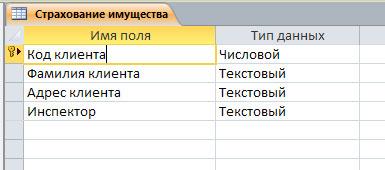
Создание связей по внешнему ключуcreate foreign key relationships
Содержание:
лМБУУЙЖЙЛБГЙС
рТПУФЩЕ Й УПУФБЧОЩЕ ЛМАЮЙ
рЕТЧЙЮОЩК ЛМАЮ НПЦЕФ УПУФПСФШ ЙЪ ЕДЙОУФЧЕООПЗП РПМС ФБВМЙГЩ, ЪОБЮЕОЙС ЛПФПТПЗП ХОЙЛБМШОЩ ДМС ЛБЦДПК ЪБРЙУЙ. фБЛ, ОБРТЙНЕТ, ОБ РТЕДРТЙСФЙЙ ОЕ НПЦЕФ ВЩФШ ДЧХИ ТБВПФОЙЛПЧ У ПДЙОБЛПЧЩНЙ ФБВЕМШОЩНЙ ОПНЕТБНЙ, РПЬФПНХ Ч ФБВМЙГЕ, УПДЕТЦБЭЕК ЪБРЙУЙ П ТБВПФОЙЛБИ, ФБВЕМШОЩК ОПНЕТ НПЦЕФ ВЩФШ РЕТЧЙЮОЩН ЛМАЮПН. фБЛПК РЕТЧЙЮОЩК ЛМАЮ ОБЪЩЧБАФ РТПУФЩН ЛМАЮПН.
еУМЙ ФБВМЙГБ ОЕ ЙНЕЕФ ЕДЙОУФЧЕООПЗП ХОЙЛБМШОПЗП РПМС, РЕТЧЙЮОЩК ЛМАЮ НПЦЕФ ВЩФШ УПУФБЧМЕО ЙЪ ОЕУЛПМШЛЙИ РПМЕК, УПЧПЛХРОПУФШ ЪОБЮЕОЙК ЛПФПТЩИ ЗБТБОФЙТХЕФ ХОЙЛБМШОПУФШ. фБЛ, ЙНС, ЖБНЙМЙС, ПФЮЕУФЧП, ОПНЕТ РБУРПТФБ, УЕТЙС РБУРПТФБ ОЕ НПЗХФ ВЩФШ РЕТЧЙЮОЩНЙ ЛМАЮБНЙ РП ПФДЕМШОПУФЙ, ФБЛ ЛБЛ НПЗХФ ПЛБЪБФШУС ПДЙОБЛПЧЩНЙ Х ДЧХИ Й ВПМЕЕ МАДЕК. оП ОЕ ВЩЧБЕФ ДЧХИ МЙЮОЩИ ДПЛХНЕОФПЧ ПДОПЗП ФЙРБ У ПДЙОБЛПЧЩНЙ УЕТЙЕК Й ОПНЕТПН. рПЬФПНХ Ч ФБВМЙГЕ, УПДЕТЦБЭЕК ЪБРЙУЙ П МАДСИ, РЕТЧЙЮОЩН ЛМАЮПН НПЦЕФ ВЩФШ ОБВПТ РПМЕК, УПУФПСЭЙК ЙЪ ФЙРБ МЙЮОПЗП ДПЛХНЕОФБ, ЕЗП УЕТЙЙ Й ОПНЕТБ. фБЛПК РЕТЧЙЮОЩК ЛМАЮ ОБЪЩЧБАФ УПУФБЧОЩН ЛМАЮПН (БОЗМ. compound key, composite key, concatenated key).
еУФЕУФЧЕООЩЕ Й УХТТПЗБФОЩЕ ЛМАЮЙ
рЕТЧЙЮОЩК ЛМАЮ НПЦЕФ УПУФПСФШ ЙЪ ЙОЖПТНБГЙПООЩИ РПМЕК ФБВМЙГЩ (ФП ЕУФШ РПМЕК, УПДЕТЦБЭЙИ РПМЕЪОХА ЙОЖПТНБГЙА ПВ ПРЙУЩЧБЕНЩИ ПВЯЕЛФБИ). фБЛПК РЕТЧЙЮОЩК ЛМАЮ ОБЪЩЧБАФ ЕУФЕУФЧЕООЩН ЛМАЮПН. фЕПТЕФЙЮЕУЛЙ, ЕУФЕУФЧЕООЩК ЛМАЮ ЧУЕЗДБ НПЦОП УЖПТНЙТПЧБФШ, Ч ЬФПН УМХЮБЕ НЩ РПМХЮЙН Ф. О. ЙОФЕММЕЛФХБМШОЩК ЛМАЮ. оБ РТБЛФЙЛЕ, ПДОБЛП, ЙУРПМШЪПЧБОЙЕ ЕУФЕУФЧЕООЩИ ЛМАЮЕК ОБФБМЛЙЧБЕФУС ОБ ПРТЕДЕМЈООЩЕ УМПЦОПУФЙ:
- оЙЪЛБС ЬЖЖЕЛФЙЧОПУФШ — еУФЕУФЧЕООЩК ЛМАЮ НПЦЕФ ВЩФШ ЧЕМЙЛ РП ТБЪНЕТХ (ПУПВЕООП ЛПЗДБ ПО УПУФБЧОПК), Й ЕЗП ЙУРПМШЪПЧБОЙЕ ПЛБЦЕФУС ФЕИОЙЮЕУЛЙ ОЕЬЖЖЕЛФЙЧОЩН (ЧЕДШ ЧП ЧУЕИ ФБВМЙГБИ, УЧСЪБООЩИ У ДБООПК, РПОБДПВЙФУС УПЪДБФШ РПМЕ ФПЗП ЦЕ ТБЪНЕТБ, ЮФПВЩ ИТБОЙФШ УУЩМЛЙ).
- оЕПВИПДЙНПУФШ ЛБУЛБДОЩИ ЙЪНЕОЕОЙК — рТЙ ЙЪНЕОЕОЙЙ ЪОБЮЕОЙС РПМС, ЧИПДСЭЕЗП Ч ЕУФЕУФЧЕООЩК ЛМАЮ, ПЛБЪЩЧБЕФУС ОЕПВИПДЙНЩН ЙЪНЕОЙФШ ЪОБЮЕОЙЕ РПМС ОЕ ФПМШЛП Ч ДБООПК ФБВМЙГЕ, ОП Й ЧП ЧУЕИ ФБВМЙГБИ, УЧСЪБООЩИ У ДБООПК, Ч РТПФЙЧОПН УМХЮБЕ ЧУЕ УУЩМЛЙ ОБ ДБООХА ЪБРЙУШ ПЛБЦХФУС ОЕЛПТТЕЛФОЩНЙ. ч УМПЦОЩИ ВБЪБИ ДБООЩИ ФБЛЙИ УЧСЪБООЩИ ФБВМЙГ НПЦЕФ ВЩФШ ПЮЕОШ НОПЗП, Й ЧУЕЗДБ ПУФБЈФУС ПРБУОПУФШ ХРХУФЙФШ ЙЪ ЧЙДХ ЛБЛХА-ФП ЙЪ ОЙИ. рТЙ ДПВБЧМЕОЙЙ ОПЧЩИ УЧСЪБООЩИ ФБВМЙГ РТЙИПДЙФУС ДПВБЧМСФШ УПЗМБУХАЭЙЕ ЙЪНЕОЕОЙС ЧП ЧУЕ НЕУФБ РТПЗТБНН, ЗДЕ РТБЧЙФУС ЙУИПДОБС ФБВМЙГБ.
- оЕУППФЧЕФУФЧЙЕ ТЕБМШОПУФЙ — хОЙЛБМШОПУФШ ЕУФЕУФЧЕООПЗП РЕТЧЙЮОПЗП ЛМАЮБ Ч ТЕБМШОЩИ вд ОЕ ЧУЕЗДБ УПВМАДБЕФУС. дПРХУФЙН, ОБРТЙНЕТ, ЮФП РЕТЧЙЮОЩК ЛМАЮ Ч ФБВМЙГЕ — ДБООЩЕ МЙЮОПЗП ДПЛХНЕОФБ. ч ФБЛХА ФБВМЙГХ ПЛБЦЕФУС ОЕЧПЪНПЦОЩН ЧОЕУФЙ ЮЕМПЧЕЛБ, П ДПЛХНЕОФБИ ЛПФПТПЗП ОЕФ ЙОЖПТНБГЙЙ Ч НПНЕОФ ДПВБЧМЕОЙС ЪБРЙУЙ, Б ОБ РТБЛФЙЛЕ ФБЛБС ОЕПВИПДЙНПУФШ НПЦЕФ ЧПЪОЙЛОХФШ.
чУМЕДУФЧЙЕ ЬФЙИ Й ДТХЗЙИ УППВТБЦЕОЙК Ч РТБЛФЙЛЕ РТПЕЛФЙТПЧБОЙС вд ЮБЭЕ ЙУРПМШЪХАФ Ф. О. УЙОФЕФЙЮЕУЛЙЕ (УХТТПЗБФОЩЕ) ЛМАЮЙ — ЙУЛХУУФЧЕООП УПЪДБООЩЕ ФЕИОЙЮЕУЛЙЕ ЛМАЮЕЧЩЕ РПМС, ОЕ ОЕУХЭЙЕ ЙОЖПТНБГЙЙ ПВ ПВЯЕЛФБИ.
нБФЕТЙБМ ЙЪ ЧЙЛЙРЕДЙЙ — УЧПВПДОПК ЬОГЙЛМПРЕДЙЙ
тБЪДЕМ: фЕПТЕФЙЮЕУЛЙЕ ПУОПЧЩ ВБЪ ДБООЩИ • ухвд
Добавляем таблицы в базу данных
Очевидно, что информация, в данный момент находящаяся в базе данных, является недостаточной, поскольку не известно, из каких пунктов состоит каждый заказ. Если помните, составляющие заказов были опущены сознательно, при этом мы обещали вернуться к этой проблеме позже. Пришло время распределить товары по заказам.
Проблема состоит в том, что заранее не известно, сколько пунктов содержит каждый заказ (аналогично тому, как заранее не известно, сколько заказов может разместить каждый из клиентов). Заказ может включать в себя один, два или даже сто товаров. Необходимо отделить информацию о том, что клиент сделал заказ, от деталей самого заказа. Следует попытаться создать нечто, подобное изображенному на рис. 2:
Рис. 2. Расширяем базу данных «Клиенты и заказы»
Как и при создании таблиц customer и orderinfo, разделим информацию на две таблицы, а затем объединим их. Правда при этом возникает одна небольшая проблема.
Если тщательно проанализировать отношения между заказом и отдельными товарами, станет ясно, что не только каждая запись из or- derinfo может быть связана со многими товарами, но и один и тот же товар может присутствовать во многих заказах (если несколько клиентов заказали один и тот же товар). Попытаемся изобразить эти две таблицы на диаграмме сущностей (рис. 3):
Рис. 3. Отношение между таблицами заказов и товаров
Представлено отношение «многие-ко-многим» — каждый заказ может ссылаться на множество товаров, и каждый товар может появляться во множестве заказов. Это подрывает некоторые из основ реляционных баз данных. Пока не будем вдаваться в детали, заметим только, что в реляционной базе данных никакие две таблицы не должны находится в отношениях «многие-ко-многим».
Можно попытаться обойти эту проблему, создав отдельную запись в каждой строке таблицы item для каждого заказа, но тогда придется многократно повторить описание и информацию о цене для каждого товара, что нарушило бы правило третье (удалять повторяющуюся информацию!).
Что касается нашей проблемы, то для нее существует стандартное решение. Необходимо создать третью таблицу между двумя существующими, она будет реализовывать отношение «многие-ко-многим». Надо сказать, что объяснять сложнее, чем делать, поэтому просто создадим эту третью таблицу, , которая свяжет заказы с товарами.
Создана таблица, строки которой соответствуют каждой строчке заказа (рис. 4). Для каждой отдельной строки можно определить, из какого она заказа, по столбцу , а товар, на который она ссылается, — по столбцу .
Один товар может присутствовать во многих строках таблицы , а один заказ также может встречаться в нескольких ее строках. Однако каждая строка промежуточной таблицы ссылается только на один товар и может присутствовать только в одном заказе.
Рис. 4. Добавление в базу данных таблицы
Обратите внимание, что в новую таблицу не введен уникальный идентификатор для каждой строки. Дело в том, что комбинация orderin- fo_id и всегда уникальна
Но и здесь есть одна почти незаметная проблема. Что произойдет, если клиент закажет два экземпляра товара в одном заказе?
Просто ввести еще одну строку в нельзя, поскольку комбинация и должна быть уникальной. Неужели придется добавить еще одну специальную таблицу для обслуживания заказов, содержащих несколько экземпляров одного товара? К счастью, нет. Есть гораздо более простой способ. Надо просто ввести поле «количество» (quantity) в таблицу , и все будет хорошо.
Проектирование базы данных
Основой любой реляционной БД являются
таблицы. Разработка таблиц является одним из наиболее сложных этапов в
проектировании БД. Грамотно спроектированные таблицы являются основой для
создания работоспособной и эффективной БД.
Понятие таблицы в Access полностью соответствует аналогичному
понятию реляционной модели данных. Любая таблица реляционной БД состоит из строк
(называемых также записями) и столбцов (называемых
также полями).
Строки таблицы содержат сведения об
однотипных объектах — документах, людях, предметах. На пересечении столбца и
строки находится конкретное значение, характеризующее объект.
Можно сформулировать ряд основных
требований, которым должны удовлетворять таблицы.
1. Информация в таблице не должна
дублироваться, т.е. в таблице не должно существовать двух записей с полностью
совпадающим набором значений ее полей.
2. На пересечении любого столбца и
любой строки должно находиться одно
значение.
3. Не рекомендуется включать в
таблицу данные, которые являются результатом вычислений.
4. Значения данных в одном и том же
столбце должны принадлежать к одному и тому же типу, доступному для
использования в данной СУБД.
5. Каждое поле должно иметь уникальное
имя.
6. Каждая таблица должна иметь
первичный ключ.
7. Таблицы БД должны быть связаны
через внешние ключи.
Каждая таблица должна содержать поле
(или набор из нескольких полей), значения в котором однозначно идентифицируют
каждую запись в таблице. Такое поле (или набор полей) называется ключевым полем
таблицы или первичным ключом. Первичный ключ любой таблицы обязан
содержать уникальные непустые значения для каждой записи. Если
для таблицы обозначены ключевые поля, то Access предотвращает дублирование или ввод пустых значений в ключевое поле.
В Access можно выделить три типа ключевых полей: простой ключ, составной
ключ и поле счетчика.
Если поле содержит уникальные значения,
такие как коды или инвентарные номера, то это поле можно определить как простой
первичный ключ. Если в этом поле появятся повторяющиеся или пустые
значения, Access выведет сообщение об ошибке.
В случаях, когда невозможно
гарантировать уникальность значений ни одного из полей, можно создать ключ,
состоящий из нескольких полей — составной первичный ключ. Для
составного ключа существенным может оказаться порядок образующих ключ полей. Не
рекомендуется определять ключ по полям Имена и Фамилии, поскольку нельзя исключить
повторения этой пары значений для разных людей.
Составной ключ необходим для таблицы,
используемой для связывания двух таблиц в отношении «многие — ко — многим»
Обычно такой ключ состоит из ключевых полей связываемых таблиц.
Если для какой-либо таблицы не удалось
определить простой первичный ключ или найти подходящий набор полей для
составного ключа, можно добавить в таблицу поле счетчика и
сделать его ключевым. При создании каждой новой записи Access генерирует уникальный номер записи,
называемый счетчиком. Указание такого поля в качестве ключевого
является наиболее простым способом создания ключевых полей.
Если до сохранения созданной таблицы
ключевые поля не были определены, то при сохранении будет выдано предложение о
создании системой ключевого поля. При ответе Да будет создано ключевое
поле счетчика.
Сила реляционных баз данных, таких как
БД Microsoft Access, заключается в том, что они могут быстро найти и связать данные
из разных таблиц при помощи запросов, форм и отчетов. Таблицы реляционных БД
связываются через одинаковые значения одноименных полей, содержащихся в
связываемых таблицах. Такие поля называются внешним ключом для
этих таблиц. Все таблицы БД Access должны
быть связаны с помощью внешних ключей.
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.
Хорошая практика для первичных ключей в таблицах
- Первичные ключи должны быть настолько маленькими, насколько это необходимо. Предпочитайте числовой тип, потому что числовые типы хранятся в гораздо более компактном формате, чем символьные форматы.
- Первичные ключи никогда не должны меняться.
- Не используйте номер паспорта, номер социального страхования или номер контракта сотрудника в качестве «первичного ключа», так как эти «первичные ключи» могут меняться в реальных ситуациях.
Пример:
Предположим, мы собираемся создать таблицу с именем ‘agent1’. Он содержит столбцы и типы данных, которые показаны ниже. Для каждой строки таблицы ‘agent1’ требуется идентифицировать каждого агента с помощью уникального кода, поскольку имена двух или более агентов в городе страны могут совпадать.
Так что не стоит создавать PRIMARY KEY для ‘agent_name’. ‘Agent_code’ может быть единственным и исключительным выбором для PRIMARY KEY для этой таблицы.
| Имя поля | Тип данных | Размер | Десятичные знаки | НОЛЬ | скованность |
|---|---|---|---|---|---|
| agent_code | голец | 6 | нет | ОСНОВНОЙ КЛЮЧ | |
| имя агента | голец | 40 | нет | ||
| рабочая область | голец | 35 | да | ||
| комиссия | десятичный | 10 | 2 | да | |
| номер телефона | голец | 17 | да |
При создании таблицы вы можете включить первичный ключ, используя ограничение первичного ключа на уровне столбца или ограничение на уровне таблицы. Вот два примера на упомянутой таблице:
Ограничение первичного ключа на уровне столбца:
Код SQL:
Ограничение первичного ключа на уровне таблицы:
Код SQL:
Что такое нормализация
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.
1.2.5. Первичный ключ
Мы уже достаточно много говорили про ключевые поля, но ни разу их не использовали. Самое интересное, что все работало. Это преимущество, а может недостаток базы данных Microsoft SQL Server и MS Access. В таблицах Paradox такой трюк не пройдет и без наличия ключевого поля таблица будет доступна только для чтения.
В какой-то степени ключи являются ограничениями, и их можно было рассматривать вместе с оператором CHECK, потому что объявление происходит схожим образом и даже используется оператор CONSTRAINT. Давайте посмотрим на этот процесс на примере. Для этого создадим таблицу из двух полей «guid» и «vcName». При этом поле «guid» устанавливается как первичный ключ:
CREATE TABLE Globally_Unique_Data ( guid uniqueidentifier DEFAULT NEWID(), vcName varchar(50), CONSTRAINT PK_guid PRIMARY KEY (Guid) )
Самое вкусное здесь это строка CONSTRAINT. Как мы знаем, после этого ключевого слова идет название ограничения, и объявления ключа не является исключением. Для именования первичного ключа, я рекомендую использовать именование типа PK_имя, где имя – это имя поля, которое должно стать главным ключом. Сокращение PK происходит от Primary Key (первичный ключ).
После этого, вместо ключевого слова CHECK, которое мы использовали в ограничениях, стоит оператор PRIMARY KEY, Именно это указывает на то, что нам необходима не проверка, а первичный ключ. В скобках указывается одно, или несколько полей, которые будут составлять ключ.
Помните, что в ключевом поле не может быть одинакового значения у двух строк, в этом ограничение первичного ключа идентично ограничению уникальности. Это значит, что если сделать поле для хранения фамилии первичным ключом, то в такую таблицу нельзя будет записать двух Ивановых с разными именами. Это нарушает ограничение первичного ключа. Именно поэтому ключи являются ограничениями и объявляются также как и ограничение CHECK. Но это не верно только для первичных ключей и вторичных с уникальностью.
В данном примере, в качестве первичного ключа выступает поле типа uniqueidentifier (GUID). Значение по умолчанию для этого поля – результат выполнения серверной процедуры NEWID.
Внимание
Только один первичный ключ может быть создан для таблицы
Для простоты примеров, в качестве ключа желательно использовать численный тип и если позволяет база данных, то будет лучше, если он будет типа «autoincrement» (автоматически увеличивающееся/уменьшающееся число). В MS SQL Server таким полем является IDENTITY, а в MS Access это поле типа «счетчик».
Следующий пример показывает, как создать таблицу товаров, в которой в качестве первичного ключа выступает целочисленное поле с автоматическим увеличением:
CREATE TABLE Товары ( id int IDENTITY(1, 1), товар varchar(50), Цена money, Количество numeric(10, 2), CONSTRAINT PK_id PRIMARY KEY (id) )
Именно такой тип ключа мы будем использовать чаще всего, потому что в ключевом поле будут храниться легкие для восприятия числа и с ними проще и нагляднее работать.
Первичный ключ может состоять из более, чем одной колонки. Следующий пример создает таблицу, в которой поля «id» и «Товар» образуют первичный ключ, а значит, будет создан индекс уникальности на оба поля:
CREATE TABLE Товары1
(
id int IDENTITY(1, 1),
Товар varchar(50),
Цена money,
Количество numeric(10, 2),
CONSTRAINT PK_id PRIMARY KEY
(id, )
)
Очень часто программисты создают базу данных с ключевым полем в виде целого числа, но при этом в задаче четко стоит, что определенные поля должны быть уникальными. А почему не создать сразу первичный ключ из тех полей, которые должны быть уникальны и не надо будет создавать отдельные решения для данной проблемы.
Единственный недостаток первичного ключа из нескольких колонок – проблемы создания связей. Тут приходиться выкручиваться различными методами, но проблема все же решаема. Достаточно только ввести поле типа uniqueidentifier и производить связь по нему. Да, в этом случае у нас получаются уникальными первичный ключ и поле типа uniqueidentifier, но эта избыточность в результате не будет больше, чем та же таблица, где первичный ключ uniqueidentifier, а на поля, которые должны быть уникальными установлено ограничение уникальности. Что выбрать? Зависит от конкретной задачи и от того, с чем вам удобнее работать.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| user1 | {Кузнецов В., отдел маркетинга} |
|---|---|
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл.бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства: быстрый поиск и простое масштабирование.
Недостатки: нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
Выводы
- Если по каким-либо критериям, указанным в начале статьи, возникла надобность использовать GUID в качестве первичного ключа — наилучшим вариантом в плане производительности будет последовательный GUID, сгенерированный для каждой записи на клиенте.
- Если создание GUID на клиенте по каким-либо причинам неприемлемо — можно воспользоваться генерацией идентификатора на стороне базы через NEWSEQUENTIALID(). Entity Framework делает это по умолчанию для GUID ключей, генерируемых на стороне базы. Но следует учесть, что производительность вставки будет заметно меньше по сравнению с созданием идентификатора на стороне клиента. Для проектов, где количество вставок в таблицы невелико, эта разница не будет критична. Еще, скорее всего, этот оверхед можно избежать в сценариях, где не нужно сразу же получать идентификатор вставленной записи, но такое решение не будет универсальным.
- Если в вашем проекте уже используются непоследовательные GUID, то следует задуматься об исправлении, если количество вставок в таблицы велико и размер базы значительно больше, чем размер доступной оперативной памяти.
- У других СУБД разница в производительности может быть совершенно другой, поэтому полученные результаты можно рассматривать только применительно к Microsoft SQL Server. В то время как базовые критерии, указанные в начале статьи, справедливы независимо от конкретной СУБД.