Проектирование баз данных
Содержание:
- Хаотическое проектирование баз данных
- Правило 5: Следите за данными, заполненные разделителями
- Правило 3: Не переусердствуйте с правилом 2
- Создание связей между сущностями
- Используйте хотя бы третью нормальную форму
- Литература
- Ключи в БД
- [править] Подходы к проектированию реляционных БД (РБД)
- Анализ требований: определение цели базы данных
- Основные этапы проектирования баз данных
- Проектирование реляционной базы данных. Преобразование модели в реляционную
- Физическое проектирование БД
- Правило 6: Следите за частичными зависимостями
- Azure Data Studio
- Иерархическая база данных — пример
Хаотическое проектирование баз данных
В современной индустрии разработки программного обеспечения устоялось мнение, что определить требования к продукту перед началом проекта невозможно, и поэтому разработка должна быть адаптирована к их постоянному изменению. В результате появились процессы, основанные на итерациях, учитывающих изменение требований, а рефакторинг исходного кода стал неотъемлемой частью создания ПО. А что происходит в процессе итерационной разработки с базами данных? Изменение требований вынуждает корректировать схему базы данных, причем чаще всего это происходит непрозрачно, без анализа общей картины и зависимостей. Таблицы, поля, внешние ключи и ограничения создаются и изменяются хаотически, за ссылочной целостностью никто не следит, и никто не может точно сказать, чем же база данных на итерации N отличается от ее состояния на итерации N-1.
Фактически разработка баз данных сегодня ведется «заплаточным» методом, как во времена господства «водопадного» процесса, – в начале проекта «рисуется» некая модель базы, основанная на частичных требованиях, известных к данному моменту, затем генерируется физическая база данных, а дальше про модель забывают, производя изменения прямо в базе данных. Минусы такого подхода очевидны: обмен знаниями и понимание общей картины затруднены, а изменения непрозрачны, могут порождать противоречия в логике и схеме базы данных, которые останутся нераскрытыми до момента ввода программной системы в эксплуатацию, что приводит к очень большим убыткам. Современные разработчики приложений баз данных нуждаются в инструментах, приспособленных к итерационной разработке баз данных.
Первым и наиболее важным условием такой приспособленности является наличие полноценных возможностей обратного инжиниринга (reverse engineering, создание модели базы данных на основе анализа ее физической схемы) и прямого инжиниринга (forward engineering; создание и изменение физической схемы базы данных на основе модели). На практике это означает, что с помощью инструмента проектирования можно провести анализ схемы существующей базы данных, создать на ее основе модель базы, поменять модель и немедленно применить изменения, которые должны действительно корректно и непротиворечиво изменить схему базы данных, а не испортить или запутать ее.
Итерационный подход также подталкивает нас к необходимости создания подмоделей, связанных с конкретной итерацией. Выделение любых сущностей и их атрибутов в подмодель помогает разделить области ответственности как между разными разработчиками, так и между разными итерациями, гарантируя в то же время общую целостность модели. Естественно, нужна также возможность сравнения двух моделей, причем не в виде SQL-скриптов, а на уровне сущностей и атрибутов, чтобы видеть и полностью понимать вносимые при итерации изменения и их влияние на всю модель.
Разработчики приложений редко работают в одиночку, поэтому нуждаются в средствах совместной работы, но если на стороне разработки приложений с этим все в порядке, то совместная работа над базой данных обычно никак не поддерживается на уровне инструментальных средств. Совместная работа обязательно предполагает систему контроля версий: все версии моделей и физической схемы базы данных должны сохраняться в едином репозитории, обеспечивая возможности отката и сравнения схем с самого начала процесса разработки.
Разработка баз данных — дело не менее важное, чем разработка приложений, поэтому стратегическим направлением развития является обеспечение процесса разработки баз данных средствами контроля версий и управления требованиями, а также явная привязка этапов моделирования и модифицирования баз данных к итерациям и меняющимся требованиям программного проекта. Для решения перечисленных проблем и поддержки современного итерационного процесса разработки баз данных компания Embarcadero предлагает ER/Studio – инструмент проектирования, анализа, обратного и прямого инжиниринга, позволяющий осуществлять контроль версий моделей на базе собственного репозитория
В качестве средства контроля за изменениями метаданных в физических базах данных может использоваться инструмент Change Manager.
Правило 5: Следите за данными, заполненные разделителями
Второе правило 1-й нормальной формы говорит избегать повторения групп. Пример повторяющихся групп отображен на рисунке ниже. Если вы внимательно изучите поле «Syllabus», то увидите, что там слишком много данных. Эти поля называются «Повторяющиеся группы». Если нам нужно манипулировать этими данными, запрос будет сложным, а производительность запросов оставит желать лучшего.
Эти типы столбцов, которые имеют заполненные разделителями данные, нуждаются в особом внимании, и лучшим подходом было бы переместить эти поля в другую таблицу и связать их с ключами для лучшего управления.
Итак, теперь применим второе правило 1-й нормальной формы: «Избегайте повторения групп». Вы можете видеть на приведенном выше рисунке, что мы создали отдельную таблицу учебных планов — Syllabus Table, а затем сделал отношение «многие ко многим» (many-to-many relationship) к таблице предметов — Subject Table.
При таком подходе поле «Syllabus» в основной таблице больше не повторяется и имеет разделители данных.
Правило 3: Не переусердствуйте с правилом 2
Разработчики — люди, зачастую воспринимающие все буквально. Если вы скажете им как нужно делать, они будут делать только так и могут переусердствовать, что может привести к нежелательным последствиям. Это также относится к правилу 2, о котором мы только что говорили выше. Когда вы думаете о декомпозиции, остановитесь и спросите себя, насколько она нужна? Разложение должно быть обдуманным и логичным.
Например,ниже вы видите поле номера телефона. Вряд ли вы часто будете использовать коды ISD для телефонных номеров отдельно (пока ваша заявка не потребует этого). Поэтому было бы разумным решением не разбивать его, поскольку это может привести к большему количеству осложнений.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
1:1
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
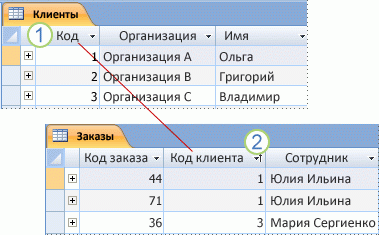
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
1:Mодной1
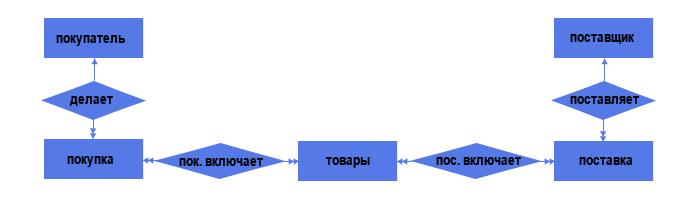
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
один-ко-многим
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
один не может существовать без другого
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Используйте хотя бы третью нормальную форму
Нормальные формы — это требования, которые должны соблюдаться при правильной проектировке базы данных.
Интенсив «Профессия Data Scientist: учимся обработке и анализу данных за 3 дня»
26–28 апреля, Онлайн, Беcплатно
tproger.ru
События и курсы на tproger.ru
Нормальных форм существует целых 6 штук, однако обычно соблюдают всего лишь 3 и для начала этого более чем достаточно.
Первая нормальная форма
Для примера будем использовать отношение сотрудники_отделы_проекты. В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.
Это отношение, как и любое другое, автоматически находится в первой нормальной форме:
- в отношении нет одинаковых кортежей;
- кортежи не упорядочены;
- атрибуты не упорядочены и различаются по наименованию;
- все значения атрибутов атомарны.
Вторая нормальная форма
В нашем случае у таблицы выше имеется сложный (составной) ключ . От части ключа зависят неключевые атрибуты , , . От части ключа зависит неключевой атрибут . А вот атрибут зависит от всего составного ключа, так как сотрудник может выполнять одно задание в одном проекте.
Поэтому для приведения отношения ко второй нормальной форме из отношения сотрудники_отделы_проекты нужно выделить два отношения сотрудники_отделы и проекты, а исходное отношение оставим отношением задания.
Наконец, третья нормальная форма
Отношение находится в третьей нормальной форме, когда отношение находится во второй нормальной форме и все неключевые атрибуты взаимно независимы.
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения ещё на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение сотрудники_отделы не находится в третьей нормальной форме, так как имеется зависимость неключевых атрибутов, таких как зависимость номера телефона от номера отдела. Поэтому декомпозируем отношение сотрудники_отделы на два отношения — сотрудники и отделы:
Литература
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4.
- Когаловский М.Р. Перспективные технологии информационных систем. — М.: ДМК Пресс; Компания АйТи, 2003. — 288 с. — ISBN 5-279-02276-4.
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: «Вильямс», 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс. — М.: «Вильямс», 2003. — 1088 с. — ISBN 5-8459-0384-X.
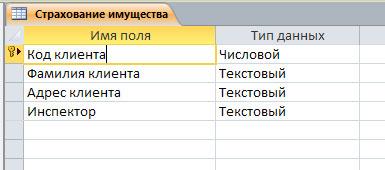
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.
Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:
Итак, наша база данных фактически готова. Схематично она выглядит так:
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
[править] Подходы к проектированию реляционных БД (РБД)
Первый подход (предложен Э. Коддом) основан на понятии «универсального отношения», то есть таблицы, состоящей из всех атрибутов предметной области (ПО). В дальнейшем такая таблица разбивается путем декомпозиции на несколько взаимосвязанных нормализованных таблиц. В результате на этапе концептуального проектирования создается реляционная схема БД.
Второй подход (объектный подход) основан на создании концептуальной модели данных, состоящей из описания объектов ПО и связей между ними. Затем эта модель преобразуется в реляционную модель. Процесс преобразования автоматически гарантирует получение нормализованной реляционной схемы БД.
Анализ требований: определение цели базы данных
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД.
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных (включая физические и цифровые файлы).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Клиенты
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
Товары
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
Заказы
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД. Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД.
Основные этапы проектирования баз данных
Концептуальное (инфологическое) проектирование

Пример концептуальной схемы
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные .
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование
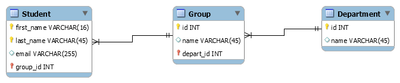
Пример логической схемы для реляционной модели данных.
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Физическое проектирование
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.
Результатом физического проектирования логической схемы выше на языке SQL может являться следующий скрипт:
CREATE TABLE IF NOT EXISTS Department ( -- Факультет
id INT NOT NULL,
name VARCHAR(45),
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS Group (
id INT NOT NULL,
name VARCHAR(45) ,
depart_id INT NOT NULL,
UNIQUE INDEX depart_id_UNIQUE (depart_id ASC),
PRIMARY KEY (id, depart_id),
CONSTRAINT depart_fk
FOREIGN KEY (depart_id)
REFERENCES Department (id)
);
CREATE TABLE IF NOT EXISTS Student (
first_name VARCHAR(16) NOT NULL,
last_name VARCHAR(45) NOT NULL,
email VARCHAR(255),
group_id INT NOT NULL,
PRIMARY KEY (last_name, first_name, group_id),
INDEX group_fk_idx (group_id ASC),
CONSTRAINT group_fk
FOREIGN KEY (group_id) REFERENCES Group (id)
);
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
— построение набора предварительных таблиц;
— указание РК;
— выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:
Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
— 1-й нормальной формы (1НФ);
— 2НФ;
— 3НФ;
— НФБК (нормальной формы Бойса-Кодда);
— 4НФ;
— 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии
Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Физическое проектирование БД
На следующем этапе физического проектирования БД логическая структура отображается в виде структуры хранения БД, то есть увязывается с такой физической средой хранения, где данные будут размещены максимально эффективно. Здесь детально расписывается схема данных с указанием всех типов, полей, размеров и ограничений. Помимо разработки индексов и таблиц, производится определение основных запросов.
Построение физической модели сопряжено с решением во многом противоречивых задач:
- задачи минимизации места хранения данных,
- задачи достижения целостности, безопасности и максимальной производительности.
Вторая задача вступает в конфликт с первой, поскольку, например:
- для эффективного функционирования транзакций нужно резервировать дисковое место под временные объекты,
- для увеличения скорости поиска нужно создавать индексы, число которых определяется числом всех возможных комбинаций участвующих в поиске полей,
- для восстановления данных будут создаваться резервные копии базы данных и вестись журнал всех изменений.
Всё это увеличивает размер базы данных, поэтому проектировщик ищет разумный баланс, при котором задачи решаются оптимально путём грамотного размещения данных в пространстве памяти, но не за счёт средств защиты базы дынных, куда входит как защита от несанкционированного доступа, так и защита от сбоев.
Для завершения создания физической модели проводят оценку её эксплуатационных характеристик (скорость поиска, эффективность выполнения запросов и расхода ресурсов, правильность операций). Иногда этот этап, как и этапы реализации базы данных, тестирования и оптимизации, а также сопровождения и эксплуатации, выносят за пределы непосредственного проектирования БД.
Правило 6: Следите за частичными зависимостями
Следите за полями, которые частично зависят от первичных ключей. Например, в приведенной выше таблице мы видим, что первичный ключ создается с номером и стандартом. Теперь внимательно посмотрите на поле «Syllabus»: оно связано со стандартом, а не со студентом напрямую (roll number).
Учебный план (syllabus) связан со стандартом, по которому учится студент, а не непосредственно со студентом. Поэтому, если завтра мы хотим обновить учебный план, мы должны обновить ее для каждого учащегося, что кропотливо и нелогично. Имеет смысл перемещать эти поля и связывать их со стандартной таблицей.
Посмотрите, как мы переместили поле Syllabus и привязали его к таблице стандартов.
Это правило не что иное, как 2-я нормальная форма: «Все ключи должны зависеть от полного первичного ключа, а не частично».
Azure Data Studio
Azure Data Studio – это бесплатный, кроссплатформенный инструмент с открытым исходным кодом для работы с базами данных Microsoft SQL Server.
Azure Data Studio основана на Visual Studio Code и ориентирована на SQL разработчиков, так как основное назначение Azure Data Studio – это написание, редактирование и выполнение SQL запросов, иными словами, это редактор SQL кода.
Azure Data Studio позволяет работать с базами данных Microsoft SQL Server, SQL Azure, а также с другими СУБД, например, с PostgreSQL
Основные особенности
Инструмент бесплатный
Кроссплатформенность (поддержка Windows, Linux, macOS)
Ориентация на SQL разработчиков
Продвинутый SQL редактор (технология IntelliSense, фрагменты SQL кода)
Расширяемость (встроенная поддержка расширений)
Работа с другими СУБД
Встроенная возможность выгрузки данных в формат Excel, XML, JSON, CSV
Группировка подключений к серверам
Визуализация данных с помощью диаграмм и графиков
Поддержка нескольких цветовых тем
Встроенный терминал (Bash, PowerShell, sqlcmd)
Записные книжки
Недостатки
Отсутствует конструктор таблиц
Нет функционала для работы со свойствами объектов
Отсутствует возможность управления безопасностью
Отсутствует возможность импорта и экспорта DACPAC
Отсутствует функционал для большинства задач администрирования
Мне нравится2Не нравится
Иерархическая база данных — пример
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.