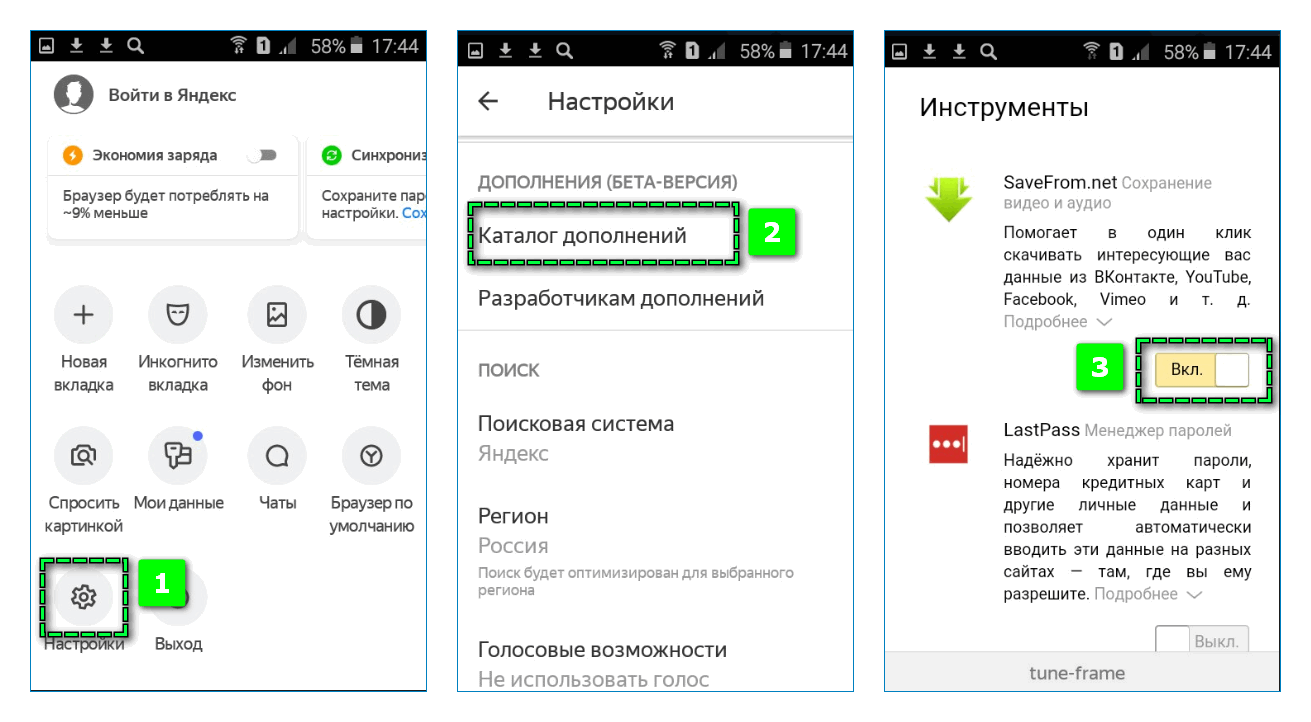
Парсеры яндекса
Содержание:
- Маркерные запросы
- Сбор частот
- LEN — считаем количество символов в ячейке
- Как правильно настроить Словоеб
- REGEXEXTRACT — извлекаем нужный текст из ячеек
- IF — базовая логическая функция
- Пошаговый алгоритм работы с сервисом:
- Виды парсеров по сферам применения
- Как поисковик формирует подсказки
- Чек-лист по выбору парсера
- Как создать семантическое ядро?
- Как попасть в ТОП подсказок
- Доступные парсера Яндекса:
- Метод перемножения
- Парсинг вопросов-ответов в результатах поиска
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:
Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:
Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам
Как найти маркерные запросы?
Вариант №1: можно получить поисковые запросы из Яндекс Метрики. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?
Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т.е. логических гипотез
Важно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Сбор частот
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
LEN — считаем количество символов в ячейке
Эта функция особенно полезна при составлении объявлений контекстной рекламы — когда важно не заступать за отведенное количество символов для заголовков, описаний, отображаемых URL, быстрых ссылок и уточнений
В SEO функция LEN применяется, например, при составлении мета-тегов title и description. Символы функция считает с пробелами.
Синтаксис:
Пример. Нам нужно составить тайтлы для всех страниц сайта. Мы знаем, что в результатах поиска отображается около 55 символов. Наша задача — составить тайтлы так, чтобы самая важная информация была в первых 55 символах. Прописываем формулу LEN для заполняемых ячеек. Теперь мы точно знаем, когда приближаемся к отображаемым 55 символам.
Как правильно настроить Словоеб
Основные инструменты
При помощи программы Словоеб можно:
- Осуществить пакетный подбор слов используя правую и левую колонку Yandex.Wordstat. Можно данные действия провести и вручную, зайдя на сайт статистики поисковых запросов Яндекс, но это довольно долго и не весьма удобно, лучше использовать данную программу.
- Осуществить пакетный подбор слов используя Rambler. Adstat. Возможность аналогична с 1 пунктов, только на основании данных статистики запросов поисковика Rambler. Я эти возможности не использую, мне вполне хватает данных Яндекса.
- Определить конкурентность по данному запросу. Тут всё просто, чем выше конкурентность данного запроса, тем сложней его продвинуть и войти по нему в ТОП по поисковой выдаче.
- Определить релевантные страницы по данному запросу в Яндекс и Google. Программа поможет определить релевантную страницу по каждому ключевому запросу и место в выдаче Яндекса и Google по вашему КС. К примеру, если я ранее подбирал ключевые слова и написал под них заметку, то через время можно проверить, есть ли в выдаче основных поисковиков мой сайт по данным запросам.
- Проверить сезонность поисковых запросов, определить KEI (Keyword Effectiveness Index (KEI) — оценка ключевого слова, выраженная в цифровом значении, дающая представление о его эффективности, с точки зрения поискового продвижения). Эти возможности считаю дополнительными и использую редко))
Вот, в принципе, все возможности программы, рекомендую всем, кто пишет статьи, использовать её возможности. Это поможет вам правильно подбирать ключевые фразы и слова и использовать их грамотно в теле заметки. Подробно о том, как правильно писать статьи, рекомендую почитать:
Где скачать программу Словоеб и Key Collektor
Как всегда, рекомендую вам скачивать софт с официальных сайтов разработчика
Скачать бесплатную программу Словоеб и Key Collektor можно тут — http://seom.info/tools/
На странице ищите нужную вам программу и скачивайте самую актуальную версию.
После того, как программу скачаете, распакуйте архив, запускайте программу файлом Slovoeb, после чего нужно внести корректные настройки и данные своих аккаунтов Яндекс и Рамблер, чтобы была возможность парсить запросы.
Настройка программы Словоеб
Любой инструмент для корректной работы необходимо правильно настроить, будь то пианино или софт для вебмастера
После запуска программы находим слева вверху иконку в виде шестеренки (настройки) и переходим в эту вкладку.
Мы пройдёмся детально только по первому разделу «Парсинг», про остальные расскажу коротко, они не столь важны.
Парсинг => Общие
Настройки, которые я выделил на скриншоте выше желтым, вам необходимо сверить со своими. Дело в том, что по умолчанию, с выходом обновлений программы эти цифры могут изменяться. Я выбрал оптимальные и предлагаю вам выбрать такие же параметры, если у вас своё мнение, пожалуйста, выбирайте те цифры, которые для вас являются оптимальными, не возражаю ))
Парсинг=> Yandex.Wordstat
Тут настройки я также слегка подкорректировал и выставил следующие:
Я установил минимальное значение «фразы с частотностью» не менее 25, поскольку для ключевых слов менее 25 писать заметки не стоит, не будет результата и трафика))
Парсинг=> Yandex.Direct
Далее 3 подраздела главы «Парсинг» я пропускаю ( Rambler, поисковая выдача и подсказки) и обращаю ваше внимание на то, что необходимо обязательно внести данные своего аккаунта Яндекс в последний подраздел/
Настоятельно вам рекомендую создать новый аккаунт в Директ и внести его данные в настройках программы Словоеб. Внесите данные название аккаунта и пароль к нему через двоеточие-
логин: пароль
Внимание!
Если вы установили программу на новый ПК, то пароль и логин делайте
новый! Программа не будет работать с одним логином Яндекса на разных
устройствах! У меня на рабочем компе одни логин и пароль, на другом
другие данные Яндекса. Теперь ваша программа готова к обработке данных)) Если у вас часто выскакивает капча при работе программы и вам лень ее вводить ручками, можете воспользоваться сервисами, которые это сделают за вас (раздел настроек «Антикапча») Меня «капча» особо не беспокоит, поэтому я справляюсь сам, без помощи подобных сервисов
Теперь ваша программа готова к обработке данных)) Если у вас часто выскакивает капча при работе программы и вам лень ее вводить ручками, можете воспользоваться сервисами, которые это сделают за вас (раздел настроек «Антикапча») Меня «капча» особо не беспокоит, поэтому я справляюсь сам, без помощи подобных сервисов.
Также можно убрать при помощи настроек лишние колонки (я Рамблером не использую, мне Яндекса вполне хватает), изменить шрифт в программе (я размер на 14 выставил) и прочие мелочи, но это уже каждый сам сможет сделать.
REGEXEXTRACT — извлекаем нужный текст из ячеек
Эта функция позволяет извлечь из строки с данными текст, описанный с помощью регулярных выражений RE2, поддерживаемых Google. Синтаксис регулярных выражений достаточно сложный, больше примеров вы найдете в справке Google.
Синтаксис:
Пример 1. У нас есть список URL. Нужно извлечь домены. Здесь нам поможет регулярное выражение:
Пример 2. В списке ключевых фраз нужно найти брендированные ключи со словами «porta» и «порта». Для поиска фраз с вхождением любого из этих слов используем регулярное выражение:
Как видите, в таблицах можно кроить и резать данные так, как вам будет нужно, достаточно разобраться в формулах.
IF — базовая логическая функция
Это одна из базовых функций, знакомых вам по Excel. Она помогает при решении разных SEO-задач. Формула IF выводит одно значение, если логическое выражение истинное, и другое — если оно ложное.
Синтаксис:
Пример. Есть список ключей с частотностями. Наша цель — занять ТОП-3. При этом мы хотим выбрать только такие ключи, каждый из которых приведет нам минимум 300 посетителей в месяц.
Определяем, какая доля трафика приходится на третью позицию в органике. Для этого идем в этот сервис и видим, что третья позиция приводит около 10% трафика из органики (конечно, эта цифра неточная, но это лучше, чем ничего).
Составляем выражение IF, которое будет возвращать значение 1 для ключей, который приведут минимум 300 посетителей, и 0 — для остальных ключей:
Обратите внимание, в строке 7 формула выдала ошибку, поскольку значение частотности задано в неверном формате. Для подобных ситуаций есть продвинутая версия функции IF — IFERROR
Обратите внимание: использование в формуле запятой или точки для десятичных дробей определено в настройках ваших таблиц
Пошаговый алгоритм работы с сервисом:
- Создание задачи. Чтобы создать задачи, необходимо перейти во вкладку сбор подсказок и нажать «Создать новую задчу»
-
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задач (обязательное поле). Можно ввести любое название, часто бывает удобно вводить название сайта, чтобы в будущем легко найти нужную задачу.
Далее мы указываем источник подсказок. Можно выбрать Яндекс и / или Google.
Если выбрать сбор подсказок только поисковой системы «Яндекс» — вы получите результаты в 10-15 раз быстрее. -
Шаг второй: Настройки сбора
Далее нажимаем кнопку «Следующий шаг» и переходим в «Настройки сбора».
Необходимо настроить правила сбора подсказок. Ключевое слово — система соберет подсказки по Вашему ключевому слову.Ключевое слово + пробел — система соберет подсказки по вашему ключевому слову, добавив перед ним пробел.Ключевое слово + -после подстановки пробела, система поочередно подставит все буквы английского алфавита и соберет все доступные подсказки.Ключевое слово + — после подстановки пробела, система поочередно подставит все буквы русского алфавита и соберет все доступные подсказки.Ключевое слово + — после подстановки пробела, система поочередно подставит все цифры и соберет все доступные подсказки.Глубина парсинга- если Вы выберите глубину парсинга 2 и более – после сбора всех подсказок по Вашим ключевым словам, система соберет подсказки по всем новым ключевым словам(подсказкам, полученным на первом уровне). -
Шаг третий: «Ключевые слова и цена».Загружаем списком либо файлом.
Поддерживаемые форматы: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку.Вводим стоп-слова
Рекомендуем ознакомиться с материалом о том: Как составить список стоп-слов для сбора семантики?
Если в процессе сбора система встретит подсказки, содержащие стоп-слова — такие подсказки будут исключены из списка, а дальнейший сбор подсказок по этой ветке производиться не будет. Функционал стоп слов помогает сэкономить бюджет на сбор данных и решает проблему ручной очистки мусора.
Мы подобрали для Вас большой список с гео запросами, а так же стоп слова по разным тематикам.
Очень важный функционал в стоп словах «Эксперт опции» — по умолчанию применяется символьное соответствие — т.е. стоп-слово «бу» удалит слова и фразы содержащие в себе сочетания букв «бу» — «бублик, бу холодильник, бумага» и т.д. Если выбрать фразовое соответствие стоп-слово «бу» удалит только слово / сочетания слов со словом «бу» — «бу холодильник, купить холодильник бу, бу», но не «бумага, бумеранг» и т.п.
Настоятельно рекомендуем использовать «Фразовое соответствие»
- Нажимаем «Создать новую задачу»!
На странице списка задач виден статус заявки.
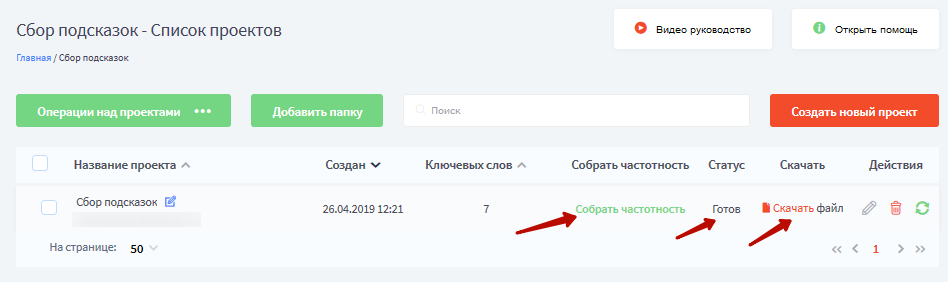
Существует несколько статусов:
- Очередь – данные еще не собираются.
- Сбор данных – счетчик показывает, сколько ключевых слов обработано.
- Готов – и рядом появляется возможность скачать файл.
- На паузе – вы можете вручную поставить задачу на паузу, если не уверены, что хотите его собирать. Или же, задача может сам встать на паузу т.к. у вас кончились деньги на балансе.
Результирующий файл имеет следующие листы:
- Подсказки без дубликатов — собранные системой поисковые подсказки на всех уровнях без дубликатов в один столбец.
- Все подсказки — все подсказки по всем словам, по каждому уровню сбора отдельными столбцами.
- Настройки задачи — указаны настройки вашей задачи.
Далее удобнее всего действовать по следующей схеме:
А) проверить все запросы на частотность в yandex.wordstat;
Б) отправить запросы на кластеризацию.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Как поисковик формирует подсказки
У каждой системы – Яндекса, Google и даже YouTube, принадлежащего Google, – свои собственные уникальные алгоритмы. Тем не менее можно выделить несколько общих факторов, влияющих на появление определенных поисковых подсказок:
Региональность
Поисковики учитывают географию пользователей при формировании поисковых подсказок. Особенно это касается запросов, начинающихся со слов «купить», «заказать», «доставка», «где» и т. д.
Примеры подсказок по коммерческому запросу
Популярность и актуальность
Подсказки выдаются с учетом того, что сейчас в тренде, освещается в соцмедиа.
Google не скрывает, что тренды определяют поисковые подсказки
Это легко проверить на практике. Просто возьмите пару недавних новостей из СМИ и начните вводить в поисковую строку имена героев, названия брендов или города, где произошли те или иные события. Подсказки реагируют быстро, в отличие от Яндекс.Вордстата и готовых баз ключевых слов.
Поисковое поведение
Поисковики учитывают интересы пользователей, часто посещаемые сайты, предыдущие запросы. Персонализация улучшает качество поиска.
Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Как создать семантическое ядро?
Формирование семантического ядра — это комплексный процесс, включающий анализ тематики и структуры сайта, работу со специальными сервисами и программами, редактирование базы ключей вручную. Есть два основных принципа создания СЯ:
- подбор максимального количества ключей и дальнейшей очистки;
- подбор точных ключевых фраз с самого начала с последующим расширением базы.
Мы обратились к нескольким SEO-экспертам, чтобы узнать, какой подход они предпочитают.
Тарас Гуща, СЕО в SEO.UA, склоняется к первому методу:
Лучше много ключей и потом чистить. Потому как иногда можно упустить весьма стоящие ключевые фразы. Нам как профессионалам продвижения сайтов надо давать клиентам максимальный результат. Поэтому каждая ключевая фраза, которая может конвертировать потенциальную аудиторию в клиента, очень важна.
А вот Катерина Золотарева, Founder & CEO в Site24, считает, что в зависимости от выбранной стратегии можно использовать оба подхода:
Если проект небольшой или в сложной для формирования семантики нише, например, технологические услуги, то однозначно надо собирать все и даже больше, потом вычеркивать нерелевантное, а околотематические ключи отправлять в блог.
Также имеет смысл глубоко заниматься семантикой, если проект уже имеет позиции, трафик, а стандартные базовые ключи и так уже включены в метатеги и текст. Тогда глубокая проработка семантики поможет вам значительно улучшить видимость и трафик.
Этапы создания семантического ядра
Создание СЯ можно разделить на три этапа.
- Выбор подхода для создания СЯ.
Есть несколько стратегий того, как можно собрать семантического ядро. Их применяют в зависимости от того, имеет ли ресурс структуру или только находится в процессе разработки, какой у него уровень оптимизации, какие позиции по ключевым словам он занимает и т.д..
- Сбор запросов с помощью специальных инструментов.
Сервисы подбора ключевых слов дают возможность охватить максимальное число запросов и поисковых подсказок. Для лучшего результата стоит задействовать инструменты для анализа семантики конкурентов.
- Формирование СЯ из общей базы запросов.
Этапы преобразования облака тематических запросов в семантическое ядро включают два основных этапа:
- очистка базы ключей от ненужных запросов;
- кластеризация путем деления семантики на группы.
Также в процессе анализа ключей можно отделить минус-слова. Кластеризация базы запросов предшествует распределению ключевых фраз по URL. В следующих разделах мы рассмотрим все этапы разработки семантического ядра подробно.
Подходы при создании семантического ядра
Рассмотрим стандартные схемы для создания баз ключей. В зависимости от конкретного случая можно использовать один из подходов, приведенных ниже, или же индивидуальную стратегию.
ПЕРВЫЙ ПОДХОД — ФОРМИРОВАНИЕ СТРУКТУРЫ НОВОГО САЙТА НА ОСНОВЕ СЯ.
- Исследование рыночной ниши/торговой линейки/брифа клиента.
- Определение списка основных запросов (seed keywords).
- Сбор максимального количества фраз для каждого основного ключа.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Очистка полученного списка запросов от дублей и мусорных фраз (при наличии списка минус-слов).
- Автоматическая кластеризация через SE Ranking.
- Окончательная очистка запросов.
- Создание структуры сайта по разделам, категориям, страницам на основе кластеризации.
ВТОРОЙ ПОДХОД — СБОР СЯ ПОД ГОТОВУЮ СТРУКТУРУ САЙТА
- Анализ структуры и разделов сайта.
- Определение списка основных запросов.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Сбор максимального количества релевантных ключевых фраз для запросов из п. 2 и 3.
- Очистка от мусорных и нерелевантных фраз.
- Разделение собранных запросов под существующие категории и страницы.
ТРЕТИЙ ПОДХОД — ОБНОВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА ДЛЯ САЙТА.
- Анализ существующей семантики сайта.
- Поиск «слабых мест»: сбор актуальных запросов в тематике, изучение поисковых подсказок, анализ конкурентов для определения недостающих ключей.
- Создание списка упущенных запросов и распределение их по разделам, категориям, страницам.
Как попасть в ТОП подсказок
Поисковые системы противостоят тому, чтобы бренды находились в поисковых подсказках. Но в некоторых случаях их наличие вполне оправдано. Основные факторы, которые способствуют этому:
Активная внешняя реклама
Интернет-маркетологи формируют рекламное предложение так, чтобы пользователи были заинтересованы в поиске сайта. Такие запросы в поисковой строке улучшают позиции сайтов, так как выступают сигналом для поисковых систем о том, что пользователей интересует контент конкретного ресурса по тому или иному запросу.
Организация и проведения масштабных мероприятий
Старайтесь регулярно организовывать мероприятия для своей аудитории или выступать в качестве спонсора. Так, если ваш бренд будет на слуху, он заинтересует пользователей, которые захотят найти информацию о нем в поиске. Такие запросы способствуют популяризации и не исключено, что со временем ваш сайт будет демонстрироваться во многих поисковых подсказках.
Накрутка поисковых запросов с вашим брендом
Существует много сервисов, которые предлагают услуги по накрутке поисковых запросов. Все что требуется от вас — задать ключевые запросы и регион. Если с популярным запросом в подсказке появится ваш сайт, то на него увеличится количество переходов. Этот спрос может быть как временным, так и долгосрочным. При грамотной стратегии отмечается ощутимый прирост трафика по витальным запросам.
Витальные запросы — запросы поисковых систем, включающие только название компании или бренда без всяких дополнительных фраз.
Доступные парсера Яндекса:
Парсер Яндекс Маркета Один из самых популярных парсеров у наших клиентов. Собирает описание товаров из Яндекс Маркета. В качестве входных данных можно задать название нужных товаров, ссылку на категорию или ссылку с параметрами пользовательского фильтра. Парсер соберет описание найденных товаров, их технические характеристики и изображения. Подробнее
Парсер Яндекс Карт Если вы работаете с конкретным регионом, то наверняка заинтересуетесь парсером Яндекс Карт. Ведь он позволяет собрать информацию об организациях, включая их контакты, в заданной категории. Соберите базу потенциальных клиентов или партнеров всего за 10 минут. Подробнее
Парсер выдачи Яндекс Когда ищут парсер Яндекса, чаще всего имеют в виду парсер поисковой выдачи. Ведь Яндекс в первую очередь это поисковая система. И среди наших парсеров вы найдете парсер поисковой выдачи, который собирает ссылки и сниппеты выдачи Яндекса по заданному ключевому слову. Настройки программы позволяют настроить сбор выдачи до нужной глубины, а также запуск следующей кампании, которая в качестве входных данных возьмет результаты текущей. Подробнее
Парсер ключевых слов Незаменимая настройка для маркетологов и seo-шников, с которой начинается создание любого сайта или рекламной кампании. Позволяет собрать прогноз показов по заданному ключевому слову или списку слов. Полученные данные можно обработать сразу после сбора с помощью плагинов или позже, предварительно сохранив результаты в Excel. Подробнее
Парсер сниппетов Яндекса В отличии от парсера поисковой выдачи Яндекса, парсер сниппетов соберет только снппет из поисковой выдачи, и запрос, по которому этот сниппет был получен. Инструмент пригодится при внутренней оптимизации сайта, улучшению CTR страницы в поисковой выдачи и повышения релевантности. Подробнее
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
Какие категории использовать — решаете сами. Откуда брать варианты? Сайты конкурентов, словари синонимов, тематические форумы и блоги — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такое:
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Парсинг вопросов-ответов в результатах поиска
Вопросы/ответы можно извлекать и вручную из результатов поиска. Но зачем, если есть шаблон от Hannah Rampton?
Это один из шаблонов, который мы используем при поиске идей для контента и постановке ТЗ копирайтерам. Анализ вопросов, связанных с основным запросом, позволяет углубиться в тему и создать интент-ориентированный контент (подробнее — в нашей статье об алгоритме Neural Matching).
Для выгрузки вопросов/ответов:
- создайте копию шаблона Google Q&A Extraction_v2;
- установите бесплатное расширение Scraper для Chrome (оно парсит данные с веб-страниц с помощью XPath);
- измените в настройках поисковика язык с русского на английский (это нужно для корректной работы формул в шаблоне).
Приступаем к парсингу вопросов/ответов:
в открывшемся окне в блоке «Selector» выбираем «XPath», вводим в поле запрос для парсинга раскрывающихся списков с вопросами/ответами: //g-accordion-expander (обратите внимание, чтобы блок Columns был заполнен так же, как на скриншоте);
нажимаем «Scrape»;
- после парсинга нажимаем «Copy to clipboard»;
- открываем шаблон, переходим на лист «Google Questions and Answers», наводим курсор на ячейку А10 и нажимаем Ctrl+Shift+V.
Если все сделано верно, то поля с вопросами, ответами и URL заполнятся автоматически.
На листе «Clean Data» та же информация представлена в юзабельном текстовом формате (кроме того, здесь исключены дубли).
На листе «Search by Keyword» вы можете найти вопросы по заданному ключевому слову (или его части).
Также вы можете выбрать вопросы по домену — для этого на листе «Search by Domain» введите полный URL или его часть.
Таким образом, вы быстро и бесплатно найдете релевантные вопросы по вашей тематике.