Полное руководство по robots.txt и метатегу noindex
Содержание:
- Understanding Robots Meta Tag Attributes and Directives
- NOFOLLOW в ссылках
- The different robots meta tag values
- Директивы Meta Robots, которые стоит использовать в SEO
- Robots.txt & Meta Robots Tags Work Together
- What are robot meta tags?
- Что такое noindex
- What is noindex nofollow?
- Проверка правильности Meta Robots и его содержимого в Netpeak Spider
- Indexation-controlling parameters:
- Метатеги для поисковых систем
- Как закрыть внешние ссылки от индексации
- Мета-тег
- Лучшие примеры использования
- Выводы
Understanding Robots Meta Tag Attributes and Directives
Using robots meta tags is quite simple once you understand how to set the two attributes: name and content. Both of these attributes are required, so you must set a value for each.
Let’s take a look at these attributes in more detail.
Name
The name attribute controls that crawlers and bots (user-agents, also referred to as UA) should follow the instructions contained within the robots meta tag.
To instruct all crawlers to follow the instructions, use:
name=»robots»
In most scenarios, you’ll want to use this as default, but you can use as many different meta robots tags as needed to specify instructions to different crawlers.
When instructing different crawlers, it’s simply a case of using multiple tags:
There are hundreds of different user-agents. The most common ones are:
- : Googlebot (you can see a full list of Google crawlers here)
- Bing: Bingbot (you can see a full list of Bing crawlers here)
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Yandex: YandexBot
Content
The content attribute is what you use to give the instructions to the specified user-agent.
It’s important to know that if you do not specify a meta robots tag on a web page, the default is to index the page and to follow all of the links (unless they have a rel=»nofollow» attribute specified inline).
The different directives that you can use includes:
- index (include the page in the index) [Note: you do not need to include this if noindex is not specified, it is assumed as index)
- noindex (do not include the page in the index or show on the SERPs)
- follow (follow the links on the page to discover other pages)
- nofollow (do not follow the links on the page)
- none (a shortcut to specify noindex, nofollow)
- all (a shortcut to specify index, follow)
- noimageindex (do not index the images on the page)
- noarchive (do not show a cached version of the page on the SERPs)
- nocache (this is the same as noarchive, but only for MSN)
- nositelinkssearchbox (do not show a search box for your site on the SERPs)
- nopagereadaloud (do not allow voice services to read your page aloud)
- notranslate (do not show translations of the page on the SERPs)
- unavailable_after (specify a time after which the page should not be indexed)
You can see a full list of the directives that Google supports here and the ones that Bing supports here.
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Остановимся подробнее на распределении и передаче веса в Google.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Выдержка из раздела Помощь Яндекса:
Выдержка из раздела Справка Google:
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е
в теге , но и везде, на что только хватает фантазии. И в теге
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге , и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку
Теперь уделим внимание тегу noindex.
The different robots meta tag values
The following values (‘parameters’) can be placed on their own, or together in the attribute of tag (separated by a comma), to control how search engines interact with your page.
Scroll down for an overview of which search engines support which specific parameters.
- index
- Allow search engines to add the page to their index, so that it can be discovered by people searching.
- Note: When there are no directives relating to indexing, this is assumed to be the default.
- noindex
- Disallow search engines from adding this page to their index, and therefore disallow them from showing it in their results.
- Note: Informal messaging from Google suggests that, if a page is set to for a long period of time, it may also be treated as if it were also set to . The precise mechanics of this are unclear, and it’s unclear whether other search engines behave similarly.
- follow
- Tells the search engines that it may follow links on the page, to discover other pages.
- Note: When there are no directives relating to following links, this is assumed to be the default.
- nofollow
- Tells the search engines robots not to ‘endorse’ (pass equity through) any links on the page. Note that this includes all links on the page, including, e.g., those in navigation elements, links to images or other resources, and so on.
- Note: It’s unclear (and inconsistent between search engines) whether this attribute prevents search engines from following links, or just prevents them from assigning any value to those links.
- none
- A shortcut for .
- all
- A shortcut for .
- Note: This is assumed by default on all pages, and does nothing if specified.
- noimageindex
- Disallow search engines from indexing images on the page.
- Note: If images are linked to directly from elsewhere, search engines can still index them, so using an X-Robots-Tag HTTP header is generally a better idea.
- noarchive
- Prevents the search engines from showing a cached copy of this page in their search results listings.
- nocache
- Same as , but only used by MSN/Live.
- nosnippet
- Prevents the search engines from showing a text or video snippet (i.e., a ) of this page in the search results, and prevents them from showing a cached copy of this page in their search results listings.
- Note: Snippets may still show an image thumbnail, unless is also used.
- nositelinkssearchbox
- Prevents the search engine from showing an inline search box for your site.
- nopagereadaloud
- Prevents the search engine from reading your page’s content aloud via voice services/results.
- notranslate
- Prevents search engines from showing translations of the page in their search results.
- max-snippet:
- Sets a maximum number of characters for the meta description.
- Note: Omitting this tag may result in an implied value of . A default value of should be set to imply ‘no limit’.
- max-video-preview:
- Sets a maximum number of seconds for a video in a preview.
- Note: Omitting this tag may result in an implied value of . A default value of should be set to imply ‘no limit’.
- max-image-preview:
- Sets a maximum image size for use in a preview (, or ).
- Note: Omitting this tag may result in an implied value of .
- rating
- Indicates that a page contains adult material.
- unavailable_after
- Tells search engines a date/time after which they should not show it in search results; a ‘timed’ version of .
- Note: Must be in format (e.g., ).
- noyaca
- Prevents the search results snippet from using the page description from the Yandex Directory.
- Note: Only supported by Yandex.
noydir- Blocks Yahoo from using the description for this page in the Yahoo directory as the snippet for your page in the search results.
- Note: Since Yahoo closed its directory this tag is deprecated, but you might come across it once in awhile.
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Для решения проблемы вам следует использовать инструкцию следующего вида:
Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска. К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов
Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке html-документа следующую директиву:
Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Robots.txt & Meta Robots Tags Work Together
One of the biggest mistakes I see when working on my client’s websites is when the robots.txt file doesn’t match what you’ve stated in the meta robots tags.
For example, the robots.txt file hides the page from indexing, but the meta robots tags do the opposite.
Remember the example from Leadfeeder I showed above?
So, you’ll notice that this thank you page is disallowed in the robots.txt file and using the meta robots tags of noindex, nofollow.
In my experience, Google has given priority to what is prohibited by the robots.txt file.
But, you can eliminate non-compliance between meta robots tags and robots.txt by clearly telling search engines which pages should be indexed, and which should not.
Robots meta directives (sometimes called «meta tags») are pieces of code that provide crawlers instructions for how to crawl or index web page content. Whereas robots.txt file directives give bots suggestions for how to crawl a website’s pages, robots meta directives provide more firm instructions on how to crawl and index a page’s content.
There are two types of robots meta directives: those that are part of the HTML page (like the meta robotstag) and those that the web server sends as HTTP headers (such as x-robots-tag). The same parameters (i.e., the crawling or indexing instructions a meta tag provides, such as «noindex» and «nofollow» in the example above) can be used with both meta robots and the x-robots-tag; what differs is how those parameters are communicated to crawlers.
Meta directives give crawlers instructions about how to crawl and index information they find on a specific webpage. If these directives are discovered by bots, their parameters serve as strong suggestions for crawler indexation behavior. But as with robots.txt files, crawlers don’t have to follow your meta directives, so it’s a safe bet that some malicious web robots will ignore your directives.
Below are the parameters that search engine crawlers understand and follow when they’re used in robots meta directives. The parameters are not case-sensitive, but do note that it is possible some search engines may only follow a subset of these parameters or may treat some directives slightly differently.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
What is noindex nofollow?
means that a web page shouldn’t be indexed by search engines and therefore shouldn’t be shown on the search engine’s result pages. means that search engines spiders shouldn’t follow the links on that page. You can add these values to your robots meta tag. The robots meta tag is a piece of code in the head section of a web page. It tells search engines how to crawl and whether to index a page.
Our ultimate guide on the robots meta tag is a great read if you want to take a bit of a deeper dive into this subject.
In short:
- The robots meta tag looks like this in most cases:
- VALUE1 and VALUE2 are set to by default, meaning the page at hand can be indexed by search engines and links on that page can be followed to crawl the pages they link to.
- VALUE1 and VALUE2 can be set to or another combination like .
But don’t let this code scare you away. Yoast SEO helps you out! If you want to know how to a post in WordPress, in a super-easy way, you should read this post: How to noindex a post in WordPress: the easy way.
But when should you use which value?
Проверка правильности Meta Robots и его содержимого в Netpeak Spider
Перед проверкой атрибутов Meta Robots важно узнать, какие страницы индексируются на сайте, иначе не будет смысла внедрять вышеописанные атрибуты. Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке
Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений
Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке. Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений.
Воспользуйтесь промокодом при оформлении заказа и получите специальную скидку 10% на покупку Netpeak Spider и Netpeak Checker!
С помощью Netpeak Spider вы можете найти запрещённые к индексации страницы. На таких страницах программа делает особый акцент, отмечая ошибками:
- Заблокировано в Meta Robots. Показывает страницы, запрещённые к индексации с помощью инструкции в блоке .
- Nofollow в Meta Robots. Показывает страницы, содержащие инструкции в блоке .
Для проверки сайта откройте программу и перейдите на вкладку «Параметры» на боковой панели. Найдите раздел «Индексация» и проверьте, отмечен ли галочкой пункт «Meta Robots». Если пункт не будет отмечен, программа не проанализирует метатег, и вы в финальном отчёте не увидите данных о нём.
Для сканирования всего сайта введите его начальный URL в адресную строку и нажмите кнопку «Старт». Если вам необходимо просканировать список страниц, зайдите в меню «Список URL» и выберите удобный вам способ добавления URL (ввести вручную, загрузить из файла или Sitemap, вставить из буфера обмена), после чего запустите сканирование.
По завершению сканирования получить информацию о Meta Robots вы можете несколькими путями:
1. В основной таблице на вкладке «Все результаты». В столбце Meta Robots просмотрите директивы, которые содержатся в соответствующем теге каждой из просканированных страниц.
2. На вкладке «Ошибки» боковой панели. Найдите ошибки, связанные с Meta Robots, и кликните по их названию. В таблице отфильтрованных результатов вы увидите полный список страниц, на которых были найдены эти ошибки.
3. На вкладке «Дашборд». Вы можете просмотреть данные в виде диаграмм об индексируемых страницах на сайте, а также узнать причины их неиндексируемости. Кликните на интересующую вас область, чтобы получить список страниц, соответствующих тому или иному значению.
4. На вкладке «Сводка» на боковой панели. Здесь вы можете ознакомиться как закрытыми от индексации страницами, так и посмотреть, какие ещё значения помимо noindex, nofollow заданы в метатеге Robots. Найдите пункт «Meta Robots» со списком всех имеющихся на сайте директив. Кликните на любую из них, чтобы ознакомиться со страницами, на которых они были найдены.
При необходимости вы можете воспользоваться функцией «Экспорт», чтобы выгрузить отфильтрованные результаты в отдельный файл формата на свой компьютер. Нажмите на кнопку «Экспорт» в левом верхнем углу над результатами сканирования или выберите в соответствующем меню команду «Результаты в текущей таблице».
Indexation-controlling parameters:
-
Noindex: Tells a search engine not to index a page.
-
Index: Tells a search engine to index a page. Note that you don’t need to add this meta tag; it’s the default.
-
Follow: Even if the page isn’t indexed, the crawler should follow all the links on a page and pass equity to the linked pages.
-
Nofollow: Tells a crawler not to follow any links on a page or pass along any link equity.
-
Noimageindex: Tells a crawler not to index any images on a page.
-
None: Equivalent to using both the noindex and nofollow tags simultaneously.
-
Noarchive: Search engines should not show a cached link to this page on a SERP.
-
Nocache: Same as noarchive, but only used by Internet Explorer and Firefox.
-
Nosnippet: Tells a search engine not to show a snippet of this page (i.e. meta description) of this page on a SERP.
-
Noodyp/noydir : Prevents search engines from using a page’s DMOZ description as the SERP snippet for this page. However, DMOZ was retired in early 2017, making this tag obsolete.
-
Unavailable_after: Search engines should no longer index this page after a particular date.
Метатеги для поисковых систем
Robots
Метатег указывает роботам поисковых систем, как сканировать и индексировать страницу.
Для конкретного бота можно задать свою инструкцию. Например, заменить robots на Googlebot для Гугла или на YandexBot для Яндекса.
Возможные указания:
- all – означает, что разрешена индексация и переход по ссылкам, аналогично index, follow;
- noindex – запрет индексации;
- index – разрешена индексация;
- nofollow – нельзя переходить по ссылкам;
- follow – можно переходить по ссылкам;
- noarchive – запрещено показывать ссылку на сохраненную копию в выдаче;
- noyaca – (для Яндекса) не использовать для сниппета описание из Яндекс.Каталога;
- nosnippet – (в Google) нельзя использовать для сниппета фрагмент текста и показывать видео;
- noimageindex – (в Google) запрет указания страницы как источника изображения;
- unavailable_after: – (в Google) после указанной даты будет прекращено сканирование и индексирование страницы;
- none – запрет индексации и перехода по ссылкам, аналогичен noindex, nofollow.
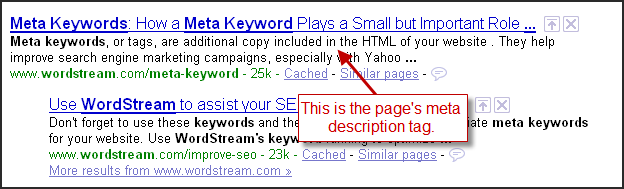
Description
Метатег name=«description» может использоваться поисковыми системами при формировании сниппета, поэтому он должен:
- точно описывать содержание страницы;
- вызывать желание кликнуть;
- включать продвигаемое ключевое слово.
В разных поисковых системах выводятся 160–240 символов.
Description для каждой продвигаемой страницы должен быть уникальным.
Keywords
Метатег name=«keywords» раньше использовался поисковыми системами при ранжировании, но из-за многочисленных манипуляций его значимость постоянно уменьшалась. Теперь большинство поисковиков его игнорируют. Google не поддерживает вообще, а Яндекс пишет, что может учитывать. Но на практике keywords давно не оказывает влияния, а его некорректное заполнение может привести к переспаму.
Существуют три подхода:
- оставлять пустым;
- писать конкретные фразы или отдельные слова через запятую;
- указать через пробел бессвязный набор слов, из которых могут быть составлены ключевые фразы.
Если принято решение прописать ключевые слова, важно не допускать спама. Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте
Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте.
Title
Title технически не является метатегом, но его часто относят к этой группе, потому что он содержит информацию, которая используется поисковыми системами и браузерами.
Данный HTML-тег важен для SEO: влияет на ранжирование и кликабельность по сниппету.
Классические рекомендации по заполнению метатега:
- использовать главное продвигаемое ключевое слово на странице;
- разместить ключ вначале;
- обеспечить уникальность внутри сайта;
- сделать привлекательным для пользователя;
- подобрать такую длину, чтобы заголовок не обрезался в сниппете.
Рекомендуема длина – 70–80 символов.
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex
Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя
Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.. Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега
Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт
Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации
Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс
На этом сегодня всё, всем удачи и до новых встреч!
Мета-тег
Начнем с базовых пониманий. Мета-тег — это служебная информация для страницы, которая указывается в документе в верхнем блоке <head></head> с HTML разметкой.
Что такое мета-тег robots?
В нашем случае, мета-тег с атрибутом name=“robots” дает указание роботам всех поисковых систем, без исключения. Так же, есть name=“googlebot”, виден только Google, и name=“yandex”, соответственно только для Yandex поисковика.
В коде это выглядит так:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Атрибут content может принимать такие параметры как:
- “noindex” — ставит запрет на индексацию контента, но ссылки в документе все еще видны для поисковых роботов и открыты для просмотров и переходов на них
- “nofollow” — закрывает все ссылки на данной странице от индексации. Это касается как внешних, так и внутренних.
Варианты использования meta тега robots с noindex и nofollow
Возможны такие варианты использования:
<meta name="robots" content="index, follow"/> <!-- — включена индексация страницы и ссылок. Стоит по умолчанию для каждого сайта. --> <meta name="robots" content="noindex, follow"/> <!-- — запрет на индексацию контента страницы, но разрешен переход и просмотр ссылок. --> <meta name="robots" content="index, nofollow"/> <!-- — включена индексация, но запрещен переход и просмотр ссылок. --> <meta name="robots" content="noindex, nofollow"/> <!-- — запрет на индексацию и переход по ссылкам страницы. -->
Перечисленные варианты также можно использовать для скрытия от определенных поисковых систем, таких как Yandex и Google. Возможные варианты атрибута name видно выше, а в коде это может выглядеть так:
<meta name="googlebot" content="noindex, follow" />.
Стоит подбирать комбинацию атрибутов четко под свои цели и задачи. Давайте рассмотрим некоторые из них.
Когда нам нужен мета-тег “robots” со значением “noindex” или “nofollow”?
Мета-тег следует использовать на следующих страницах:
- со служебной информацией(админ. панель, логи сервера);
- дублирующийся контент(пагинация, архивы, теги).
А также в случаях:
- когда следует закрыть страницу от индексирования, но оставить возможность просматривать ссылки;
- когда хотите удалить документ из index и не допустить просмотра ссылок поисковыми роботами;
- когда нужно закрыть переход по ссылкам уже индексированного документа.
Рекомендуем
Операторы поиска Google
Подробнее
Лучшие примеры использования
- Добавление директивы sitemap в файл robots.txt технически не требуется, но считается хорошей практикой.
- После обновления файла robots.txt рекомендуется проверить, не заблокированы ли важные страницы. Это можно сделать с помощью txt Tester в Google Search Console.
- Используйте инструмент проверки URL-адреса в Google Search Console, чтобы увидеть статус индексации страницы.
- Также можно проверить, проиндексировал ли Google ненужные страницы. Это можно сделать с помощью отчета в Google Search Console. Еще одной альтернативой может быть использование оператора «site». Это команда Google, которая отображает все страницы сайта, доступные в результатах поиска.
Выводы
Nofollow отвечает за переход поисковых систем по этим ссылкам, как на всей странице, так и для определенной ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
По атрибуту nofollow ссылка может индексироваться и передавать свой вес, если она стоит на качественный ресурс.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет .