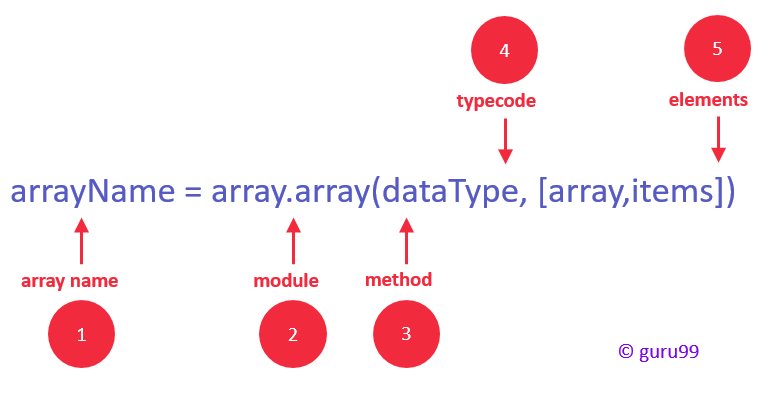
Python dictionary append with examples
Содержание:
- Значения нотации «О» большое
- Как удалить элементы из списка
- Закрепляем методы списков в Python
- Начало работы с методами сортировки Pandas ↑
- Python slicing lists
- Append a text to file in Python
- Method 3: Using += Operator
- Производительность
- Python map and filter functions
- Python simple list
- 7. Iterating a Python list using lambda function
- Best Practices
- Create an empty list in python using list() Constructor
- Вопрос 11. Как работает функция range?
- Методы списков Python
- Способы создания списка
- Заключение ↑
Значения нотации «О» большое
На письме временная сложность алгоритма обозначается как O(n), где n — размер входной коллекции.
O(1)
Обозначение константной временной сложности. Независимо от размера коллекции, время, необходимое для выполнения операции, константно. Это обозначение константной временной сложности. Эти операции выполняются настолько быстро, насколько возможно. Например, операции, которые проверяют, есть ли внутри коллекции элементы, имеют сложность O(1).
O(log n)
Обозначение логарифмической временной сложности. В этом случае когда размер коллекции увеличивается, время, необходимое для выполнения операции, логарифмически увеличивается. Эту сложность имеют потенциально оптимизированные алгоритмы поиска.
O(n)
Обозначение линейной временной сложности. Время, необходимое для выполнения операции, прямо и линейно пропорционально количеству элементов в коллекции. Это обозначение линейной временной сложности. Это что-то среднее с точки зрения производительности. Например, если мы хотим суммировать все элементы в коллекции, нужно будет выполнить итерацию по коллекции. Следовательно, итерация коллекции является операцией O(n).
O(n log n)
Обозначение квазилинейной временной сложности. Скорость выполнения операции является квазилинейной функцией числа элементов в коллекции. Временная сложность оптимизированного алгоритма сортировки обычно равна O(n log n).
O(n^2)
Обозначение квадратичной временной сложности. Время, необходимое для выполнения операции, пропорционально квадрату элементов в коллекции.
O(n!)
Обозначение факториальной временной сложности. Каждая операция требует вычисления всех перестановок коллекции, следовательно требуемое время выполнения операции является факториалом размера входной коллекции. Это очень медленно.
Нотация «O» большое относительна. Она не зависит от машины, игнорирует константы и понятна широкой аудитории, включая математиков, технологов, специалистов по данным и т. д.
Как удалить элементы из списка
Мы можем удалить один или несколько элементов из списка, используя ключевое слово del. При помощи этой команды вы так же можете удалить список полностью.
my_list = # Удалить один элемент del my_list # Результат: print(my_list) # Удалить несколько элементов del my_list # Результат: print(my_list) # Удалить весь список del my_list # Результат: Error: List not defined print(my_list)
Мы можем использовать метод remove() для удаления элемента или метод pop() для удаления элемента по указанному индексу.
Метод pop() удаляет последний элемент, если индекс не указан. Это помогает нам реализовывать списки в виде стеков «first come, last go» («первый вошел, последний вышел»).
Мы также можем использовать метод clear() для очистки списка от содержимого, без удаления самого списка.
my_list =
my_list.remove('p')
# Результат:
print(my_list)
# Результат: 'o'
print(my_list.pop(1))
# Результат:
print(my_list)
# Результат: 'm'
print(my_list.pop())
# Результат:
print(my_list)
my_list.clear()
# Результат: []
print(my_list)
Наконец, мы также можем удалить элементы в списке, назначив пустой список фрагменту элементов.
>>> my_list = >>> my_list = [] >>> my_list >>> my_list = [] >>> my_list
Закрепляем методы списков в Python
Знание соответствующих методов и функций в Python позволит выполнить поиск, добавить нужный элемент, сделать сортировку и т. д. Итак, давайте перечислим основные методы списков и их функции (вспомним те, что уже упоминали, плюс добавим новые):
1.list.append(x) — обеспечивает добавление элемента в конец списка:
>>> a = 1, 2 >>> a.append(3) >>> print(a) 1, 2, 3
2.list.extend(L) — расширяет имеющийся список путем добавления элементов из списка L.
>>> a = 1, 2 >>> b = 3, 4 >>> a.extend(b) >>> print(a) 1, 2, 3, 4
3.list.insert(i, x) — добавляет, а точнее, вставляет элемент х в позицию i. В качестве первого аргумента выступает индекс элемента, после которого вставляется элемент х.
>>> a = 1, 2 >>> a.insert(, 5) >>> print(a) 5, 1, 2 >>> a.insert(len(a), 9) >>> print(a) 5, 1, 2, 9
4.list.remove(x) — служит для удаления первого вхождения элемента х, включённого в наш список.
>>> a = 1, 2, 3 >>> a.remove(1) >>> print(a) 2, 3
5.list.pop() — обеспечивает удаление элемента из позиции i. Если применять метод без аргумента, удаляется последний элемент, находящийся в списке.
>>> a = 1, 2, 3, 4, 5 >>> print(a.pop(2)) 3 >>> print(a.pop()) 5 >>> print(a) 1, 2, 4
6.list.clear() — просто удаляет все элементы:
>>> a = 1, 2, 3, 4, 5 >>> print(a) 1, 2, 3, 4, 5 >>> a.clear() >>> print(a) []
7.list.index(x]) — позволяет вернуть индекс элемента:
>>> a = 1, 2, 3, 4, 5 >>> a.index(4) 3
8.list.count(x) — возвращает число вхождений элемента х:
>>> a=1, 2, 2, 3, 3 >>> print(a.count(2)) 2
9.list.sort(key=None, reverse=False) — сортирует элементы списков по возрастанию. Чтобы выполнить сортировку в обратном порядке используют флаг reverse=True. Кроме того, дополнительные возможности открываются параметром key.
>>> a = 1, 4, 2, 8, 1 >>> a.sort() >>> print(a) 1, 1, 2, 4, 8
10.list.reverse() — порядок расположения элементов меняется на обратный:
>>> a = 1, 3, 5, 7 >>> a.reverse() >>> print(a) 7, 5, 3, 1
11.list.copy() — копирует списки:
>>> a = 1, 7, 9 >>> b = a.copy() >>> print(a) 1, 7, 9 >>> print(b) 1, 7, 9 >>> b = 8 >>> print(a) 1, 7, 9 >>> print(b) 8, 7, 9
Начало работы с методами сортировки Pandas ↑
Напоминаем, что DataFrame — это структура данных с помеченными осями для строк и столбцов. Вы можете отсортировать DataFrame по значению строки или столбца, а также по индексу строки или столбца.
И строки, и столбцы имеют индексы, которые представляют собой числовые представления о том, где находятся данные в вашем DataFrame. Вы можете получать данные из определенных строк или столбцов, используя расположение индекса DataFrame. По умолчанию номера индексов начинаются с нуля. Вы также можете вручную назначить собственный индекс.
Подготовка набора данных
В этом уроке будем работать с данными об экономии топлива, собранными Агентством по охране окружающей среды США (EPA) на транспортных средствах, выпущенных в период с 1984 по 2021 год. Набор данных EPA по экономии топлива великолепен, потому что он содержит много различных типов информации, которую вы можете отсортировать, включая текстовую и числовою информацию. Набор данных содержит всего восемьдесят три колонки.
Чтобы продолжить, вам понадобится установленная библиотека Python pandas. Код в этом руководстве был выполнен с использованием pandas 1.2.0 и Python 3.9.1.
Для анализа будем просматривать данные о MPG (миля на галлон) для транспортных средств по маркам, моделям, годам и другим характеристикам транспортных средств. Можно указать, какие столбцы следует читать в DataFrame. Для этого урока вам понадобится только часть доступных столбцов. Вот команды для чтения соответствующих столбцов набора данных по экономии топлива в DataFrame и для отображения первых пяти строк:
>>> import pandas as pd >>> column_subset = >>> df = pd.read_csv( ... "https://www.fueleconomy.gov/feg/epadata/vehicles.csv", ... usecols=column_subset, ... nrows=100 ... ) >>> df.head() city08 cylinders fuelType ... mpgData trany year 0 19 4 Regular ... Y Manual 5-spd 1985 1 9 12 Regular ... N Manual 5-spd 1985 2 23 4 Regular ... Y Manual 5-spd 1985 3 10 8 Regular ... N Automatic 3-spd 1985 4 17 4 Premium ... N Manual 5-spd 1993
Вызывая с URL-адресом набора данных, вы можете загрузить данные в DataFrame. Сокращение количества столбцов приводит к более быстрой загрузке и меньшему использованию памяти. Чтобы еще больше ограничить потребление памяти и быстро почувствовать данные, вы можете указать, сколько строк загружать, используя .
Знакомство с .sort_values()
Для сортировки значений в DataFrame по любой оси (столбцы или строки) используем . Как правило, требуется отсортировать строки в DataFrame по значениям одного или нескольких столбцов:
На рисунке выше показаны результаты использования для сортировки строк DataFrame на основе значений в столбце . Это похоже на то, как вы сортируете данные в электронной таблице с помощью столбца.
Знакомство с .sort_index()
используем для сортировки DataFrame по индексу строки или меткам столбцов. Отличие от заключается в том, что вы сортируете DataFrame на основе индекса строки или имени столбцов, а не значений в этих строках или столбцах:
Индекс строки DataFrame обведен синим на рисунке выше. Индекс не считается столбцом, и обычно у вас есть только один индекс строки. Индекс строки можно рассматривать как номера строк, которые начинаются с нуля.
Python slicing lists
List slicing is an operation that extracts certain
elements from a list and forms them into another list. Possibly with
different number of indices and different index ranges.
The syntax for list slicing is as follows:
The start, end, step parts of the syntax are integers. Each of them is optional.
They can be both positive and negative. The value having the end index is not
included in the slice.
slice.py
#!/usr/bin/env python # slice.py n = print(n) print(n) print(n) print(n)
We create four slices from a list of eight integers.
print(n)
The first slice has values with indexes 1, 2, 3, and 4.
The newly formed list is .
print(n)
If the start index is omitted then a default value is assumed, which is 0.
The slice is .
print(n)
If the end index is omitted, the -1 default value is taken. In such a case a
slice takes all values to the end of the list.
print(n)
Even both indexes can be left out. This syntax creates a copy of a list.
$ ./slice.py
Output of the example.
The third index in a slice syntax is the step. It allows us to take every
n-th value from a list.
slice2.py
#!/usr/bin/env python # slice2.py n = print(n) print(n) print(n) print(n)
We form four new lists using the step value.
print(n)
Here we create a slice having every second element from the n list, starting from
the second element, ending in the eighth element. The new list has the following
elements: .
print(n)
Here we build a slice by taking every second value from the beginning to the end
of the list.
print(n)
This creates a copy of a list.
print(n)
The slice has every third element, starting from the second element to the end of the
list.
$ ./slice2.py
Output of the example.
Indexes can be negative numbers. Negative indexes refer to values from the end
of the list. The last element has index -1, the last but one has index -2 etc.
Indexes with lower negative numbers must come first in the syntax. This means
that we write instead of . The latter returns an empty list.
slice3.py
#!/usr/bin/env python # slice3.py n = print(n) print(n) print(n) print(n) print(n)
In this script, we form five lists. We also use negative index numbers.
print(n) print(n)
The first line returns , the second line returns an empty list.
Lower indexes must come before higher indexes.
print(n)
This creates a reversed list.
$ ./slice3.py []
Output of the example.
The above mentioned syntax can be used in assignments. There must be an
iterable on the right side of the assignment.
slice4.py
#!/usr/bin/env python # slice4.py n = n = 10 n = 20, 30 n = 40, 50, 60, 70, 80 print(n)
We have a list of eight integers. We use the slice syntax to replace the elements
with new values.
Append a text to file in Python
Suppose we have a file ‘sample.txt,’ and its contents are,
Hello this is a sample file It contains sample text This is the end of file
‘hello’
# Open a file with access mode 'a'
file_object = open('sample.txt', 'a')
# Append 'hello' at the end of file
file_object.write('hello')
# Close the file
file_object.close()
Hello this is a sample file It contains sample text This is the end of filehello
‘a’
Append a text to file in Python using ‘with open’ statement
We can open the file in append access mode i.e. ‘a’, using ‘with open’ statement too, and then we can append the text at the end of the file.
For example,
# Open a file with access mode 'a'
with open("sample.txt", "a") as file_object:
# Append 'hello' at the end of file
file_object.write("hello")
Hello this is a sample file It contains sample text This is the end of filehellohello
‘hello’‘sample.txt’‘with statement’
In both the above examples, the text gets added at the end of the file. But as we can see, it is not appended as a new line. There might be scenarios when we want to add data to a file as a new line.
Let’s see how to do that,
Method 3: Using += Operator
- We can also use operator which would append strings at the end of existing value also referred as
- The expression is shorthand for , where and can be numbers, or strings, or tuples, or lists (but both must be of the same type).
- In this example I have defined an empty global variable and I will append a range of strings (integers would be marked as string using ) into this variable
#!/usr/bin/env python3
# Define variable with empty string value
a = ''
for i in range(5):
# append strings to the variable
a += str(i)
# print variable a content
print(a)
The output from this python script would print a range from 0-4 which were stored in variable a
# python3 /tmp/append_string.py 01234
Производительность
Вы можете задаться вопросом, что является более производительным, поскольку append можно использовать для достижения того же результата, что и extension. Следующие функции делают то же самое:
Итак, давайте их время:
Обращение к комментарию о времени
Комментатор сказал:
Делай семантически правильную вещь. Если вы хотите добавить все элементы в итерацию, используйте . Если вы просто добавляете один элемент, используйте .
Хорошо, давайте создадим эксперимент, чтобы увидеть, как это работает во времени:
И мы видим, что выход из нашего пути создания итерируемого только для использования расширения — это (незначительная) тратавремя:
Из этого мы узнаем, что ничего не получится от использования , когда у нас есть только один элемент для добавления .
Кроме того, эти сроки не так важны. Я просто показываю им, что в Python выполнение семантически правильной вещи — это выполнение Right Way .
Вполне возможно, что вы можете протестировать время двух сопоставимых операций и получить неоднозначный или обратный результат. Просто сосредоточьтесь на том, чтобы делать семантически правильные вещи.
Python map and filter functions
The and functions are mass
functions that work on all list items. They are part of the functional
programming built into the Python language.
Today, it is recommended to use list comprehensions instead of these
functions where possible.
map_fun.py
#!/usr/bin/env python
# map_fun.py
def to_upper(s):
return s.upper()
words =
words2 = list(map(to_upper, words))
print(words2)
The function applies a particular function to every
element of a list.
def to_upper(s):
return s.upper()
This is the definition of the function that will be applied
to every list element. It calls the string
method on a given string.
words =
This is the list of strings.
words2 = map(to_upper, words) print(words2)
The function applies the
function to every string element of the words list. A new list is formed and
returned back. We print it to the console.
$ ./map_fun.py
Every item of the list is in capital letters.
The function constructs a list from those elements of
the list for which a function returns true.
filter_fun.py
#!/usr/bin/env python
# filter_fun.py
def positive(x):
return x > 0
n =
print(list(filter(positive, n)))
An example demonstrating the function.
It will create a new list having only positive values. It will
filter out all negative values and 0.
def positive(x):
return x > 0
This is the definition of the function used by the
function. It returns or . Functions that
return a boolean value are called predicates.
$ ./filter_fun.py
Output of the script.
In this part of the Python tutorial, we have described Python lists.
Contents
Previous
Next
Python simple list
List elements can be accessed by their index. The first element has index 0, the
last one has index -1.
simple.py
#!/usr/bin/env python # simple.py nums = print(nums) print(nums) print(nums)
This is a simple list having five elements. The list is delimited by
square brackets . The elements of a list are separated
by a comma character. The contents of a list are printed to the console.
nums =
The right side of the assignment is a Python list literal. It creates a list
containing five elements.
$ ./simple.py 1 5
This is the output of the example.
Lists can contain elements of various data types.
various_types.py
#!/usr/bin/env python
# various_types.py
class Being:
pass
objects = , "Python", (2, 3), Being(), {}]
print(objects)
In the example, we create an objects list. It contains numbers, a boolean value,
another list, a string, a tuple, a custom object, and a dictionary.
$ ./various_types.py
, 'Python', (2, 3),
<__main__.Being instance at 0x7f653577f6c8>, {}]
This is the output.
7. Iterating a Python list using lambda function
Python’s lambda functions are basically anonymous functions.
Syntax:
lambda parameters: expression
expression: The iterable which is to be evaluated.
The lambda function along with a Python map() function can be used to iterate a list easily.
Python method accepts a function as a parameter and returns a list.
The input function to the map() method gets called with every element of the iterable and it returns a new list with all the elements returned from the function, respectively.
Example:
lst = res = list(map(lambda x:x, lst)) print(res)
In the above snippet of code, lambda x:x function is provided as input to the map() function. The lambda x:x will accept every element of the iterable and return it.
The input_list (lst) is provided as the second argument to the map() function. So, the map() function will pass every element of lst to the lambda x:x function and return the elements.
Output:
Best Practices
Последние абзацы статьи будут посвящены лучшим решениям практических задач, с которыми так или иначе сталкивается Python-разработчик.
Как перевести список в другой формат?
Иногда требуется перевести список в строку, в словарь или в JSON. Для этого нужно будет вывести список без скобок.
Перевод списка в строку осуществляется с помощью функции join(). На примере это выглядит так:
В данном случае в качестве разделителя используется запятая.
Словарь в Python – это такая же встроенная структура данных, наряду со списком. Преобразование списка в словарь — задача тоже несложная. Для этого потребуется воспользоваться функцией . Вот пример преобразования:
JSON – это JavaScript Object Notation. В Python находится встроенный модуль для кодирования и декодирования данных JSON. С применением метода можно запросто преобразовать список в строку JSON.
Как узнать индекс элемента в списке?
Узнать позицию элемента в последовательности списка бывает необходимым, когда элементов много, вручную их не сосчитать, и нужно обращение по индексу. Для того, чтобы узнать индекс элемента, используют функцию .
В качестве аргумента передаем значение, а на выходе получаем его индекс.
Как посчитать количество уникальных элементов в списке?
Самый простой способ – приведение списка к (множеству). После этого останутся только уникальные элементы, которые мы посчитаем функцией
Как создать список числовых элементов с шагом
Создание списка числовых элементов с шагом может понадобиться не так и часто, но мы рассмотрим пример построения такого списка.
Шагом называется переход от одного элемента к другому. Если шаг отрицательный, произойдёт реверс массива, то есть отсчёт пойдёт справа налево. Вот так выглядит список с шагом.
Еще один вариант – воспользоваться генератором списков:
При разработке на языке Python, списки встречаются довольно часто. Знание основ работы со списками поможет быстро и качественно писать программный код .
Create an empty list in python using list() Constructor
Python’s list class provide a constructor,
list()
# Creating empty List using list constructor
sample_list = list()
print('Sample List: ', sample_list)
Sample List: []
Difference between [] and list()
We can create an empty list in python either by using [] or list(), but the main difference between these two approaches is speed. [] is way faster than list() because,
- list() requires a symbol lookup, as it might be possible that in our code, someone has assigned a new definition to list keyword.
- Extra function call: As constructor will be called, so it is an extra function call.
- Inside the constructor it checks if an iterable sequence is passed, if no then only it creates an empty list.
Whereas, [] is just a literal in python that always returns the same result i.e. an empty list. So, no additional name lookup or function call is required, which makes it much faster than list().
Вопрос 11. Как работает функция range?
Сложность: (ー_ー)
Функция range() генерирует три разных вида последовательностей из целых чисел и часто используется для быстрого создания списков — поэтому этот вопрос и попал в нашу подборку. Да и объяснять работу функции удобнее всего именно с помощью списка.
Последовательность от нуля до n
Используется range(n):
Функция range(n) сгенерировала последовательность от нуля до n (исключая n), а мы эту последовательность двумя способами обернули в список. Первый способ вы уже узнали — это генератор списков, а второй использует функцию list, которая превращает подходящий аргумент в список.
Попробуйте передать в range() отрицательное (-7) или дробное (3.14) число. Получится ли какой-нибудь список из этого, и если да, то какой?
Последовательность от n до m
Здесь в функцию range() нужно передать уже два аргумента: тогда range(n, m) сгенерирует целые числа от n до m (исключая m):
Последовательность от n до m с шагом k
Если в функцию range() передать три аргумента n, m, k, то она снова создаст последовательность от n до m (снова исключая m), но уже с шагом k:
Методы списков Python
Методы, которые доступны для работы со списками при программировании на Python, приведены в таблице ниже.
- append() — добавляет элемент в конец списка
- extend() — добавляет все элементы списка в другой список
- insert() — вставляет элемент по указанному индексу
- remove() — удаляет элемент из списка
- pop() — удаляет и возвращает элемент по указанному индексу
- clear() — удаляет все элементы из списка (очищает список)
- index() — возвращает индекс первого соответствующего элемента
- count() — возвращает количество элементов, переданных в качестве аргумента
- sort() — сортировка элементов в списке в порядке возрастания
- reverse() — обратный порядок элементов в списке
- copy() — возвращает поверхностную копию списка
Способы создания списка
Переходя к классическому примеру, создадим список, который в дальнейшем будем использовать и изменять. Существует несколько способов образования листингов.
Одним из них является применение встроенной функции list( ). Для этого нужно обработать любой объект, поддающийся итерации (строку, кортеж или же существующий список). В данном случае, строку.
Вот, что получается в исходе:
>>> list('список')
Второй пример показывает, что списки могут содержать неограниченное число самых разных объектов. Также листинг может оставаться пустым.
>>> s = [] # Пустой список >>> l = , 2] >>> s [] >>> l , 2]
Следующим, третьим, способом образования листингов является так называемый генератор листингов.
Генератор листингов – это синтаксическая конструкция для создания листингов. Она схожа с циклом for.
>>> c = >>> c
С его помощью можно также составлять более объемные конструкции:
>>> c = >>> c >>> c = >>> c
Однако такой способ генерации не всегда эффективен при составлении множества листингов. Поэтому целесообразно использовать для генерации листингов цикл for.
Если необходимо обратиться к какому-либо элементу из списка, то используются индексы. У каждого элемента свой индекс.
Индекс – это номер элемента в списке.
Если требуется наполнить листинг повторяющимися, одинаковыми элементами используется символ *. Например, нужно добавить в листинг три одинаковых числа: * 3.
Заключение ↑
Теперь вы знаете, как использовать два основных метода библиотеки pandas: и . Обладая этими знаниями, вы можете выполнять базовый анализ данных с помощью DataFrame. Хотя между этими двумя методами есть много общего, различие между ними позволяет понять, какой из них использовать для разных аналитических задач. В этом руководстве вы узнали, как:
- Сортировать Dataframe pandas по значениям одного или нескольких столбцов
- Использовать параметр , чтобы изменить порядок сортировки
- Сортировать DataFrame по индексу с помощью
- Упорядочивать недостающие данные при сортировке значений
- Сортировать DataFrame на месте, используя для параметра значение
Эти методы — значимая часть навыков анализа данных. Они помогут вам построить прочный фундамент, на котором можно выполнять более сложные операции с pandas. Если вы хотите увидеть несколько примеров более продвинутого использования методов сортировки pandas, документация pandas — отличный ресурс.
По мотивам Pandas Sort: Your Guide to Sorting Data in Python