Как посмотреть, как раньше выглядела страница вконтакте
Содержание:
- Для чего нужны сохраненные страницы?
- Смотрим, как выглядела страница раньше
- Сеть тематических сайтов
- Что такое кеш сайта и зачем он нужен
- Как восстановить сайт из архива
- archive.md
- Что такое веб-архив и зачем он нужен?
- Как удалить страницу на Facebook способом деактивации
- Бесплатные способы восстановления
- Как использовать архив
- Три онлайн-сервиса для сохранения в PDF
- Как посмотреть кеш в Google
- Выходим за рамки Google
- Как использовать веб-архив?
- Поисковые системы
- Где взять уникальный контент для сателлитов?
- Удаление страницы через справочный центр
- Использование сервиса WebArchive
- web.archive.org
Для чего нужны сохраненные страницы?
Кэш-страницы сайта в поисковых системах позволяют увидеть, какую версию документа уже успели проиндексировать роботы поисковых систем и участвует ли страница в ранжировании. Грубо говоря, если страница начала сохраняться — это главный фактор пройденной индексации.
Бесплатный бэкап
В работе с сайтами, может возникнуть масса непредвиденных ситуаций. Особенно на стадии запуска проекта, на сайте частенько ведутся технические работы, предполагающие корректировку дизайна и текстовых блоков. В такие моменты не исключены ошибки, которые могут «положить» сайт или нарушить его работу, также могут пропасть тексты, изображения и так далее.
Большинству разработчиков знакомы такие ситуации и если не был проведен бэкап, а дешевый хостинг не позволяет сделать «откат», то все печально. Вот тут-то и приходит на помощь кэш сайтов — копия позволяет сохраниться и проверить, какие ошибки нужно исправить.
SEO-продвижение
Еще один случай, когда кеш придет на помощь, связан с текстами. Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Технические проблемы, просрочка оплаты и так далее
Часто интернет-ресурсы бывают недоступны из-за технических проблем на сервере, истечения срока оплаты хостинга и т.п. В этом случае попасть на сайт можно также через копию, которая хранится в кэше.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Из раскрывшегося списка выберите пункт «Сохраненная копия».
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
Переключитесь к нужной временной зоне, кликнув по соответствующему году.
С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
Теперь вам будет представлена страница пользователя, но лишь на английском языке.
Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Сеть тематических сайтов
Люди работающие в конкретной сфере, например «бухгалтерские услуги», ищут в веб-архиве сайты по данной тематике. После их восстановления могут использовать как для социальных сетей (разных групп), в качестве сайтов визиток, так и для того что бы «забить» поисковую выдачу. Таким образом получается создать большую сетку сайтов для продвижения своего бизнеса за маленькие деньги, т.к. стоимость восстановленного сайта очень низкая в сравнении даже с разработкой бюджетного проекта.
Еще данная сетка может служить в качестве источника ссылочной массы на основной продвигаемый ресурс. Ссылки постепенно «отмирают», но по-прежнему еще имеют вес в фактораъ ранжирования.
Что такое кеш сайта и зачем он нужен
Поисковая система Google оснащена так называемыми ботами, которые регулярно посещают страницы сайтов и сохраняют их в памяти поисковика. Это и есть кеш, в котором сохраненная копия сайта остается даже в том случае, если сам ресурс был удален. Следует отметить, что боты «гуляют» по Интернету достаточно активно, поэтому информация в кеше, как правило, является актуальной. Однако есть два важных нюанса:
- Чем чаще на сайте появляются новые публикации, тем чаще его посещает бот, а значит, данные будут максимально свежими.
- Нередко случается так, что после удаления статьи с сайта по этой ссылке пользователь видит сообщение об ошибке. Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.
Разобравшись с особенностями работы кеша Google, стоит понять, для чего поисковая система хранит в памяти старые версии сайтов. Эксперты приводят несколько серьезных аргументов:
- Страница с материалами была удалена с сайта, а вам срочно нужны именно эти данные.
- Часть информации в нужной публикации была изменена на другие материалы.
- Владелец сайта удалил его или закрыл доступ для пользователей.
- Сайт слишком перегружен, в результате чего страницы загружаются долго.
- На сайт обрушилась ддос-атака, поэтому данные оказались временно заблокированы.
- Программисты проводят технические работы, в результате чего открыть нужную страницу невозможно.
Очевидно, что главная причина поиска сохраненных страниц заключается в утерянной информации и попытке восстановить ее с помощью функционала Google. И если с причинами и особенностями кеширования все понятно, можно переходить к главному вопросу: как посмотреть старую версию сайта и сохранить нужные сведения.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».

Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.

Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.

Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.

Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.

Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например,
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например,
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Что такое веб-архив и зачем он нужен?
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Как удалить страницу на Facebook способом деактивации
Деактивация – это первое, что рекомендует сделать пользователям администрация общественной сети. Эти способом дозволено максимально легко удалить страницу на Фейсбук навечно. Довольно перейти к меню вашего аккаунта, кликнув по крошечной черной стрелочке в верхнем правом углу страницы. Выберите пункт «Безопасность», где надобно воспользоваться опцией «Деактивировать аккаунт» и удостоверить правильность своего решения.
Как только вы закончите операцию, ваш профиль будет всецело удален из общественной сети, и его не будут видеть другие пользователи ни на своих страницах, ни в поиске. Тем не менее, «деактивация» именуется так недаром. В первую очередь другие пользователи будут по-бывшему видеть диалоги, которые они вели с вами. Также у вас все же будет вероятность восстановить профиль в течение 90 дней со дня проведения процедуры деактивации. Помимо того, администрация Facebook оставляет за собой право беречь некоторую информацию удаленных пользователей для применения в личных и законных целях.
Бесплатные способы восстановления
Ручной
Собственно основной ресурс, который используют все сервисы для восстановления сайта это https://archive.org/web/
Ниже отображается календарь за выбранный год, там вы можете увидеть конкретный месяц и день, когда был произведен снимок.

Кликайте по снимку, откроется окно со страницей сайта за тот день. Открываете консоль разработчика и копируете html и все ресурсы необходимые странице — картинки, css, js и др. Неблагодарное дело.
Аналоги archive.org
https://archive.org/web/ не единственый проект, который делает снимки сайтов и хранит их. Существуют и другие напримерArchive.ishttp://timetravel.mementoweb.org/ уникальный проект, своего рода гугл по сайтам-аналогам archive.org
Веб кэш
Если нужно восстановить данные сайта, которые были потеряны недавно, может подойти кэш поисковой системы Гугл. Можно попробовать тут https://thisis-blog.ru/posmotret-sajt-v-keshe/
Библиотеки
Можно развернуть и свою поделку под свои нужды, если есть возможность. На гитхабе ищется по ключу wayback-machine
Что там можно найти, примеры:
https://pypi.org/project/wayback-scraper/https://github.com/sangaline/wayback-machine-scraperhttps://github.com/hartator/wayback-machine-downloader
Делитесь своим опытом использования данных сервисов. Если нашли ошибку, либо есть что добавить, тоже пишите.

Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Три онлайн-сервиса для сохранения в PDF
4.1. PDFcrowd.Com
Расширение Save as PDF, рассмотренное выше, разработано создателями веб-сервиса PDFcrowd.Com. К услугам этого сервиса можно прибегать при работе с браузерами, которые предусматривают установку расширений.
Принцип работы с сервисом прост: скопированную ссылку на интернет-страницу вставляем в специальное поле, кликаем «Convert to PDF» и указываем путь сохранения файла.
Рис. 16. Сервис PDFcrowd.Com для сохранения в pdf-файле
Подобных рассмотренному выше веб-сервисов в сети несколько, вот ещё парочка аналогов.
4.2. Сервис PDFmyurl.Com
На сайте сервиса PDFmyurl.Com вставляем адрес веб-страницы в поле по центру и кликаем «Save as PDF».
Рис. 17. Онлайн-сервис PDFmyurl.Com сохраняет страничку по ее адресу в PDF-файл
Имена файлов на выходе автоматически генерируются латиницей.
4.3. Сервис Htm2PDF.Co.Uk
Примерно так же поступаем, работая с веб-сервисом Htm2PDF.Co.Uk: вставляем в поле по центру адрес нужной страницы, жмём «Convert!», затем «Download your PDF».
Рис. 18. Онлайн-сервис Htm2PDF.Co.Uk по адресу страницы сохраняет ее в PDF-формате
Этот сервис также сам генерирует имена файлов, и также латиницей. У него есть также расширение для браузера Google Chrome, вот только работает оно через раз. Сам онлайн-сервис более стабилен в этом плане.
5. Горячие клавиши CTRL+P для всех PDF во всех браузерах
Чтобы сохранить какую-нибудь интернет-страницу в PDF, можно открыть ее в любом браузере и нажать на горячие клавиши CTRL+P. Напомню принцип работы горячих клавиш: сначала нажимаем клавишу CTRL, затем не отпуская ее, одновременно жмем на клавишу P (на английском регистре). После этого на экране должно появиться окно “Печать”, похожее на то, которое приведено на рис. 2.
Если у Вас подключен принтер к компьютеру, то тогда в окне “Печать” придется кликнуть по кнопке “Изменить” (рис. 3), которая находится рядом с названием вашего принтера. Откроется меню (рис. 4), в котором надо поставить галочку напротив “Сохранить как PDF”.
Этот универсальный способ с горячими клавишами хорош тем, что не требует установки для браузера дополнительного программного обеспечения.
Если Вам не нравится вариант с горячими клавиши, введите в поисковик запрос без кавычек наподобие такого:
- “расширение сохранить в PDF Опера” или
- “расширение сохранить в PDF Яндекс Браузер”.
Поисковик предложит Вам расширения, из них лучше выбирать варианты на официальных сайтах браузеров. Установка расширения в браузер и дальнейшая работа с ним описаны , все расширения устроены по похожему принципу.
Также по теме:
1. Как открыть документ pdf?
2. Где найти скачанные файлы из интернета на своем компьютере
3. Как оставить файл пдф в памяти компьютера
4. Как преобразовать DOC в PDF?
5. Как изменить формат файла на Виндовс
Распечатать статью
Получайте актуальные статьи по компьютерной грамотности прямо на ваш почтовый ящик. Уже более 3.000 подписчиков
.
Важно: необходимо подтвердить свою подписку! В своей почте откройте письмо для активации и кликните по указанной там ссылке. Если письма нет, проверьте папку Спам
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.
Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью
Выходим за рамки Google
Понятно, что сохранением страниц и сайтов в кеше занимается не только поисковая система Google. У пользователей есть еще несколько вариантов, как можно найти удаленную статью или другие данные с сайта:
Кеш Яндекса. Система работает по такому же принципу, однако сохраненные версии могут отличаться от тех, которые хранит Google. Чтобы открыть кеш Яндекса, необходимо ввести в поиске адрес сайта и перейти к сохраненной копии с помощью зеленой стрелочки (точно так же, как и при работе с Google).
Специализированный поисковик CachedView.com, который не ограничивается Google, а предлагает пользователям доступ к Всемирному архиву Интернета
Работает по принципу Nevkontakte.com.
Еще один интересный сервис, на который стоит обратить внимание, находится по адресу archive.is. Его главная функция заключается в том, чтобы пользователь мог самостоятельно сохранять нужные страницы сайта
При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.
Таким образом, даже удаленные из Интернета материалы можно найти и восстановить. Какой способ для этого выбрать? Рекомендуем не останавливаться на одном методе, а попробовать несколько, чтобы наверняка найти нужную страницу или сайт.
Как использовать веб-архив?
 Форма для поиска информации на Peeep.us
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: https://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Где взять уникальный контент для сателлитов?
Оригинальный контент, пожалуй, один из важнейших параметров для хорошего сателлита. Несколько способом его получить:
Копирайтинг:
Самый простой и самый дорогостоящий метод. Необходимо создать техническое задание и отдать его SEO-копирайтеру, который напишет для вас уникальный, оптимизированный текст. Остается только разместить его.
Рерайт :
Более практичный способ получить уникальный материал для сайта. Рерайт – это переписывание уже созданного кем-то текста. В интернете размещено огромное количество контента. Качественный рерайт также, как и копирайтинг, даст вам уникальный, читабельный материал. Такой контент будет хорошо восприниматься и посетителями, и роботами поисковых систем.
Генерация текстов по шаблонам:
Можно назвать этот способ автоматическим рерайтом текста. Позволяет получить из одного материала множество новых. В этом вам помогут сервисы онлайн-генерации текстов. Например, Seogenerator. Принцип работы строится на использовании конструкций, которые заменяют фрагменты текущего текста на заданные варианты. Вот простой пример.
Задаем шаблон:
Получаем тексты:
Важно следить за качеством, осмысленностью и уникальностью полученных материалов, объемные тексты проверять на возможный переспам. Вы формируете YML-выгрузку товаров
Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита
Вы формируете YML-выгрузку товаров. Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита.
Восстановление контента из веб-архива:
Ищем «дропы» – домены, у которых закончился срок регистрации – схожей тематики. Найти такие домены можно, например, с помощью Reg.ru. Проверяем историю, обратные ссылки, анкоры, не менялась ли тематика и т.д. Восстанавливаем нужный контент из веб-архива и получаем уникальный сайт. Для скачивания файлов из архива есть готовые сервисы, например, Archivarix. Все сайты имеют свои особенности, поэтому при восстановлении могут быть ошибки. Наш совет – заниматься восстановлением старых сайтов вместе с разработчиком.
Удаление страницы через справочный центр
Предыдущие способы не помогли избавиться от страницы? Не переживайте, остался ещё один неплохой вариант. Его обычно используют для удаления аккаунтов родственников или друзей, которые самостоятельно войти в профиль уже не могут. Но что мешает нам использовать такой вариант лично для себя? Правильно, ничего! Тогда приступаем к инструкции:
- Открываем страницу справочного центра Facebook.
- Находим вкладку «Управление аккаунтом» и нажимаем по ней.
- В выпадающем меню выбираем «Деактивация или удаление аккаунта».
- Открывается страница с самыми популярными запросами в техническую поддержку. Кликаем по последнему вопросу.
- В тексте находим гиперссылку «Подайте заявку здесь» и переходим по ней.
- Заполняем необходимую информацию, такую как имя и фамилию, адрес электронной почты, ссылку на наш аккаунт и полное название профиля.
- В конце выбираем «Отправить».
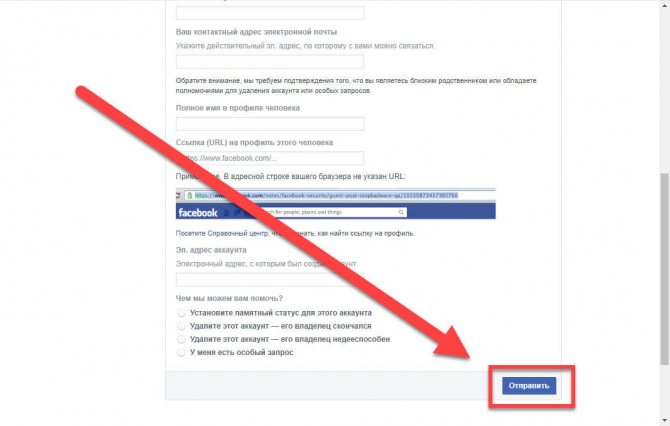
Теперь только остаётся дождаться ответа от технической поддержки. А они его могут формировать на протяжении нескольких дней или даже недель. Так что запаситесь терпением!
Использование сервиса WebArchive
Всем, кто задается вопросом, где посмотреть старые версии сайтов, можно порекомендовать воспользоваться таким интересным сервисом как WebArchive.
Его функционал гораздо шире, чем у кэша поисковиков, можно просмотреть, как видоизменялся сайт за месяцы и годы своего существования, а также воспользоваться поиском по конкретному числу, когда была сохранена копия содержимого страницы.
Для того, чтобы воспользоваться сервисом, в поиске на сайте WebArchive введите адрес искомой страницы. Также поддерживается поиск по ключевым словам, относящимся к тематике ресурса — можно воспользоваться им. Как только вы это сделаете, появится статистика по годам. Черным цветом отмечено, в какое время создавалась резервная копия сайта, сохраненная в архиве.
Как только вы выберете нужный год и перейдете на него, откроется календарь, в котором можно выбрать число, за которое была сохранена резервная копия страницы сайта.
Зеленым и синим цветом отмечены даты, когда поисковые роботы заархивировали страницу и добавили ее к просмотру.
Как правило, возможность просмотра изображений отсутствует, однако текст сохраняется в полном объеме. А если вы ищете какую-либо конкретную статью на определенном ресурсе, есть вероятность, что ссылка на нее могла сохраниться.
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».
Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.