Обзор протокола http
Содержание:
- Набор подсистем «Умные таблицы»
- HTTP-заголовки
- Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
- Этап поиска DNS
- HTML Ссылки
- HTML Теги
- URL¶
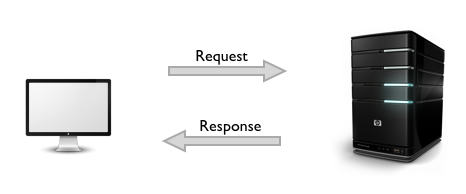
- Hyper Text Transfer Protocol
- Событие onprogress в деталях
- Summary of HTTP Methods for RESTful APIs
- Погружение в код
- Специфика HTTP
- HTML Справочник
- HTML Теги
- Подсистема «Показатели объектов»
- Вывод
Набор подсистем «Умные таблицы»
Данный набор подсистем – прикладная библиотека, призванная помочь программисту 1С быстрее решать ряд типовых задач бизнес-логики, таких как: ведение статусов объектов, отправка почтовых сообщений в определенное время, ведение произвольных таблиц с возможностью редактирования, сохранения и группировки, ориентированные на расчет бюджетных таблиц (план продаж, ретробонусы B2C, проценты по договорам B2B и договорные условия по КАМ), расчет коммерческой политики для бюджетных таблиц, исполнение произвольных алгоритмов с хранением кода в информационной базе, определение рабочих баз, хранение файлов во внешних СУБД (Postgre SQL, MS SQL и MongoDB) и выполнение произвольного кода после изменений ссылочного объекта вне транзакции изменения.
1 стартмани
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
Этап поиска DNS
Браузер запускает поиск DNS, чтобы получить IP-адрес сервера.
Доменное имя — удобный способ для нас, людей, но Интернет организован таким образом, что компьютеры могут искать точное местоположение сервера по его IP-адресу, который представляет собой набор чисел, например 222.324.3.1 (IPv4).
Во-первых, он проверяет локальный кэш DNS, чтобы узнать, был ли домен разрешен недавно.
В Chrome есть удобный визуализатор DNS-кэша, который вы можете увидеть в
Если там ничего не найдено, браузер использует распознаватель DNS, используя системный вызов gethostbyname POSIX для получения информации о хосте.
gethostbyname
Сначала gethostbyname просматривает локальный файл hosts, который в macOS или Linux находится в /etc/hosts , чтобы проверить, предоставляет ли система информацию локально.
Если это не дает никакой информации о домене, система отправляет запрос на DNS-сервер.
Адрес DNS-сервера сохраняется в системных настройках.
Это 2 популярных DNS-сервера:
- 8.8.8.8: публичный DNS-сервер Google
- 1.1.1.1: DNS-сервер CloudFlare
Большинство людей используют DNS-сервер, предоставленный их интернет-провайдером.
Браузер выполняет DNS-запрос по протоколу UDP.
TCP и UDP являются двумя основополагающими протоколами компьютерных сетей. Они находятся на том же концептуальном уровне, но TCP ориентирован на соединение, а UDP — это протокол без установления соединения, более легкий, используемый для отправки сообщений с небольшими издержками.
DNS-сервер может иметь IP-адрес домена в кэше. Если нет, он спросит корневой DNS-сервер . Это система (состоящая из 13 реальных серверов, распределенных по всей планете), которая управляет всем интернетом.
DNS-сервер не знает адреса каждого доменного имени на планете.
Он знает, где находятся DNS-преобразователи верхнего уровня .
Домен верхнего уровня — это расширение домена: .com , .it , .pizza и так далее.
Как только корневой DNS-сервер получает запрос, он перенаправляет запрос на этот DNS-сервер домена верхнего уровня (TLD).
Скажем, вы ищете ip-calculator.ru. DNS-сервер корневого домена возвращает IP-адрес TLD-сервера .ru.
Теперь наш распознаватель DNS будет кэшировать IP-адрес этого сервера TLD, поэтому ему не нужно будет снова запрашивать его у корневого DNS-сервера.
DNS-сервер TLD будет иметь IP-адреса официальных серверов имен для домена, который мы ищем.
Это DNS-серверы хостинг-провайдера. Их обычно больше 1, чтобы служить резервной копией.
Например:
- ns1.example.com
- ns2.example.com
- ns3.example.com
DNS-распознаватель запускается с первого и пытается запросить IP-адрес домена (также с поддоменом), который вы ищете.
Это основной источник правды для IP-адреса.
Теперь, когда у нас есть IP-адрес, мы можем продолжить наше путешествие.
HTML Ссылки
HTML по АлфавитуHTML по КатегориямHTML Атрибуты ТеговHTML Атрибуты ГлобалHTML Атрибуты СобытийHTML ЦветаHTML ХолстыHTML Аудио / ВидеоHTML Наборы символовHTML DOCTYPEsHTML Кодирование URLHTML Языковые кодыHTML Коды странHTTP Ответы сервераHTTP МетодыPX в EM конвертерГорячие клавиши
HTML Теги
<!—>
<!DOCTYPE>
<a>
<abbr>
<acronym>
<address>
<applet>
<area>
<article>
<aside>
<audio>
<b>
<base>
<basefont>
<bdi>
<bdo>
<big>
<blockquote>
<body>
<br>
<button>
<canvas>
<caption>
<center>
<cite>
<code>
<col>
<colgroup>
<data>
<datalist>
<dd>
<del>
<details>
<dfn>
<dialog>
<dir>
<div>
<dl>
<dt>
<em>
<embed>
<fieldset>
<figcaption>
<figure>
<font>
<footer>
<form>
<frame>
<frameset>
<h1> — <h6>
<head>
<header>
<hr>
<html>
<i>
<iframe>
<img>
<input>
<ins>
<kbd>
<label>
<legend>
<li>
<link>
<main>
<map>
<mark>
<menu>
<menuitem>
<meta>
<meter>
<nav>
<noframes>
<noscript>
<object>
<ol>
<optgroup>
<option>
<output>
<p>
<param>
<picture>
<pre>
<progress>
<q>
<rp>
<rt>
<ruby>
<s>
<samp>
<script>
<section>
<select>
<small>
<source>
<span>
<strike>
<strong>
<style>
<sub>
<summary>
<sup>
<svg>
<table>
<tbody>
<td>
<template>
<textarea>
<tfoot>
<th>
<thead>
<time>
<title>
<tr>
<track>
<tt>
<u>
<ul>
<var>
<video>
<wbr>
URL¶
См.также
https://ru.wikipedia.org/wiki/URL
URL (Uniform Resource Locator) – унифицированный указатель на ресурс.
Основным объектом манипуляции в HTTP является ресурс, на который указывает
URL в запросе клиента. Список всех доступных ресурсов сайта образуют дерево,
в котором каждая ветка будет являться адресом URL.
Дерево доступных ресурсов сайта
Ресурсы представляют из себя либо реальные файлы на сервере, например: HTML,
js, png, …, либо логические сущности, которые генерируют содержимое на лету
(в момент поступления запроса), например: список новостей, погода, фотогалерея,
каталог товаров и прочее. Соответственно такие ресурсы называют статическими
(неизменными) или динамическими.
Еще существуют абстрактные ресурсы, которые присутствуют в пути но этот
адрес самостоятельно не существует, например:
- http://example.com/ – главная страница сайта
- http://example.com/blog/ – список статей
- http://example.com/blog/article/1 – статья 1 в блоге
-
http://example.com/blog/article/ – абстрактный ресурс, который присутствует
в пути, но реально его не существует. По данной ссылке сервер вернет ошибку
404 Not Found. Такие ресурсы нужны для большей читаемости URL и
семантического разделения сущностей.
URI
См.также
- https://ru.wikipedia.org/wiki/URI
- URI,URL,URN
URL является подмножеством более широкого термина URI (Uniform Resource
Identifier), который обобщает вид различных идентификаторов.
Примеры URI:
ldap:///c=GB?objectClass?one mailto:John.Doe@example.com news:comp.infosystems.www.servers.unix tel:+1-816-555-1212 telnet://192.0.2.16:80/ ftp://ftp.is.co.za/rfc/rfc1808.txt http://www.ietf.org/rfc/rfc2396.txt urn:oasis:names:specification:docbook:dtd:xml:4.1.2
URN
См.также
https://ru.wikipedia.org/wiki/URN
URN (Uniform Resource Name) — идентифицирует путь до ресурса.
Пример:
- URI =
- URL = http://lectureskpd.readthedocs.io
- URN = /kpd/3.http.html
Идентификатор ресурса можно представить в виде формулы:
URI = URL + URN
Примечание
В обществе URI часто назвают как URL.
Структура URL
См.также
http://www.ietf.org/rfc/rfc3986.txt
Структура URL представлена на схеме ниже:
foo://example.com:8042/over/there?name=ferret#nose \_/ \______________/\_________/ \_________/ \__/ | | | | | схема имя(IP) и порт путь запрос элемент | _____________________|__ / \ / \ urn:example:animal:ferret:nose
<схема>://<логин>:<пароль>@<хост>:<порт>/<URN ‐ путь>?<параметры>#<якорь>
- ws
- ftp
- http
- https
- file
- mailto
- xmpp
<схема>://<логин>:<пароль>@<хост>:<порт>/<URN ‐ путь>?<параметры>#<якорь>
- user:123
- user
Адрес ресурса
<схема>://<логин>:<пароль>@ <хост>:<порт>/<URN ‐ путь>?<параметры>#<якорь>
- localhost:8080
- yandex.ru
- 213.180.204.11
- 127.0.0.1:6543
- yandex.ru:80
- 192.168.0.13:22
Пара <хост>:<порт> называется INET SOCKET или просто сокет, определяет
входную точку приложения и идентифицирует адрес по которому с ним можно
связаться.
HTTP по умолчанию использует порт 80, это знают веб-сервера, поэтому его можно не указывать.
<схема>://<логин>:<пароль>@<хост>:<порт>/<URN ‐ путь>?<параметры>#<якорь>
somedir/somefile.html
<схема>://<логин>:<пароль>@<хост>:<порт>/<URN ‐ путь>? <параметры>#<якорь>
text=foobar&from=fx3&lr=213
Якорь
<схема>://<логин>:<пароль>@<хост>:<порт>/<URN ‐ путь>?<параметры># <якорь>
someanchor
Якорь указывает на расположение в самом документе.
Пример якоря
Hyper Text Transfer Protocol
Интернет протокол HTTP — Hyper Text Transfer Protocol является протоколом передачи гипертекста. Он предназначен для передачи различной информации между клиентом и сервером и является символьно-ориентированным клиент-серверным протоколом.
Интернет протокол HTTP
В основе протокола лежит технология «клиент-сервер». Это предполагает наличие потребителей – клиентов. Клиенты инициализируют соединение и посылают запрос и наличие поставщиков – серверов. Сервер ждет соединения чтобы получить запрос, производит нужные операции и возвращает клиенту сообщение с результатом.
Всего было четыре версии протокола. Самый первый вариант интернет протокола HTTP 0.9 был выпущен в 1991 году и впервые издан в январе 1992 года. Он привел к урегулированию норм и правил взаимосвязи между клиентами и серверами HTTP, а соответственно к точному разграничению функций между этими элементами. Были запротоколированы основные синтаксические и семантические принципы и положения.
В феврале 2015 года вышли последние редакции черновика очередной версии протокола. Протокол HTTP 2 отличает от предшествующих протоколов то, что он является бинарным. Его основные ключевые особенности: мультиплексирование запросов, последовательность приоритетов для запросов, уплотнение заголовков. Можно загружать несколько элементов параллельно, при помощи одного TCP-соединения, поддержка push-уведомлений серверной стороны.
Событие onprogress в деталях
При обработке события есть ряд важных тонкостей.
Можно, конечно, их игнорировать, но лучше бы знать.
Заметим, что событие, возникающее при , имеет одинаковый вид на стадии отправки (в обработчике ) и при получении ответа (в обработчике ).
Оно представляет собой объект типа со свойствами:
-
Сколько байт уже переслано.
Имеется в виду только тело запроса, заголовки не учитываются.
-
Если , то известно полное количество байт для пересылки, и оно хранится в свойстве .
-
Общее количество байт для пересылки, если известно.
А может ли оно быть неизвестно?
- При отправке на сервер браузер всегда знает полный размер пересылаемых данных, так что всегда содержит конкретное количество байт, а значение всегда будет .
- При скачивании данных – обычно сервер в начале сообщает их общее количество в HTTP-заголовке . Но он может и не делать этого, например если сам не знает, сколько данных будет или если генерирует их динамически. Тогда будет равно . А чтобы отличить нулевой размер данных от неизвестного – как раз служит , которое в данном случае равно .
Ещё особенности, которые необходимо учитывать при использовании :
Событие происходит при каждом полученном/отправленном байте, но не чаще чем раз в 50 мс.
Это обозначено в .
В процессе получения данных, ещё до их полной передачи, доступен , но он не обязательно содержит корректную строку.
Можно до окончания запроса заглянуть в него и прочитать текущие полученные данные
Важно, что при пересылке строки в кодировке UTF-8 кириллические символы, как, впрочем, и многие другие, кодируются 2 байтами. Возможно, что в конце одного пакета данных окажется первая половинка символа, а в начале следующего – вторая
Поэтому полагаться на то, что до окончания запроса в находится корректная строка нельзя. Она может быть обрезана посередине символа.
Исключение – заведомо однобайтные символы, например цифры или латиница.
Сработавшее событие не гарантирует, что данные дошли.
Событие срабатывает, когда данные отправлены браузером. Но оно не гарантирует, что сервер получил, обработал и записал данные на диск. Он говорит лишь о самом факте отправки.
Поэтому прогресс-индикатор, получаемый при его помощи, носит приблизительный и оптимистичный характер.
Summary of HTTP Methods for RESTful APIs
The below table summarises the use of HTTP methods discussed above.
| HTTP Method | CRUD | Entire Collection (e.g. /users) | Specific Item (e.g. /users/123) |
|---|---|---|---|
| POST | Create | 201 (Created), ‘Location’ header with link to /users/{id} containing new ID. | Avoid using POST on single resource |
| GET | Read | 200 (OK), list of users. Use pagination, sorting and filtering to navigate big lists. | 200 (OK), single user. 404 (Not Found), if ID not found or invalid. |
| PUT | Update/Replace | 405 (Method not allowed), unless you want to update every resource in the entire collection of resource. | 200 (OK) or 204 (No Content). Use 404 (Not Found), if ID not found or invalid. |
| PATCH | Partial Update/Modify | 405 (Method not allowed), unless you want to modify the collection itself. | 200 (OK) or 204 (No Content). Use 404 (Not Found), if ID not found or invalid. |
| DELETE | Delete | 405 (Method not allowed), unless you want to delete the whole collection — use with caution. | 200 (OK). 404 (Not Found), if ID not found or invalid. |
Погружение в код
Если вы хотите следовать этому примеру, создайте новый HTML-документ и добавьте в него следующую разметку:
Внутри тега script добавьте следующий код, который составляет наш веб-запрос:
После того как вы добавили эти строки, сохраните изменения и протестируйте свою страницу в браузере. Вы ничего не увидите на экране, но если вы откроете консоль с помощью инструментов разработчика браузера, то увидите, как будет отображаться ваш IP-адрес:
Это уже что-то! Теперь, когда наш IP-адрес отображается на нашей консоли, давайте на минутку вернемся к коду и посмотрим, что именно он делает. С помощью нашей первой строки кода мы вызываем fetch и предоставляем URL-адрес, на который хотим сделать запрос:
URL-адрес, по которому мы отправляем наш запрос, таков ipinfo.io/json. Как только эта строка будет запущена, служба будет запущена ipinfo.io пришлет нам кое-какие данные. Это зависит от нас, чтобы обработать эти данные, и следующие два блока then отвечают за эту обработку:
Одна действительно важная деталь, которую следует упомянуть, заключается в том, что ответ, возвращаемый fetch, является обещанием. Эти блоки являются частью того, как обещания работают асинхронно, чтобы позволить нам обрабатывать результаты. Охват обещаний выходит за рамки этой статьи, но документация MDN отлично объясняет, что это такое.
На данный момент нужно знать, что у нас есть цепочка блоков then, где каждый блок вызывается автоматически после завершения предыдущего. Поскольку все это асинхронно, все это делается в то время, как остальная часть нашего приложения делает свое дело.
Нам не нужно делать ничего лишнего, чтобы убедиться, что наш код, связанный с запросом, не блокирует и не замораживает наше приложение в ожидании медленного результата работы сети или обработки большого объема данных.
Возвращаясь к коду, в нашем первом блоке then мы указываем, что нам нужны необработанные данные JSON, которые возвращает наш вызов fetch:
В следующем блоке then, который вызывается после завершения предыдущего, мы обрабатываем возвращенные данные дальше, сужая свойство, которое даст нам IP-адрес, и печатая его на консоли:
Как мы узнаем, что IP-адрес будет сохранен свойством ip из наших возвращенных данных Google? Самый простой способ-это обратиться к ipinfo.io документация разработчика! Каждый веб — сервис будет иметь свой собственный формат для возврата данных по запросу. Нам нужно потратить несколько минут и выяснить, как будет выглядеть ответ, какие параметры нам, возможно, потребуется передать в качестве части запроса, чтобы настроить ответ, и как нам нужно написать наш код, чтобы получить нужные данные.
В качестве альтернативы чтению документации разработчика вы всегда можете проверить ответ, возвращенный запросом, с помощью инструментов разработчика. Используйте тот подход, который вам удобен.
Мы еще не закончили с нашим кодом. Иногда обещание приводит к ошибке или неудачному ответу. Когда это произойдет, наше обещание перестанет идти вниз по цепочке блоков then и вместо этого будет искать блок catch. Then будет выполнен код в этом блоке catch. Наш блок catch выглядит следующим образом:
Мы не делаем ничего новаторского с нашей обработкой ошибок. Мы просто выводим сообщение об ошибке на консоль.
Специфика HTTP
Интернет протокол HTTP отличается от других протоколов тем, что создает отдельную TCP-сессию на любой запрос. В следующих версиях протокола было разрешено выполнять несколько запросов во время одной TCP-сессии. Но при этом браузеры, как правило, делают запрос только на страницу и находящиеся в ней объекты (изображения, таблицы стилей и так далее), а затем сразу прерывают TCP-сессию.
TCP/IP
Чтобы поддерживать авторизованный доступ в протоколе HTTP используются файлы cookies, представляющие собой небольшие части данных, отосланные веб-сервером и сохраняемые на компьютере в браузере. Веб-клиент, пытаясь открыть страницу нужного сайта посылает этот фрагмент информации веб-серверу в виде HTTP-запроса.
HTML Справочник
HTML Теги по алфавитуHTML Теги по категорииHTML ПоддержкаHTML АтрибутыHTML ГлобальныеHTML СобытияHTML Названия цветаHTML ХолстHTML Аудио/ВидеоHTML ДекларацииHTML Набор кодировокHTML URL кодHTML Коды языкаHTML Коды странHTTP СообщенияHTTP методыКовертер PX в EMКлавишные комбинации
HTML Теги
<!—…—>
<!DOCTYPE>
<a>
<abbr>
<acronym>
<address>
<applet>
<area>
<article>
<aside>
<audio>
<b>
<base>
<basefont>
<bdi>
<bdo>
<big>
<blockquote>
<body>
<br>
<button>
<canvas>
<caption>
<center>
<cite>
<code>
<col>
<colgroup>
<data>
<datalist>
<dd>
<del>
<details>
<dfn>
<dialog>
<dir>
<div>
<dl>
<dt>
<em>
<embed>
<fieldset>
<figcaption>
<figure>
<font>
<footer>
<form>
<frame>
<frameset>
<h1> — <h6>
<head>
<header>
<hr>
<html>
<i>
<iframe>
<img>
<input>
<ins>
<kbd>
<label>
<legend>
<li>
<link>
<main>
<map>
<mark>
<meta>
<meter>
<nav>
<noframes>
<noscript>
<object>
<ol>
<optgroup>
<option>
<output>
<p>
<param>
<picture>
<pre>
<progress>
<q>
<rp>
<rt>
<ruby>
<s>
<samp>
<script>
<section>
<select>
<small>
<source>
<span>
<strike>
<strong>
<style>
<sub>
<summary>
<sup>
<svg>
<table>
<tbody>
<td>
<template>
<textarea>
<tfoot>
<th>
<thead>
<time>
<title>
<tr>
<track>
<tt>
<u>
<ul>
<var>
<video>
<wbr>
Подсистема «Показатели объектов»
Если вашим пользователям нужно вывести в динамический список разные показатели, которые нельзя напрямую получить из таблиц ссылочных объектов, и вы не хотите изменять структуру справочников или документов — тогда эта подсистема для вас. С помощью нее вы сможете в пользовательском режиме создать свой показатель, который будет рассчитываться по формуле или с помощью запроса. Этот показатель вы сможете вывести в динамический список, как любую другую характеристику объекта. Также можно будет настроить отбор или условное оформление с использованием созданного показателя.
2 стартмани
Вывод
Написание некоторого кода, который делает HTTP-запрос и возвращает некоторые данные, вероятно, является одной из самых крутых вещей, которые вы можете сделать в JavaScript. Все, что вы здесь видели, было новинкой, которую в самом начале поддерживал только InternetExplorer.
Сегодня HTTP — запросы есть везде. Большая часть данных, которые вы видите на обычной странице, часто является результатом запроса, сделанного и обработанного — и все это без вашего ведома. Если вы создаете новое приложение или модернизируете старое, APIfetch-это хороший способ начать использовать его, если вашему приложению нужно сделать веб-запрос.
Поскольку значительная часть вашего времени будет посвящена чтению чужого кода, есть большая вероятность, что веб-запросы, с которыми вы столкнетесь, будут сделаны с использованием XMLHttpRequest. В таких случаях вам нужно знать свой путь. Вот почему эта статья была посвящена как новым подходам fetch, так и старым подходам XMLHttpRequest.