят за указателем мышки. Дополнительно на сайте регулируются эффекты речи. Имеется опция частичного изменения звучания. Русский язык в Oddcast представлен тремя движками: «Дмитрий», «Милина» и «Ольга». Из недостатков можно выделить ограничение на максимальное количество символов в 300 знаков и не самый удобный интерфейс для ввода.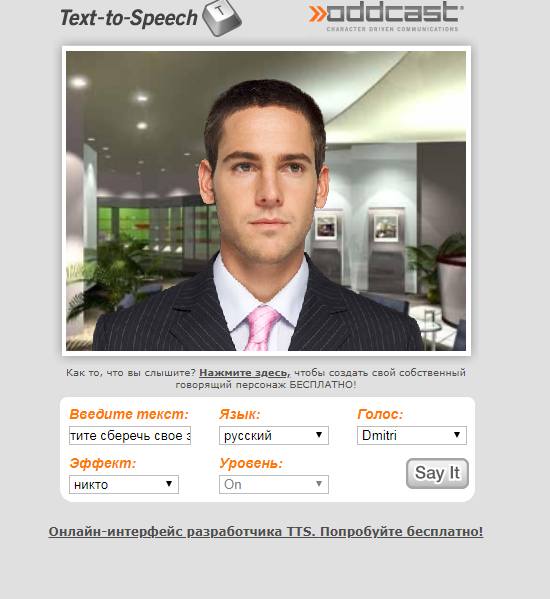
ISpeech
Сайт ISpeech обладает минималистским интерфейсом, с которым разберется даже начинающий пользователь. Все что нужно сделать: ввести пару предложений и выбрать язык. Дополнительно регулируется скорость чтения текста голосом и выбор голосового движка. При желании озвученный результат можно сохранить на ПК. Максимальное число символов – 150.
2уха
2уха – интересный отечественный сайт, где помимо узконаправленного форума имеется раздел по преобразования документа в аудио файл, который записывается в формате mp3 или awb. В настройках перед обработкой запроса настраиваются дополнительные параметры: скорость чтения, высота тона голоса, громкость, тип голосового движка и чтение знаков препинания. Результат конвертации высылается на электронную почту через несколько минут. Рекомендуем пройти авторизацию через социальные сети, чтобы не проходить ввод кода перед отправкой запроса (проверка на робота). Минус портала заключается в невозможность моментально озвучить текст в онлайн режиме.
Мобильные приложения
Перед описанием программ для озвучивания текста на смартфонах и планшетах хотелось бы уточнить одну деталь. Для того чтобы софт работал необходимо загрузить голосов движок Text-To-Speech для мобильных устройств. На новых гаджетах данная функция устанавливается вместе с операционной системой. Для старых устройств потребуется загрузка движка из Play Store. От пользователя нужно вбить их название в Play Store: Google TTS, Acapela, Ivona или SVOX TTS. Вы можете выбрать один из движков или загрузить их все сразу. Представленные движки являются абсолютно бесплатными для android пользователей.
SpeechText
SpeechText – приложение, позволяющее озвучивать введенный текст на любом из доступных языков. При желании библиотека языков расширяется самостоятельно. В SpeechText доступна функция сохранения озвученного текста в аудио формате на карте памяти.
Болтун
Болтун – отечественная программа для воспроизведения речи. Изначально утилита презентовалась, как карманный секретарь, способный записывать или озвучивать мысли. Однако благодаря обновлениям появилась функция перевода и озвучивания текста на многих языках. Дополнительно приложение может читать электронные письма, сообщения и воспроизводить любой выделенный фрагмент.
Речь в Текст — Текст в речь
Представленный мобильный сервис – удобная утилита, обладающая функцией обратной конвертации. Благодаря этой фишке вы можете не только слушать озвученный текстовый документ, но и надиктовать предложение для его преобразования в текст.
Voice Aloud Reader
Voice Aloud Reader – многофункциональная «говорилка», способная озвучивать текст из сторонних android приложений: браузеры, новостные статьи, полученные электронные письма и обрабатывать форматы программа для чтения EPUB, FB2, PDF и другие.
Acapela — бесплатная программа по озвучке текста
Acapela – самый популярный и один из лучших речевых синтезаторов, позволяющих работать в режиме онлайн. Сервис поддерживает более 30 языков, а также большое количество исполнителей на выбор, как мужских, так и женских. Для английского есть аж 20 тембров на выбор – женский, мужской, подросток, ребенок, грубый мужской, мягкий женский и т.д. Программа легко настраивается и проста в использовании. На сайте доступна программа для оффлайн применения. У вас есть возможность попробовать дэмо-версию синтезатора речи, нажав в строке меню соответствующий пункт.
Как пользоваться Acapela
Для настройки синтеза устной речи в режиме онлайн используйте блок с левой стороны на странице http://www.acapela-group.com/voices/demo/.
Итак, как это работает:
- В первой строке выберите язык озвучиваемого текста.
- Вторая строка не понадобиться, если вы выберите русский, потому-как вариант только один – Alyona.
- В третьей строке введите свой текст, который нужно озвучить. Ввести можно до 300 символов.
- Далее согласитесь с правилами сервиса, поставив галочку на пункте «i agree with terms & conditions».
- И нажмите ниже кнопку «Please accept terms & conditions».
Озвучка через данный сервис среднего качества. Интонации практически во всех словах правильные. Продукт доступен для всех платформ.
Синтезатор речи Google для озвучки текста
Приложение от Гугл заранее встраивается во многие телефоны с операционной системой Android. Однако он необязательно ставится в качестве используемого по умолчанию синтезатора. Поэтому пользователь может не догадываться о том, что у него уже есть эта программа.
Как скачать синтезатор Гугл для озвучки различных текстов женским голосом:
-
Зайдите в «Настройки».
Настройки на смартфоне Android
-
Откройте «Специальные возможности».
Нужная клавиша выделена серым
-
Выберите пункт «Синтез речи».
Переход к скачиванию ПО для синтеза речи
-
Нажмите на значок шестеренки.
Переход в дополнительные Настройки
-
Тапните по строчке «Установка голосовых данных».
Клавиша для перехода к загрузке электронных чтецов
-
Выберите язык. Нажмите на символ загрузки, нарисованный в виде направленной вниз стрелки.
Кнопка загрузки
Что делать дальше:
-
Откройте программу TalkBack. Если у вас ее нет, отправляйтесь на Google Play и скачайте ее.
Как перейти к работе с Talkback
-
Тапните на клавишу в правом верхнем углу, чтобы попасть в «Настройки».
Включение и Настройки TalkBack
-
Затем нажмите на «Возобновить работу».
Переход к настройкам вызова Talkback
-
Выберите активацию одним нажатием.
Тумблер для включения быстрого запуска
-
Затем переходите к Управлению жестами и задавайте нужные настройки.
Какие движения или их комбинации могут вызывать диктора
Как преобразовать текст в женский голос с использованием ПО от Google:
- Зайдите на страницу «Язык и Ввод».
- В разделе «Речь» выберите строчку «Преобразование текста».
- Посмотрите, что стоит у вас в графе «Предпочитаемый модуль».
Скачать программу можно с Google Store. Синтезатор речи от Гугла используется для:
- Зачитывания книг из магазина Google Play.
- Озвучивания слов и фраз в Гугл Переводчике.
- В качестве дополнительного синтезатора в приложениях-читалках, выложенных в Google Market.
В такого рода программах озвучку от Гугл нужно обычно устанавливать вручную. Зайдите в настройки приложения и найдите наиболее подходящий вариант.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.
В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
wget http://espeak.sourceforge.net/data/ru_dict-48.zip
unzip ru_dict-48.zip
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64…» или еще что-то. Если не уверены, воспользуйтесь поиском:. find /usr/lib/ -name «espeak-data»
find /usr/lib/ -name «espeak-data»
Готово!
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.
Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
espeak -v ru -f D:\my.txt
espeak-ng -v en «The Cranes are Flying»
echo «Да, это от души. Замечательно. Достойно восхищения» |RHVoice-test -p Aleksandr
Как нетрудно догадаться, первая команда с ключом -f читает русский текст из файла. Чтобы в Windows команда espeak подхватывалась вне зависимости от того, в какой вы директории, добавьте путь к консольной версии eSpeak (по умолчанию — C:\Program Files\eSpeak\command_line) в переменную окружения Path. Вот как это сделать.
Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы
Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух
Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.