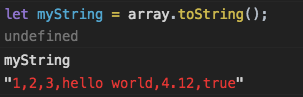
Функция split() модуля re в python
Содержание:
- Таблица «Функции и методы строк»
- Определение текущего потока
- Работа с часовыми поясами
- Python split String Syntax
- Синхронизация потоков
- Python f-строки: особенности использования
- Ограничение одновременного доступа к ресурсам
- Поиск символов и текста
- Как создать строку
- Метод after() — Погружение в сон для Tkinter
- Операции со строками
- Строки байтов — bytes и bytearray
Таблица «Функции и методы строк»
| Функция или метод | Назначение |
|---|---|
| S = ‘str’; S = «str»; S = »’str»’; S = «»»str»»» | Литералы строк |
| S = «s\np\ta\nbbb» | Экранированные последовательности |
| S = r»C:\temp\new» | Неформатированные строки (подавляют экранирование) |
| S = b»byte» | Строка байтов |
| S1 + S2 | Конкатенация (сложение строк) |
| S1 * 3 | Повторение строки |
| S | Обращение по индексу |
| S | Извлечение среза |
| len(S) | Длина строки |
| S.find(str, ,) | Поиск подстроки в строке. Возвращает номер первого вхождения или -1 |
| S.rfind(str, ,) | Поиск подстроки в строке. Возвращает номер последнего вхождения или -1 |
| S.index(str, ,) | Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError |
| S.rindex(str, ,) | Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError |
| S.replace(шаблон, замена) | Замена шаблона на замену. maxcount ограничивает количество замен |
| S.split(символ) | Разбиение строки по разделителю |
| S.isdigit() | Состоит ли строка из цифр |
| S.isalpha() | Состоит ли строка из букв |
| S.isalnum() | Состоит ли строка из цифр или букв |
| S.islower() | Состоит ли строка из символов в нижнем регистре |
| S.isupper() | Состоит ли строка из символов в верхнем регистре |
| S.isspace() | Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы (‘\f’), «новая строка» (‘\n’), «перевод каретки» (‘\r’), «горизонтальная табуляция» (‘\t’) и «вертикальная табуляция» (‘\v’)) |
| S.istitle() | Начинаются ли слова в строке с заглавной буквы |
| S.upper() | Преобразование строки к верхнему регистру |
| S.lower() | Преобразование строки к нижнему регистру |
| S.startswith(str) | Начинается ли строка S с шаблона str |
| S.endswith(str) | Заканчивается ли строка S шаблоном str |
| S.join(список) | Сборка строки из списка с разделителем S |
| ord(символ) | Символ в его код ASCII |
| chr(число) | Код ASCII в символ |
| S.capitalize() | Переводит первый символ строки в верхний регистр, а все остальные в нижний |
| S.center(width, ) | Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию) |
| S.count(str, ,) | Возвращает количество непересекающихся вхождений подстроки в диапазоне (0 и длина строки по умолчанию) |
| S.expandtabs() | Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам |
| S.lstrip() | Удаление пробельных символов в начале строки |
| S.rstrip() | Удаление пробельных символов в конце строки |
| S.strip() | Удаление пробельных символов в начале и в конце строки |
| S.partition(шаблон) | Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки |
| S.rpartition(sep) | Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку |
| S.swapcase() | Переводит символы нижнего регистра в верхний, а верхнего – в нижний |
| S.title() | Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний |
| S.zfill(width) | Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями |
| S.ljust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar |
| S.rjust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar |
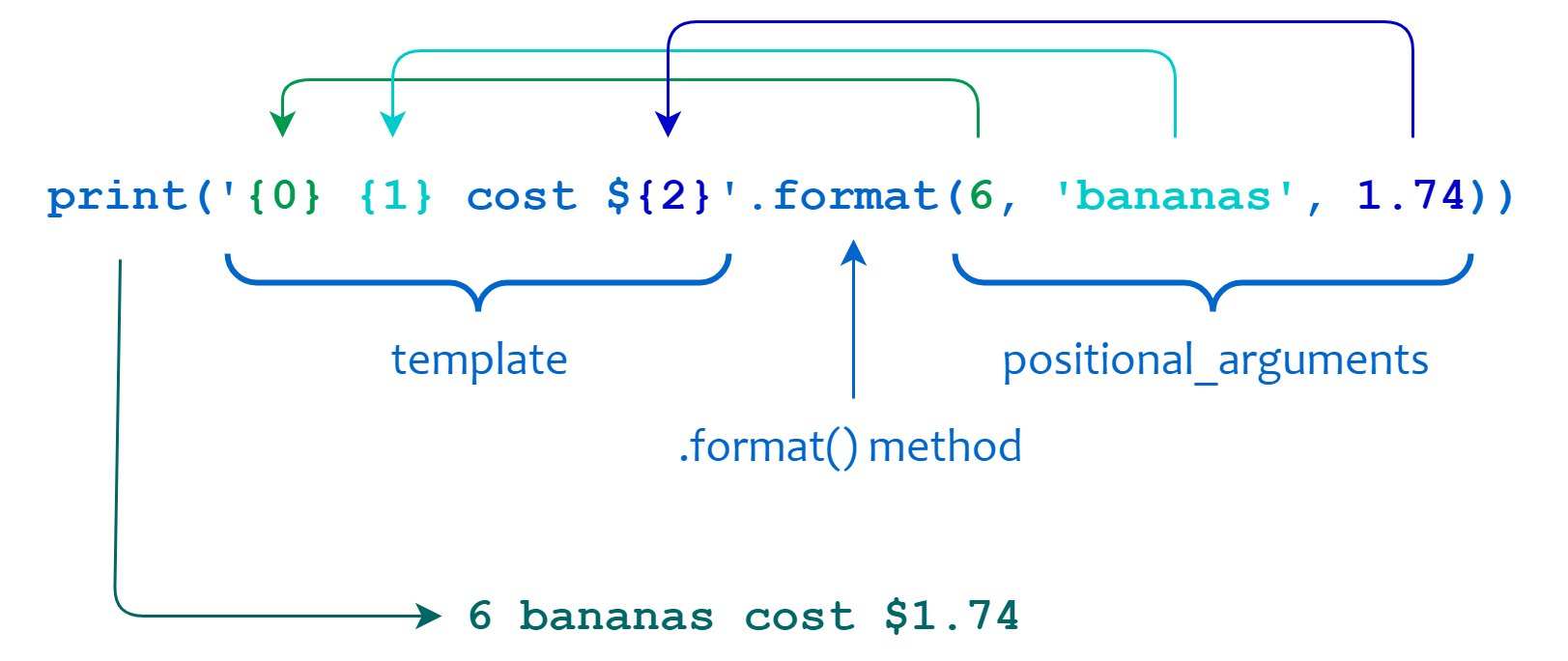
| S.format(*args, **kwargs) | Форматирование строки |
Определение текущего потока
Использование аргументов для идентификации потока является трудоемким процессом. Каждый экземпляр Thread имеет имя со значением, присваиваемым по умолчанию. Оно может быть изменено, когда создается поток.
Именование потоков полезно в серверных процессах с несколькими служебными потоками, обрабатывающими различные операции.
import threading
import time
def worker():
print threading.currentThread().getName(), 'Starting'
time.sleep(2)
print threading.currentThread().getName(), 'Exiting'
def my_service():
print threading.currentThread().getName(), 'Starting'
time.sleep(3)
print threading.currentThread().getName(), 'Exiting'
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # используем имя по умолчанию
w.start()
w2.start()
t.start()
Программа выводит имя текущего потока в каждой строке. «Thread-1» — это безымянный поток w2.
$ python -u threading_names.py worker Thread-1 Starting my_service Starting Starting Thread-1worker Exiting Exiting my_service Exiting
Большинство программ не используют print для отладки. Модуль logging поддерживает добавление имени потока в каждое сообщение журнала с помощью % (threadName)s. Включение имен потоков в журнал облегчает отслеживание этих сообщений.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format=' (%(threadName)-10s) %(message)s',
)
def worker():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
def my_service():
logging.debug('Starting')
time.sleep(3)
logging.debug('Exiting')
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # use default name
w.start()
w2.start()
t.start()
Модуль logging также является поточно-ориентированным, поэтому сообщения из разных потоков сохранятся в выводимых данных.
$ python threading_names_log.py (worker ) Starting (Thread-1 ) Starting (my_service) Starting (worker ) Exiting (Thread-1 ) Exiting (my_service) Exiting
Работа с часовыми поясами
Выбор функции для определения текущего времени зависит от того, установлен ли часовой пояс программой или системой. Изменение часового пояса не изменяет фактическое время — только способ его представления.
Чтобы изменить часовой пояс, установите переменную среды TZ, затем вызовите tzset(). Часовой пояс можно указать с различными данными, вплоть до времени начала и завершения периода так называемого «летнего» времени. Проще всего использовать название часового пояса, но базовые библиотеки получают и другую информацию.
Приведенная ниже программа без time sleep python, и задает несколько разных значений для часового пояса и показывает, как изменения влияют на другие настройки в модуле времени:
time_timezone.py
import time
import os
def show_zone_info():
print(' TZ :', os.environ.get('TZ', '(not set)'))
print(' tzname:', time.tzname)
print(' Zone : {} ({})'.format(
time.timezone, (time.timezone / 3600)))
print(' DST :', time.daylight)
print(' Time :', time.ctime())
print()
print('Default :')
show_zone_info()
ZONES = [
'GMT',
'Europe/Amsterdam',
]
for zone in ZONES:
os.environ = zone
time.tzset()
print(zone, ':')
show_zone_info()
Часовой пояс по умолчанию для системы, используемой в примерах — US / Eastern. Другие зоны в примере, который позволяет реализовать модуль time Python изменяют значение tzname, продолжительности светового дня и значение смещения часового пояса:
$ python3 time_timezone.py
Default :
TZ : (not set)
tzname: ('EST', 'EDT')
Zone : 18000 (5.0)
DST : 1
Time : Sun Aug 14 14:10:42 2016
GMT :
TZ : GMT
tzname: ('GMT', 'GMT')
Zone : 0 (0.0)
DST : 0
Time : Sun Aug 14 18:10:42 2016
Europe/Amsterdam :
TZ : Europe/Amsterdam
tzname: ('CET', 'CEST')
Zone : -3600 (-1.0)
DST : 1
Time : Sun Aug 14 20:10:42 2016
Python split String Syntax
The syntax of the Python String split function is
- String_Value: A valid String variable, or you can use the String directly.
- Separator (Optional arg): If you forget this argument, the python split string function uses Empty Space as the separator.
- Max_Split: This argument is optional. If you specify this value then, split function restricts the list of words.
Python split function returns a List of words. For example, If we have X*Y*Z and If we use * as a separator, split function search for * from left to right. Once the split function finds *, Python returns the string before the * symbol as List Item 1 (X) so on and so forth.
If you add Max_Split argument to the above example, X*Y*Z.split(‘*’, 1), python split function search for *. Once it finds *, the split function returns the string before the * symbol as List Item 1 (X) and returns the remaining string as list item 2.
Синхронизация потоков
Другой способ синхронизации потоков – объект Condition. Поскольку Condition использует Lock, его можно привязать к общему ресурсу. Это позволяет потокам ожидать обновления ресурса.
В приведенном ниже примере поток consumer() будет ждать, пока не будет установлено Condition, прежде чем продолжить. Поток producer() отвечает за установку Condition и уведомление других потоков о том, что они могут продолжить выполнение.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
def consumer(cond):
"""wait for the condition and use the resource"""
logging.debug('Starting consumer thread')
t = threading.currentThread()
with cond:
cond.wait()
logging.debug('Resource is available to consumer')
def producer(cond):
"""set up the resource to be used by the consumer"""
logging.debug('Starting producer thread')
with cond:
logging.debug('Making resource available')
cond.notifyAll()
condition = threading.Condition()
c1 = threading.Thread(name='c1', target=consumer, args=(condition,))
c2 = threading.Thread(name='c2', target=consumer, args=(condition,))
p = threading.Thread(name='p', target=producer, args=(condition,))
c1.start()
time.sleep(2)
c2.start()
time.sleep(2)
p.start()
Потоки используют with для блокировки, связанной с Condition. Использование методов acquire() и release()в явном виде также работает.
$ python threading_condition.py 2013-02-21 06:37:49,549 (c1) Starting consumer thread 2013-02-21 06:37:51,550 (c2) Starting consumer thread 2013-02-21 06:37:53,551 (p ) Starting producer thread 2013-02-21 06:37:53,552 (p ) Making resource available 2013-02-21 06:37:53,552 (c2) Resource is available to consumer 2013-02-21 06:37:53,553 (c1) Resource is available to consumer
Python f-строки: особенности использования
Теперь, когда вы узнали все о том, почему f-строки великолепны, я уверен, что вы захотите начать их использовать. Вот несколько деталей, о которых нужно помнить, когда вы отправляетесь в этот дивный новый мир.
Кавычки
Вы можете использовать различные типы кавычек внутри выражений. Просто убедитесь, что вы не используете кавычки того же типа на внешней стороне f-строки, которые вы используете в выражении.
Этот код будет работать:
>>> f"{'Eric Idle'}"
'Eric Idle'
Этот код также будет работать:
>>> f'{"Eric Idle"}'
'Eric Idle'
Вы также можете использовать тройные кавычки:
>>> f"""Eric Idle""" 'Eric Idle'
>>> f'''Eric Idle''' 'Eric Idle'
Если вам нужно использовать одинаковый тип кавычки как внутри, так и снаружи строки, вы можете сделать это с помощью \:
>>> f"The \"comedian\" is {name}, aged {age}."
'The "comedian" is Eric Idle, aged 74.'
Словари
Говоря о кавычках, следите, когда вы работаете со словарями. Если вы собираетесь использовать одинарные кавычки для ключей словаря, то не забудьте убедиться, что вы используете двойные кавычки для f-строк, содержащих ключи.
>>> comedian = {'name': 'Eric Idle', 'age': 74}
>>> f"The comedian is {comedian}, aged {comedian}."
The comedian is Eric Idle, aged 74.
Пример с синтаксической ошибкой:
>>> comedian = {'name': 'Eric Idle', 'age': 74}
>>> f'The comedian is {comedian}, aged {comedian}.'
File "<stdin>", line 1
f'The comedian is {comedian}, aged {comedian}.'
^
SyntaxError: invalid syntax
Если вы используете тот же тип кавычки вокруг ключей словаря, что и на внешней стороне f-строки, то кавычка в начале первого ключа словаря будет интерпретироваться как конец строки.
Фигурные скобки
Чтобы в скобках появилась скобка, вы должны использовать двойные скобки:
>>> f"`74`"
'{74}'
Обратите внимание, что использование тройных скобок приведет к тому, что в вашей строке будут только одиночные скобки:
>>> f"{`74`}"
'{74}'
Тем не менее, вы можете получить больше фигурных скобок, если вы используете больше, чем тройные фигурные скобки:
>>> f"{{`74`}}"
'`74`'
Обратный слеш
Как вы видели ранее, вы можете использовать обратные слэши в строковой части f-строки. Однако вы не можете использовать обратную косую черту для экранирования части выражения f-строки:
>>> f"{\"Eric Idle\"}"
File "<stdin>", line 1
f"{\"Eric Idle\"}"
^
SyntaxError: f-string expression part cannot include a backslash
Вы можете обойти это, предварительно посчитав выражение и используя результат в f-строке:
>>> name = "Eric Idle"
>>> f"{name}"
'Eric Idle'
Выражения не должны содержать комментарии, использующие символ #. Используя это вы получите синтаксическую ошибку:
>>> f"Eric is {2 * 37 #Oh my!}."
File "<stdin>", line 1
f"Eric is {2 * 37 #Oh my!}."
^
SyntaxError: f-string expression part cannot include '#'
Ограничение одновременного доступа к ресурсам
Как разрешить доступ к ресурсу нескольким worker одновременно, но при этом ограничить их количество. Например, пул соединений может поддерживать фиксированное число одновременных подключений, или сетевое приложение может поддерживать фиксированное количество одновременных загрузок. Semaphore является одним из способов управления соединениями.
import logging
import random
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
class ActivePool(object):
def __init__(self):
super(ActivePool, self).__init__()
self.active = []
self.lock = threading.Lock()
def makeActive(self, name):
with self.lock:
self.active.append(name)
logging.debug('Running: %s', self.active)
def makeInactive(self, name):
with self.lock:
self.active.remove(name)
logging.debug('Running: %s', self.active)
def worker(s, pool):
logging.debug('Waiting to join the pool')
with s:
name = threading.currentThread().getName()
pool.makeActive(name)
time.sleep(0.1)
pool.makeInactive(name)
pool = ActivePool()
s = threading.Semaphore(2)
for i in range(4):
t = threading.Thread(target=worker, name=str(i), args=(s, pool))
t.start()
В этом примере класс ActivePool является удобным способом отслеживания того, какие потоки могут запускаться в данный момент. Реальный пул ресурсов будет выделять соединение для нового потока и восстанавливать значение, когда поток завершен. В данном случае он используется для хранения имен активных потоков, чтобы показать, что только пять из них работают одновременно.
$ python threading_semaphore.py 2013-02-21 06:37:53,629 (0 ) Waiting to join the pool 2013-02-21 06:37:53,629 (1 ) Waiting to join the pool 2013-02-21 06:37:53,629 (0 ) Running: 2013-02-21 06:37:53,629 (2 ) Waiting to join the pool 2013-02-21 06:37:53,630 (3 ) Waiting to join the pool 2013-02-21 06:37:53,630 (1 ) Running: 2013-02-21 06:37:53,730 (0 ) Running: 2013-02-21 06:37:53,731 (2 ) Running: 2013-02-21 06:37:53,731 (1 ) Running: 2013-02-21 06:37:53,732 (3 ) Running: 2013-02-21 06:37:53,831 (2 ) Running: 2013-02-21 06:37:53,833 (3 ) Running: []
Поиск символов и текста
Метод include? позволяет проверить, есть ли в строке искомая строка. Если она есть, он возвращает true, а если нет – false.
Метод index возвращает индекс искомого символа. Также он может определить индекс первого символа подстроки. При запросе несуществующего символа он возвращает nil.
Метод index находит только первое совпадение.
Строка содержит и другие символы «о», но метод выводит только первое совпадение.
Чтобы найти другие совпадения, можно преобразовать строку в массив и использовать методы массивов для итерации по полученному массиву и поиска других совпадений.
Помимо поиска символов в строке, вы можете проверить, начинается ли строка с символа или подстроки, используя start_with? метод:
Метод start_with? принимает несколько строк и возвращает true, если совпадает хотя бы одна из них
Вы можете использовать метод end_with? чтобы узнать, заканчивается ли строка указанной подстрокой. Он работает точно так же, как start_with?:
Как создать строку
Строки всегда создаются одним из трех способов. Вы можете использовать одинарные, двойные и тройные скобки. Давайте посмотрим
Python
my_string = «Добро пожаловать в Python!»
another_string = ‘Я новый текст тут…’
a_long_string = »’А это у нас
новая строка
в троичных скобках»’
|
1 2 3 4 5 6 |
my_string=»Добро пожаловать в Python!» another_string=’Я новый текст тут…’ a_long_string=»’А это у нас новая строка |
Строка с тремя скобками может быть создана с использованием трех одинарных скобок или трех двойных скобок. Так или иначе, с их помощью программист может писать строки в нескольких линиях. Если вы впишете это, вы увидите, что выдача сохраняет разрыв строк. Если вам нужно использовать одинарные скобки в вашей строке, то впишите двойные скобки. Давайте посмотрим на пример:
Python
my_string = «I’m a Python programmer!»
otherString = ‘Слово «Python» обычно подразумевает змею’
tripleString = «»»В такой «строке» мы можем ‘использовать’ все.»»»
|
1 2 3 |
my_string=»I’m a Python programmer!» otherString=’Слово «Python» обычно подразумевает змею’ tripleString=»»»В такой «строке» мы можем ‘использовать’ все.»»» |
Данный код демонстрирует то, как вы можете вписать одинарные или двойные скобки в строку. Существует еще один способ создания строки, при помощи метода str. Как это работает:
Python
my_number = 123
my_string = str(my_number)
|
1 2 |
my_number=123 my_string=str(my_number) |
Если вы впишете данный код в ваш интерпретатор, вы увидите, что вы изменили значение интегратора на строку и присвоили ее переменной my_string. Это называется кастинг, или конвертирование. Вы можете конвертировать некоторые типы данных в другие, например числа в строки. Но вы также заметите, что вы не всегда можете делать обратное, например, конвертировать строку вроде ‘ABC’ в целое число. Если вы сделаете это, то получите ошибку вроде той, что указана в этом примере:
Python
int(‘ABC’)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
ValueError: invalid literal for int() with base 10: ‘ABC’
|
1 2 3 4 5 |
int(‘ABC’) Traceback(most recent call last) File»<string>»,line1,in<fragment> ValueErrorinvalid literal forint()withbase10’ABC’ |
Мы рассмотрели обработку исключений в другой статье, но как вы могли догадаться из сообщения, это значит, что вы не можете конвертировать сроки в цифры. Тем не менее, если вы вписали:
Python
x = int(«123»)
| 1 | x=int(«123») |
То все должно работать
Обратите внимание на то, что строка – это один из неизменных типов Python. Это значит, что вы не можете менять содержимое строки после ее создания
Давайте попробуем сделать это и посмотрим, что получится:
Python
my_string = «abc»
my_string = «d»
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: ‘str’ object does not support item assignment
|
1 2 3 4 5 6 |
my_string=»abc» my_string=»d» Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeError’str’objectdoes notsupport item assignment |
Здесь мы пытаемся изменить первую букву с «а» на «d«, в итоге это привело к ошибке TypeError, которая не дает нам сделать это. Теперь вы можете подумать, что присвоение новой строке то же значение и есть изменение строки. Давайте взглянем, правда ли это:
Python
my_string = «abc»
a = id(my_string)
print(a) # 19397208
my_string = «def»
b = id(my_string)
print(b) # 25558288
my_string = my_string + «ghi»
c = id(my_string)
print(c) # 31345312
|
1 2 3 4 5 6 7 8 9 10 11 |
my_string=»abc» a=id(my_string) print(a)# 19397208 my_string=»def» b=id(my_string) print(b)# 25558288 my_string=my_string+»ghi» c=id(my_string) print(c)# 31345312 |
Проверив id объекта, мы можем определить, что когда мы присваиваем новое значение переменной, то это меняет тождество
Обратите внимание, что в версии Python, начиная с 2.0, строки могут содержать только символы ASCII. Если вам нужен Unicode, тогда вы должны вписывать u перед вашей строкой
Пример:
Python
# -*- coding: utf-8 -*-
my_unicode_string = u»Это юникод!»
|
1 2 |
# -*- coding: utf-8 -*- my_unicode_string=u»Это юникод!» |
В Python, начиная с версии 3, все строки являются юникодом.
Метод after() — Погружение в сон для Tkinter
tkinter является частью стандартной библиотеки Python. В случае, если вы используете заранее установленную версию Python на Linux или Mac, он может быть вам недоступен. При получении ошибки стоит самостоятельно добавить его в систему. В том случае, если вы ранее установили Python сами, должен быть доступен.
Начнем с разбора примера, где используется . Запустите следующий код и посмотрите, что произойдет при неправильном добавлении вызова в Python:
Python
import tkinter
import time
class MyApp:
def __init__(self, parent):
self.root = parent
self.root.geometry(«400×400″)
self.frame = tkinter.Frame(parent)
self.frame.pack()
b = tkinter.Button(text=»click me», command=self.delayed)
b.pack()
def delayed(self):
time.sleep(3)
if __name__ == «__main__»:
root = tkinter.Tk()
app = MyApp(root)
root.mainloop()
|
1 15 |
importtkinter importtime classMyApp def__init__(self,parent) self.root=parent self.root.geometry(«400×400») self.frame=tkinter.Frame(parent) self.frame.pack() b=tkinter.Button(text=»click me»,command=self.delayed) b.pack() defdelayed(self) if__name__==»__main__» root=tkinter.Tk() app=MyApp(root) root.mainloop() |
После запуска кода нажмите кнопку в GUI. Кнопка не будет реагировать три секунды, ожидая завершения . Если в приложении есть другие кнопки, на них тоже нельзя будет нажать. Закрыть приложение во время сна нельзя, так как оно не будет откликаться на событие закрытия.
Для должного погружения в сон потребуется использовать :
Python
import tkinter
class MyApp:
def __init__(self, parent):
self.root = parent
self.root.geometry(«400×400»)
self.frame = tkinter.Frame(parent)
self.frame.pack()
self.root.after(3000, self.delayed)
def delayed(self):
print(‘Я задержался’)
if __name__ == «__main__»:
root = tkinter.Tk()
app = MyApp(root)
root.mainloop()
|
1 10 |
importtkinter classMyApp def__init__(self,parent) self.root=parent self.root.geometry(«400×400») self.frame=tkinter.Frame(parent) self.frame.pack() defdelayed(self) print(‘Я задержался’) if__name__==»__main__» root=tkinter.Tk() app=MyApp(root) root.mainloop() |
Здесь создается приложение, высота которого 400 пикселей, и ширина также 400 пикселей. На нем нет виджетов. Оно только показывает фрейм. Затем вызывается , где является отсылкой к объекту . принимает два аргумента:
- Количество миллисекунд для сна;
- Метод который вызовется после завершения сна.
В данном случае приложение выведет строку в стандартный поток вывода (stdout) через 3 секунды. Можно рассматривать как Tkinter-версию того же , только он добавляет способность вызова функции после завершения сна.
Данную функциональность можно использовать для улучшения работы пользователя. Добавив в Python вызов , можно ускорить процесс загрузки приложения, после чего начать какой-то длительный процесс. В таком случае пользователю не придется ждать открытия приложения.
Операции со строками
Последнее обновление: 23.04.2017
Строка представляет последовательность символов в кодировке Unicode, заключенных в кавычки. Причем в Python мы можем использовать как одинарные, так и двойные кавычки:
name = "Tom" surname = 'Smith' print(name, surname) # Tom Smith
Одной из самых распространенных операций со строками является их объединение или конкатенация. Для объединения строк применяется знак плюса:
name = "Tom" surname = 'Smith' fullname = name + " " + surname print(fullname) # Tom Smith
С объединением двух строк все просто, но что, если нам надо сложить строку и число? В этом случае необходимо привести число к строке с помощью функции
str():
name = "Tom" age = 33 info = "Name: " + name + " Age: " + str(age) print(info) # Name: Tom Age: 33
Эскейп-последовательности
Кроме стандартных символов строки могут включать управляющие эскейп-последовательности, которые интерпретируются особым образом.
Например, последовательность \n представляет перевод строки. Поэтому следующее выражение:
print("Время пришло в гости отправится\nждет меня старинный друг")
На консоль выведет две строки:
Время пришло в гости отправится ждет меня старинный друг
Тоже самое касается и последовательности \t, которая добавляет табляцию.
Кроме того, существуют символы, которые вроде бы сложно использовать в строке. Например, кавычки. И чтобы отобразить кавычки (как двойные, так и одинарные)
внутри строки, перед ними ставится слеш:
print("Кафе \"Central Perk\"")
Сравнение строк
Особо следует сказать о сравнении строк
При сравнении строк принимается во внимание символы и их регистр. Так, цифровой символ условно меньше, чем любой алфавитный символ
Алфавитный символ в верхнем регистре условно меньше, чем алфавитные символы в нижнем регистре. Например:
str1 = "1a" str2 = "aa" str3 = "Aa" print(str1 > str2) # False, так как первый символ в str1 - цифра print(str2 > str3) # True, так как первый символ в str2 - в нижнем регистре
Поэтому строка «1a» условно меньше, чем строка «aa». Вначале сравнение идет по первому символу. Если начальные символы обоих строк представляют цифры, то
меньшей считается меньшая цифра, например, «1a» меньше, чем «2a».
Если начальные символы представляют алфавитные символы в одном и том же регистре, то смотрят по алфавиту. Так, «aa» меньше, чем «ba», а «ba» меньше, чем «ca».
Если первые символы одинаковые, в расчет берутся вторые символы при их наличии.
Зависимость от регистра не всегда желательна, так как по сути мы имеем дело с одинаковыми строками. В этом случае перед сравнением мы можем
привести обе строки к одному из регистров.
Функция lower() приводит строку к нижнему регистру, а функция upper() — к верхнему.
str1 = "Tom" str2 = "tom" print(str1 == str2) # False - строки не равны print(str1.lower() == str2.lower()) # True
НазадВперед
Строки байтов — bytes и bytearray
Определение которое мы дале в самом начале можно считать верным только для строк типа str. Но в Python имеется еще два дугих типа строк: bytes – неизменяемое строковое представление двоичных данных и bytearray – тоже что и bytes, только допускает непосредственное изменение.
Основное отличие типа str от bytes и bytearray заключается в том, что str всегда пытается превратить последовательность байтов в текст указанной кодировки. По умолчанию этой кодировкой является utf-8, но это очень большая кодировка и другие кодировки, например ASCII, Latin-1 и другие являются ее подмножествами
Одни символы кодируются одним байтом, другие двумя, а некоторые тремя и функция при декодировании последовательности байтов принимает это во внимание. А вот функциям и до этого нет дела, для них абсолютно все данные состоят только из последовательности одиночных байтов.
Такое поведение bytes и bytearray очень удобно, если вы работаете с изображениями, аудиофайлами или сетевым трафиком. В этом случае, вам следует знать, что ничего магического в этих типах нет, они поддерживоют все теже строковые методы, операции индексирования, а так же операторы и функции для работы с последовательностями. Единственное, что следует держать в уме, так это то, что вы имеете дело с последовательностью байтов, т.е. последовательностью чисел из интервала в шестнадцатеричном представлении, и что байтовые строки отличаются от обычных символом (реже) предваряющим все литералы обычных строк.
Например, что бы создать строку типа bytes или bytearray достаточно передать соответствующим функциям последовательности целых чисел:
Учитывая то, что для кодирования некоторых символов (например ASCII) достаточно всего одного байта, данные типы пытаются представить последовательности в виде символов если это возможно. Например, строка будет выведена как :
А это значит, что байтовые данные могут вполне обоснованно интерпретированться как ASCII символы и наоборот. Т.е. строки байтов могут быть созданы и так:
Но, следует помнить что это все-таки байты, в чем легко убедиться, если мы обратимся к какому-нибудь символу по его индексу в строке:
Так как строковые методы не изменяют сам объект, а создают новый, то при работе с очень длинными строками (а в мире двоичных данных это далеко не редкость) это может привести к большому расходу памяти. Собственно, по этой причине и существует тип bytearray, который позволяет менять байты прямо внутри строки: