Матрицы в python и массивы numpy
Содержание:
- Основы индексирования и срезы
- Умножение и сложение
- Разделение матрицы
- Создание
- Индексы, срезы, итерации
- Индексирование массивов
- Получение строки, столбца и элемента
- Получение размера
- Зачем уметь создавать связный список на Python?
- Добро пожаловать в NumPy!
- Установка NumPy
- Как импортировать NumPy
- В чем разница между списком Python и массивом NumPy?
- Что такое массив?
- Создание списков на Python
- Сравнение
- List Comprehension
- Как вы вводите двумерный массив?
- Ремарка о строках
- Создание массива
- 2.4.5. Двумерные массивы¶
- NumPy N-мерный массив
- Ввод-вывод массива
Основы индексирования и срезы
Существует много способов выбора подмножества данных или элементов
массива. Одномерные массивы — это просто, на первый взгляд они
аналогичны спискам Python:
In : arr = np.arange(10) In : arr Out: array() In : arr Out: 5 In : arr Out: array() In : arr = 12 In : arr Out: array()
Как видно, если присвоить скалярное значение срезу, как например,
, значение присваивается всем элементам среза. Первым
важным отличием от списков Python заключается в том, что срезы массива
являются представлениями исходного массива. Это означает, что данные
не копируются и любые изменения в представлении будут отражены в
исходном массиве.
Рассмотрим пример. Сначала создадим срез массива :
In : arr_slice = arr In : arr_slice Out: array()
Теперь, если мы изменим значения в массиве , то они
отразятся в исходном массиве :
In : arr_slice = 12345 In : arr Out: array()
«Голый» срез присвоит все значения в массиве:
In : arr_slice = 64 In : arr Out: array()
Поскольку NumPy был разработан для работы с очень большими массивами,
вы можете представить себе проблемы с производительностью и памятью,
если NumPy будет настаивать на постоянном копировании данных.
Замечание
Если вы захотите скопировать срез в массив вместо отображения, нужно
явно скопировать массив, например, .
С массивами более высокой размерности существует больше вариантов. В
двумерных массивах каждый элемент это уже не скаляр, а одномерный
массив.
In : arr2d = np.array(, , ]) In : arr2d Out: array()
Таким образом, к отдельному элементу можно получить доступ
рекурсивно, либо передать разделенный запятыми список
индексов. Например, следующие два примера эквивалентны:
In : arr2d Out: array() In : arr2d[] Out: 3
Если в многомерном массиве опустить последние индексы, то возвращаемый
объект будет массивом меньшей размерности. Например, создадим массив
размерности \( 2 \times 2 \times 3 \):
In : arr3d = np.array(, ], , ]])
In : arr3d
Out:
array(,
],
,
]])
При этом — массив размерности \( 2 \times 3 \):
In : arr3d[]
Out:
array(,
])
Можно присваивать как скаляр, так и массивы:
In : old_values = arr3d[].copy()
In : arr3d[] = 42
In : arr3d
Out:
array(,
],
,
]])
In : arr3d[] = old_values
In : arr3d
Out:
array(,
],
,
]])
Аналогично, возвращает все значения, чьи индексы
начинаются с , формируя одномерный массив:
In : arr3d Out: array()
Это выражение такое же, как если бы мы проиндексировали в два этапа:
In : x = arr3d
In : x
Out:
array(,
])
In : x[]
Out: array()
Индексирование с помощью срезов
Как одномерные объекты, такие как списки, можно получать срезы
массивов посредством знакомого синтаксиса:
In : arr Out: array() In : arr Out: array()
Рассмотрим введенный выше двумерный массив . Получение срезов
этого массива немного отличается от одномерного:
In : arr2d
Out:
array(,
,
])
In : arr2d
Out:
array(,
])
Как видно, мы получили срез вдоль оси 0, первой оси. Срез, таким
образом, выбирает диапазон элементов вдоль оси. Выражение
можно прочитать как «выбираем первые две строки массива ».
Можно передавать несколько срезов:
In : arr2d
Out:
array(,
])
При получении срезов мы получаем только отображения массивов того же
числа размерностей. Используя целые индексы и срезы, можно получить
срезы меньшей размерности:
In : arr2d Out: array() In : arr2d Out: array()
Смотрите рис. .
Рисунок 1: Срезы двумерного массива
Умножение и сложение
Чтобы сложить матрицы, нужно сложить все их соответствующие элементы. В Python для их сложения используется обычный оператор «+».
Пример сложения:
arr1 = np.array(,]) arr2 = np.array(,]) temp = arr1 + arr2 print(temp)
Результирующая матрица будет равна:
]
Важно помнить, что складывать можно только матрицы с одинаковым количеством строк и столбцов, иначе программа на Python завершится с исключением ValueError. Умножение матриц сильно отличается от сложения
Не получится просто перемножить соответствующие элементы двух матриц. Во-первых, матрицы должны быть согласованными, то есть количество столбцов одной должно быть равно количеству строк другой и наоборот, иначе программа вызовет ошибку
Умножение матриц сильно отличается от сложения. Не получится просто перемножить соответствующие элементы двух матриц. Во-первых, матрицы должны быть согласованными, то есть количество столбцов одной должно быть равно количеству строк другой и наоборот, иначе программа вызовет ошибку.
Умножение в NumPy выполняется с помощью метода dot().
Пример умножения:
arr1 = np.array(,]) arr2 = np.array(,]) temp = arr1.dot(arr2) print(temp)
Результат выполнения этого кода будет следующий:
]
Как она получилась? Разберём число 21, его позиция это 1 строка и 2 столбец, тогда мы берем 1 строку первой матрицы и умножаем на 2 столбец второй. Причём элементы умножаются позиционно, то есть 1 на 1 и 2 на 2, а результаты складываются: * = 3 * 4 + 3 * 3 = 21.
Разделение матрицы
Разделение одномерного массива NumPy аналогично разделению списка. Рассмотрим пример:
import numpy as np letters = np.array() # с 3-го по 5-ый элементы print(letters) # Вывод: # с 1-го по 4-ый элементы print(letters) # Вывод: # с 6-го до последнего элемента print(letters) # Вывод: # с 1-го до последнего элемента print(letters) # Вывод: # список в обратном порядке print(letters) # Вывод:
Теперь посмотрим, как разделить матрицу.
import numpy as np
A = np.array(,
,
])
print(A) # две строки, четыре столбца
''' Вывод:
]
'''
print(A) # первая строка, все столбцы
''' Вывод:
` 1 4 5 12 14`
'''
print(A) # все строки, второй столбец
''' Вывод:
'''
print(A) # все строки, с третьего по пятый столбец
''' Вывод:
]
'''
Использование NumPy вместо вложенных списков значительно упрощает работу с матрицами. Мы рекомендуем детально изучить пакет NumPy, если вы планируете использовать Python для анализа данных.
Данная публикация является переводом статьи «Python Matrices and NumPy Arrays» , подготовленная редакцией проекта.
Создание
Для создании матрицы используется функция array(). В функцию передаётся список. Вот пример создания, мы подаём в качестве аргумента функции двумерный список:
a = np.array(, ])
Вторым параметром можно задать тип элементов матрицы:
a = np.array(,], int) print(a)
Тогда в консоль выведется:
]
Обратите внимание, что если изменить int на str, то тип элементов изменился на строковый. Кроме того, при выводе в консоль NumPy автоматически отформатировал вывод, чтобы он выглядел как матрица, а элементы располагались друг под другом
В качестве типов элементов можно использовать int, float, bool, complex, bytes, str, buffers. Также можно использовать и другие типы NumPy: логические, целочисленные, беззнаковые целочисленные, вещественные, комплексные. Вот несколько примеров:
- np.bool8 — логическая переменная, которая занимает 1 байт памяти.
- np.int64 — целое число, занимающее 8 байт.
- np.uint16 — беззнаковое целое число, занимающее 2 байта в памяти.
- np.float32 — вещественное число, занимающее 4 байта в памяти.
- np.complex64 — комплексное число, состоящее из 4 байтового вещественного числа действительной части и 4 байтов мнимой.
Вы также можете узнать размер матрицы, для этого используйте атрибут shape:
size = a.shape print(size) # Выведет (2, 3)
Первое число (2) — количество строк, второе число (3) — количество столбцов.
Нулевая матрица
Если необходимо создать матрицу, состоящую только из нулей, используйте функцию zeros():
a_of_zeros = np.zeros((2,2)) print(a_of_zeros)
Результат этого кода будет следующий:
]
Индексы, срезы, итерации
Одномерные массивы осуществляют операции индексирования, срезов и итераций очень схожим образом с обычными списками и другими последовательностями Python (разве что удалять с помощью срезов нельзя).
У многомерных массивов на каждую ось приходится один индекс. Индексы передаются в виде последовательности чисел, разделенных запятыми (то бишь, кортежами):
Когда индексов меньше, чем осей, отсутствующие индексы предполагаются дополненными с помощью срезов:
b можно читать как b. В NumPy это также может быть записано с помощью точек, как b.
Например, если x имеет ранг 5 (то есть у него 5 осей), тогда
- x эквивалентно x,
- x то же самое, что x и
- x это x.
Итерирование многомерных массивов начинается с первой оси:
Однако, если нужно перебрать поэлементно весь массив, как если бы он был одномерным, для этого можно использовать атрибут flat:
Индексирование массивов
Когда ваши данные представлены с помощью массива NumPy, вы можете получить к ним доступ с помощью индексации.
Давайте рассмотрим несколько примеров доступа к данным с помощью индексации.
Одномерное индексирование
Как правило, индексирование работает так же, как вы ожидаете от своего опыта работы с другими языками программирования, такими как Java, C # и C ++.
Например, вы можете получить доступ к элементам с помощью оператора скобок [], указав индекс смещения нуля для значения, которое нужно получить.
При выполнении примера печатаются первое и последнее значения в массиве.
Задание целых чисел, слишком больших для границы массива, приведет к ошибке.
При выполнении примера выводится следующая ошибка:
Одно из ключевых отличий состоит в том, что вы можете использовать отрицательные индексы для извлечения значений, смещенных от конца массива.
Например, индекс -1 относится к последнему элементу в массиве. Индекс -2 возвращает второй последний элемент вплоть до -5 для первого элемента в текущем примере.
При выполнении примера печатаются последний и первый элементы в массиве.
Двумерное индексирование
Индексация двумерных данных аналогична индексации одномерных данных, за исключением того, что для разделения индекса для каждого измерения используется запятая.
Это отличается от языков на основе C, где для каждого измерения используется отдельный оператор скобок.
Например, мы можем получить доступ к первой строке и первому столбцу следующим образом:
При выполнении примера печатается первый элемент в наборе данных.
Если нас интересуют все элементы в первой строке, мы можем оставить индекс второго измерения пустым, например:
Это печатает первый ряд данных.
Получение строки, столбца и элемента
Чтобы получить строку двухмерной матрицы, нужно просто обратиться к ней по индексу следующим образом:
temp = a print(temp) #Выведет
Получить столбец уже не так просто. Используем срезы, в качестве первого элемента среза мы ничего не указываем, а второй элемент — это номер искомого столбца. Пример:
arr = np.array(,], str) temp = arr print(temp) # Выведет
Чтобы получить элемент, нужно указать номер столбца и строки, в которых он находится. Например, элемент во 2 строке и 3 столбце — это 5, проверяем (помним, что нумерация начинается с 0):
arr = np.array(,], str) temp = arr print(temp) # Выведет 5
Получение размера
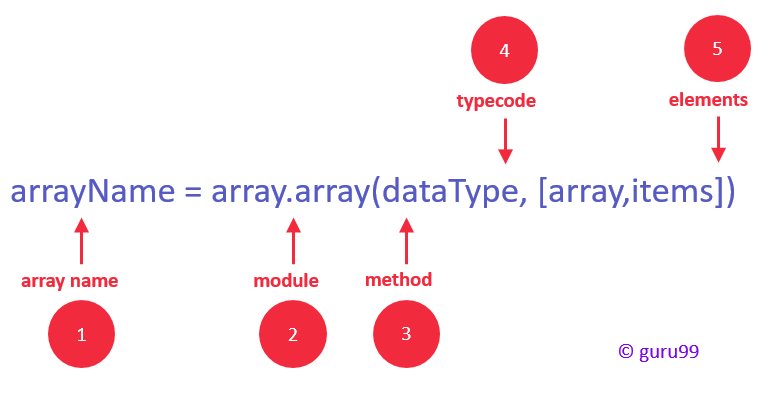
Поскольку размерность массива может меняться во время выполнения программы, иногда бывает полезным узнать текущее количество элементов, входящих в его состав. Функция len служит для получения длины (размера) массива в Python в виде целочисленного значения. Чтобы отобразить в Python количество элементов массива на экране стоит воспользоваться методом print.
from array import *
data = array('i', )
print(len(data))
Как видно из представленного выше кода, функция print получает в качестве аргумента результат выполнения len, что позволяет ей вывести числовое значение в консоль.
Зачем уметь создавать связный список на Python?
Зачем вообще может понадобиться создавать собственный связный список на Python? Это хороший вопрос. Использование связных списков имеет некоторые преимущества по сравнению с использованием просто списков Python.
Традиционно вопрос звучит как «чем использование связного списка лучше использования массива». Основная идея в том, что массивы в Java и других ООП-языках имеют фиксированный размер, поэтому для добавления элемента приходится создавать новый массив с размером N + 1 и помещать в него все значения из предыдущего массива. Пространственная и временная сложность этой операции — O(N). А вот добавление элемента в конец связного списка имеет постоянную временную сложность (O(1)).
Списки в Python это не настоящие массивы, а скорее реализация динамического массива, что имеет свои преимущества и недостатки. В Википедии есть .
Если вопрос производительности вас не тревожит, тогда да, проще реализовать обычный список Python. Но научиться реализовывать собственный связный список все равно полезно. Это как изучение математики: у нас есть калькуляторы, но основные концепции мы все-таки изучаем.
В сообществе разработчиков постоянно ведутся горячие споры о том, насколько целесообразно давать на технических интервью задания, связанные с алгоритмами и структурами данных. Возможно, в этом и нет никакого смысла, но на собеседовании вас вполне могут попросить реализовать связный список на Python. И теперь вы знаете, как это сделать.
Добро пожаловать в NumPy!
NumPy (NumericalPython) — это библиотека Python с открытым исходным кодом, которая используется практически во всех областях науки и техники. Это универсальный стандарт для работы с числовыми данными в Python, и он лежит в основе научных экосистем Python и PyData. В число пользователей NumPy входят все — от начинающих программистов до опытных исследователей, занимающихся самыми современными научными и промышленными исследованиями и разработками. API-интерфейс NumPy широко используется в пакетах Pandas, SciPy, Matplotlib, scikit-learn, scikit-image и в большинстве других научных и научных пакетов Python.
Библиотека NumPy содержит многомерный массив и матричные структуры данных (дополнительную информацию об этом вы найдете в следующих разделах). Он предоставляет ndarray, однородный объект n-мерного массива, с методами для эффективной работы с ним. NumPy может использоваться для выполнения самых разнообразных математических операций над массивами. Он добавляет мощные структуры данных в Python, которые гарантируют эффективные вычисления с массивами и матрицами, и предоставляет огромную библиотеку математических функций высокого уровня, которые работают с этими массивами и матрицами.
Узнайте больше о NumPy здесь!
GIF черезgiphy
Установка NumPy
Чтобы установить NumPy, я настоятельно рекомендую использовать научный дистрибутив Python. Если вам нужны полные инструкции по установке NumPy в вашей операционной системе, вы можетенайти все детали здесь,
Если у вас уже есть Python, вы можете установить NumPy с помощью
conda install numpy
или
pip install numpy
Если у вас еще нет Python, вы можете рассмотреть возможность использованияанаконда, Это самый простой способ начать. Преимущество этого дистрибутива в том, что вам не нужно слишком беспокоиться об отдельной установке NumPy или каких-либо основных пакетов, которые вы будете использовать для анализа данных, таких как pandas, Scikit-Learn и т. Д.
Если вам нужна более подробная информация об установке, вы можете найти всю информацию об установке наscipy.org,
фотоАдриеннотPexels
Если у вас возникли проблемы с установкой Anaconda, вы можете ознакомиться с этой статьей:
Как импортировать NumPy
Каждый раз, когда вы хотите использовать пакет или библиотеку в своем коде, вам сначала нужно сделать его доступным.
Чтобы начать использовать NumPy и все функции, доступные в NumPy, вам необходимо импортировать его. Это можно легко сделать с помощью этого оператора импорта:
import numpy as np
(Мы сокращаем «numpy» до «np», чтобы сэкономить время и сохранить стандартизированный код, чтобы любой, кто работает с вашим кодом, мог легко его понять и запустить.)
В чем разница между списком Python и массивом NumPy?
NumPy предоставляет вам огромный выбор быстрых и эффективных числовых опций. Хотя список Python может содержать разные типы данных в одном списке, все элементы в массиве NumPy должны быть однородными. Математические операции, которые должны выполняться над массивами, были бы невозможны, если бы они не были однородными.
Зачем использовать NumPy?
фотоPixabayотPexels
Массивы NumPy быстрее и компактнее, чем списки Python. Массив потребляет меньше памяти и намного удобнее в использовании. NumPy использует гораздо меньше памяти для хранения данных и предоставляет механизм задания типов данных, который позволяет оптимизировать код еще дальше.
Что такое массив?
Массив является центральной структурой данных библиотеки NumPy. Это таблица значений, которая содержит информацию о необработанных данных, о том, как найти элемент и как интерпретировать элемент. Он имеет сетку элементов, которые можно проиндексировать в Все элементы имеют одинаковый тип, называемыймассив dtype(тип данных).
Массив может быть проиндексирован набором неотрицательных целых чисел, логическими значениями, другим массивом или целыми числами.рангмассива это количество измерений.формамассива — это кортеж целых чисел, дающий размер массива по каждому измерению.
Одним из способов инициализации массивов NumPy является использование вложенных списков Python.
a = np.array(, , ])
Мы можем получить доступ к элементам в массиве, используя квадратные скобки. Когда вы получаете доступ к элементам, помните, чтоиндексирование в NumPy начинается с 0, Это означает, что если вы хотите получить доступ к первому элементу в вашем массиве, вы получите доступ к элементу «0».
print(a)
Выход:
Создание списков на Python
- Создать список можно несколькими способами. Рассмотрим их.
1. Получение списка через присваивание конкретных значений
Так выглядит в коде Python пустой список:
s = # Пустой список |
Примеры создания списков со значениями:
l = 25, 755, -40, 57, -41 # список целых чисел l = 1.13, 5.34, 12.63, 4.6, 34.0, 12.8 # список из дробных чисел l = "Sveta", "Sergei", "Ivan", "Dasha" # список из строк l = "Москва", "Иванов", 12, 124 # смешанный список l = , , , 1, , 1, 1, 1, # список, состоящий из списков l = 's', 'p', 'isok', 2 # список из значений и списка |
2. Списки при помощи функции List()
Получаем список при помощи функции List()
empty_list = list() # пустой список
l = list ('spisok') # 'spisok' - строка
print(l) # - результат - список
|
4. Генераторы списков
- В python создать список можно также при помощи генераторов, — это довольно-таки новый метод:
- Первый простой способ.
Сложение одинаковых списков заменяется умножением:
# список из 10 элементов, заполненный единицами l = 1*10 # список l = |
Второй способ сложнее.
l = i for i in range(10) # список l = |
или такой пример:
c = c * 3 for c in 'list' print (c) # |
Пример:
Заполнить список квадратами чисел от 0 до 9, используя генератор списка.
Решение:
l = i*i for i in range(10) |
еще пример:
l = (i+1)+i for i in range(10) print(l) # |
Случайные числа в списке:
from random import randint l = randint(10,80) for x in range(10) # 10 чисел, сгенерированных случайным образом в диапазоне (10,80) |
Задание Python 4_1:
Создайте список целых чисел от -20 до 30 (генерация).
Результат:
Задание Python 4_2:
Создайте список целых чисел от -10 до 10 с шагом 2 (генерация list).
Результат:
Задание Python 4_3:
Создайте список из 20 пятерок (генерация).
Результат:
Задание Python 4_4:
Создайте список из сумм троек чисел от 0 до 10, используя генератор списка (0 + 1 + 2, 1 + 2 + 3, …).
Результат:
Задание Python 4_5 (сложное):
Заполните массив элементами арифметической прогрессии. Её первый элемент, разность и количество элементов нужно ввести с клавиатуры.
* Формула для получения n-го члена прогрессии: an = a1 + (n-1) * d
Простейшие операции над списками
- Списки можно складывать (конкатенировать) с помощью знака «+»:
l = 1, 3 + 4, 23 + 5 # Результат: # l = |
33, -12, 'may' + 21, 48.5, 33 # |
или так:
a=33, -12, 'may' b=21, 48.5, 33 print(a+b)# |
Операция повторения:
,,,1,1,1 * 2 # , , , , , ] |
Пример:
Для списков операция переприсваивания значения отдельного элемента списка разрешена!:
a=3, 2, 1 a1=; print(a) # |
Можно!
Задание 4_6:
В строке записана сумма натуральных чисел: ‘1+25+3’. Вычислите это выражение. Работать со строкой, как со списком.
Начало программы:
s=input('введите строку')
l=list(str(s));
|
Как узнать длину списка?
Сравнение
Пора перейти к самому интересному.
Составим список функций, которые будем сравнивать:
Разберем несколько ситуаций: оба списка примерно одинакового размера, один список большой, а второй маленький, количество вариантов элементов большое, количество вариантов маленькое. Кроме этого проведем просто общий случайный тест.
Тест первый
Проведем общий тест, размеры от до , элементы от до .
Отдельно сравним и :
тратит колоссально больше времени в общем случае, как и ожидалось.
Не будем учитывать здесь огромный , чтобы лучше видеть разницу между другими:
показал себя относительно неплохо по сравнению с ручной реализацией и .
Методы на итераторах работают еще быстрее, при этом видно, что получилось выгоднее построить генератор, чем добавлять элементы в список.
Тест второй, сравнимые размеры
Размеры будут принадлежать отрезку , а увеличиваем, начиная с . Шаг .
Как уже можно видеть при небольшом размере списков еще ведет себя как , а дальше обгоняет всех.
Тест третий, один маленький, второй большой
Размер первого равен , размер второго .
В самом начале (на очень маленьких списках) обгоняет всех, кроме , но на чуть больших все выходит на стандартные позиции.
Тест четвертый, много повторных
Размеры фиксированы, а количество элементов увеличивается на , начиная с .
Как видно, на достаточно малых количествах оказывается быстрее и , но потом он отстает.
List Comprehension
List Comprehension это создание списка путем итерации в цикле уже существующего списка (с соблюдением указанных условий). Поначалу такой подход может казаться сложным, но когда разберетесь, вы поймете, насколько это просто и быстро.
Чтобы разобраться в list comprehension, нужно
для начала обратиться к обычной итерации
списка. В следующем простом примере
показано, как вернуть новый список,
состоящий только из четных чисел старого.
# просто любой список чисел
some_list =
# пустой список, который будет заполняться четными числами из первого списка
even_list = []
for number in some_list:
if number % 2 == 0:
even_list.append(number)
print(even_list) #
Давайте разберем этот пример. Сначала мы создаем список с числами. Затем создаем пустой список, в котором будут сохраняться результаты, полученные в цикле. Дальше идет сам цикл, в котором мы перебираем числа из первого списка и проверяем, являются ли они четными. Если число делится на 2 без остатка, мы добавляем его в список четных чисел. Для получения нужного результата нам потребуется 5 строк кода (без учета комментариев), да еще пробелы.
А теперь давайте посмотрим пример, в
котором мы делаем все то же самое, но с
помощью list comprehension.
# просто любой список чисел some_list = # List Comprehension even_list = print(even_list) #
Давайте возьмем еще пример. Создадим
список, каждый элемент которого будет
элементом старого списка, умноженным
на 7.
my_starting_list =
my_new_list = []
for item in my_starting_list:
my_new_list.append(item * 7)
print(my_new_list) #
С помощью list comprehension можно достичь
того же результата:
my_starting_list = my_new_list = print(my_new_list) #
Вообще list comprehension пишется в соответствии
со следующей формулой:
В блоке вы указываете, что конкретно нужно сделать с элементом, который возвращает итерация объекта. В нашем примере это , но операция может быть любой, как очень простой, так и очень сложной.
В блок нужно вставить имя объекта, который вы будете перебирать в цикле. В нашем примере это был список, но мог быть кортеж или диапазон.
List
comprehension добавляет элемент из существующего
списка в новый, если соблюдается какое-то
условие. Этот способ лаконичнее, а в
большинстве случаев еще и намного
быстрее. Иногда применение list comprehension
может ухудшить читаемость кода, поэтому
разработчику нужно действовать по
ситуации.
Примеры использования list comprehension с условиями
Вносим в новый список только четные
числа:
only_even_list = print(only_even_list) #
Это эквивалентно следующему циклу:
only_even_list = list()
for i in range(13):
if i%2 == 0:
only_even_list.append(i)
print(only_even_list) #
List
comprehension может также содержать вложенные
if-условия
Обратите внимание на следующий
пример:
divisible = list()
for i in range(50):
if i % 2 == 0:
if i % 3 == 0:
divisible.append(i)
print(divisible) #
С применением list comprehension этот код можно
переписать следующим образом:
divisible = print(divisible) #
С list comprehension также может использоваться if-else. В следующем примере мы берем диапазон чисел от 0 до 10 и добавляем в наш список все четные числа из этого диапазона, а нечетные добавляем после умножения на -1.
list_1 = print(list_1) #
Подписаться
×
Как вы вводите двумерный массив?
Скажем, программа принимает входной двумерный массив в виде строк, каждый из которых содержит чисел, разделенных пробелами. Как заставить программу читать ее? Пример того, как вы можете это сделать:
3 1 2 3 4 5 6 7 8 9
# первая строка ввода - это количество строк массива
n = int(input())
a = []
for i in range(n):
a.append()
Или, не используя сложные вложенные вызовы:
3 1 2 3 4 5 6 7 8 9
# первая строка ввода - это количество строк массива
n = int(input())
a = []
for i in range(n):
row = input().split()
for i in range(len(row)):
row = int(row)
a.append(row)
Вы можете сделать то же самое с генераторами:
3 1 2 3 4 5 6 7 8 9
# первая строка ввода - это количество строк массива n = int(input()) a = for i in range(n)]
Ремарка о строках
На самом деле, мы уже ранее сталкивались с массивами в предудыщих лабораторных, когда использовали строковый метод :
>>> s = "ab cd ef1 2 301" >>> s.split() 'ab', 'cd', 'ef1', '2', '301'
Т.е. , по умолчанию, разбивает строку по символам пустого пространства (пробел, табуляция) и создаёт массив из получившихся «слов».
Загляните в , чтобы узнать, как изменить такое поведение, и разбивать строку, например, по запятым, что является стандартом для представления таблиц в файлах (comma separated values).
Методом, являющимся обратным к операции является .
Он «собирает» строку из массива строк:
Создание массива
Простейший способ создания массива — использование функции
. Она принимает некоторый объект типа последовательностей
(включая другие массивы) и создает новый массив NumPy, содержащий
переданные данные. Например:
In : data1 = In : arr1 = np.array(data1) In : arr1 Out: array()
Вложенные последовательности, как список списков одинаковой длины,
будут преобразованы в многомерный массив:
In : data2 = , ]
In : arr2 = np.array(data2)
In : arr2
Out:
array(,
])
Если явно не указано, пытается вывести подходящий тип
данных для массива, который он создает. Тип данных хранится в
специальном объекте метаданных; например, в двух предыдущих
примерах мы имеем:
In : arr1.dtype
Out: dtype('float64')
In : arr2.dtype
Out: dtype('int64')
Кроме есть несколько других функций для создания новых
массивов:
In : np.zeros(10)
Out: array()
In : np.zeros((3, 6))
Out:
array(,
,
])
In : np.empty((2, 3, 2))
Out:
array(,
,
],
,
,
]])
In : np.arange(15)
Out: array()
Таблица 1. Функции создания массивов
| Функция | Описание |
| Преобразует входные данные (список, кортеж, массив или другая последовательность) в , либо прогнозируя , либо используя заданный ; копирует данные по-умолчанию | |
| Преобразует входные данные в , но не копирует их, если аргумент уже типа | |
| Подобна встроенной функции , но возвращает вместо списка | |
| Создает массив из единиц заданной формы и | |
| Получает на вход массив и создает массив из единиц с такими же формой и | |
| и | Подобны и , но создают массивы из нулей |
| и | Создают новые массивы, выделяя новую память, но не инициализируют их какими-либо значениями, как и |
| Создает массив заданных формы и , при этом все элементы инициализируются заданным значением | |
| Получает на вход массив и создает массив с такими же формой и и значениями | |
| и | Создает квадратную единичную матрицу (с единицами на диагонали и нулями вне нее) размера \( N\times N \) |
2.4.5. Двумерные массивы¶
Выше везде элементами массива были числа. Но на самом деле элементами
массива может быть что угодно, в том числе другие массивы. Пример:
a = 10, 20, 30 b = -1, -2, -3 c = 100, 200 z = a, b, c
Что здесь происходит? Создаются три обычных массива , и
, а потом создается массив , элементами которого являются как
раз массивы , и .
Что теперь получается? Например, — это элемент №1 массива
, т.е. . Но — это тоже массив, поэтому я могу написать
— это то же самое, что , т.е. (не забывайте,
что нумерация элементов массива идет с нуля). Аналогично,
и т.д.
То же самое можно было записать проще:
z = , -1, -2, -3], 100, 200]]
Получилось то, что называется двумерным массивом. Его можно себе еще
представить в виде любой из этих двух табличек:
Первую табличку надо читать так: если у вас написано , то
надо взять строку № и столбец №. Например, —
это элемент на 1 строке и 2 столбце, т.е. -3. Вторую табличку надо
читать так: если у вас написано , то надо взять столбец
№ и строку №. Например, — это элемент на 2
столбце и 1 строке, т.е. -3. Т.е. в первой табличке строка — это первый
индекс массива, а столбец — второй индекс, а во второй табличке
наоборот. (Обычно принято как раз обозначать первый индекс и
— второй.)
Когда вы думаете про таблички, важно то, что питон на самом деле не
знает ничего про строки и столбцы. Для питона есть только первый индекс
и второй индекс, а уж строка это или столбец — вы решаете сами, питону
все равно
Т.е. и — это разные вещи, и питон их
понимает по-разному, а будет 1 номером строки или столбца — это ваше
дело, питон ничего не знает про строки и столбцы. Вы можете как хотите
это решить, т.е. можете пользоваться первой картинкой, а можете и второй
— но главное не запутайтесь и в каждой конкретной программе делайте
всегда всё согласованно. А можете и вообще не думать про строки и
столбцы, а просто думайте про первый и второй индекс.
Обратите, кстати, внимание на то, что в нашем примере (массив,
являющийся вторым элементом массива ) короче остальных массивов (и
поэтому на картинках отсутствует элемент в правом нижнем углу). Это
общее правило питона: питон не требует, чтобы внутренние массивы были
одинаковой длины
Вы вполне можете внутренние массивы делать разной
длины, например:
x = , 5, 6], 7, 8, 9], [], 10]]
здесь нулевой массив имеет длину 4, первый длину 2, второй длину 3,
третий длину 0 (т.е. не содержит ни одного элемента), а четвертый длину
1. Такое бывает надо, но не так часто, в простых задачах у вас будут все
подмассивы одной длины.
NumPy N-мерный массив
NumPy — это библиотека Python, которая может использоваться для научных и числовых приложений, а также инструмент для операций с линейной алгеброй.
Основной структурой данных в NumPy является ndarray, который является сокращенным именем для N-мерного массива. При работе с NumPy данные в ndarray просто называются массивом.
Это массив фиксированного размера в памяти, который содержит данные одного типа, такие как целые числа или значения с плавающей запятой.
Доступ к типу данных, поддерживаемому массивом, можно получить через атрибут «dtype» в массиве. Доступ к измерениям массива можно получить через атрибут «shape», который возвращает кортеж, описывающий длину каждого измерения. Есть множество других атрибутов. Узнайте больше здесь:
N-мерный массив
Простой способ создать массив из данных или простых структур данных Python, таких как список, — это использовать функцию array ().
В приведенном ниже примере создается список Python из трех значений с плавающей запятой, затем создается ndarray из списка и осуществляется доступ к форме и типу массивов.
При выполнении примера печатается содержимое ndarray, фигура, которая является одномерным массивом с 3 элементами, и тип данных, который является 64-битной плавающей точкой.
Ввод-вывод массива
Как вам считывать массив? Во-первых, если все элементы массива задаются в одной строке входного файла. Тогда есть два способа. Первый — длинный, но довольно понятный:
a = input().split() # считали строку и разбили ее по пробелам
# получился уже массив, но питон пока не понимает, что в массиве числа
for i in range(len(a)):
a = int(a) # прошли по всем элементам массива и превратили их в числа
Второй — покороче, но попахивает магией:
a = list(map(int, input().split()))
Может показаться страшно, но на самом деле вы уже встречали в конструкции
x, y = map(int, input().split())
когда вам надо было считать два числа из одной строки. Это считывает строку (), разбивает по пробелам (), и превращает каждую строку в число (). Для чтения массива все то же самое, только вы еще заворачиваете все это в , чтобы явно сказать питону, что это массив.
Какой из этих двух способов использовать для чтения данных из одной строки — выбирать вам.
Обратите внимание, что в обоих способах вам не надо знать заранее, сколько элементов будет в массиве — получится столько, сколько чисел в строке. В задачах часто бывает что задается сначала количество элементов, а потом (обычно на следующей строке) сами элементы
Это удобно в паскале, c++ и т.п., где нет способа легко считать числа до конца строки; в питоне вам это не надо, вы легко считываете сразу все элементы массива до конца строки, поэтому заданное число элементов вы считываете, но дальше не используете:
n = int(input()) # больше n не используем a = list(map(int, input().split()))
Еще бывает, что числа для массива задаются по одному в строке. Тогда вам проще всего заранее знать, сколько будет вводиться чисел. Обычно как раз так данные и даются: сначала количество элементов, потом сами элементы. Тогда все вводится легко:
n = int(input())
a = [] # пустой массив, т.е. массив длины 0
for i in range(n):
a.append(int(input())) # считали число и сразу добавили в конец массива
Более сложные варианты — последовательность элементов по одному в строке, заканчивающаяся нулем, или задано количество элементов и сами элементы в той же строке — придумайте сами, как сделать (можете подумать сейчас, можете потом, когда попадется в задаче). Вы уже знаете все, что для этого надо.
Как выводить массив? Если надо по одному числу в строку, то просто:
for i in range(len(a)):
print(a)
Если же надо все числа в одну строку, то есть два способа. Во-первых, можно команде передать специальный параметр , который обозначает «заканчивать вывод пробелом (а не переводом строки)»:
for i in range(len(a)):
print(a, end=" ")
Есть другой, более простой способ:
print(*a)
Эта магия обозначает вот что: возьми все элементы массива и передай их отдельными аргументами в одну команду . Т.е. получается .