Каким был сайт раньше
Содержание:
- Примечания
- Борьба с добром и российской судебной практикой
- Как использовать архив
- Восстановление сайта из веб архива
- Смотрим, как выглядела страница раньше
- Как найти уникальный контент для своего сайта
- Мнения в Сторис
- Как проверять полученные статьи на уникальность
- Специальные архивные сервисы
- Индексация веб-страниц в интернете
- Просмотр копии страницы в поисковиках
- Как узнать историю сайта? Пошаговая инструкция
- Что такое веб-архив?
- Archive.is
- Компании, архивирующие интернет
Примечания
- (англ.). Alexa Internet. — Глобальный рейтинг сайта archive.org. Дата обращения: 20 июня 2020.
- .
- .
- (англ.). archive.org. Дата обращения: 28 марта 2019.
- . Internet Archive (7 мая 2007). Дата обращения: 31 августа 2016.
- (недоступная ссылка). Wayback Machine (6 июня 2000). Дата обращения: 1 сентября 2016.
- Jeff. (Blog). Wayback Machine Forum. Internet Archive (23 сентября 2002). Дата обращения: 4 января 2007. Author and Date indicate initiation of forum thread
- Miller, Ernest (Blog). LawMeme. Yale Law School (24 сентября). Дата обращения: 4 января 2007. The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. (англ.). preprint cs/0404005 16. arXiv (2004). Дата обращения: 26 ноября 2017.
- .
- .
- (недоступная ссылка). Дата обращения: 17 сентября 2017.
- . Роскомнадзор (24 октября 2014).
- ↑
Борьба с добром и российской судебной практикой
Организация Internet Archive зарегистрирована в Сан-Франциско (Калифорния, США), а одноименный ресурс, согласно законам штата Калифорния, официально считается библиотекой. Организация располагает обширным списком партнеров, в число которых входят многие крупные организации со всего мира. К ним относятся, в частности, Национальный научный фонд США и Библиотека конгресса США
CIO и СTO: как меняется влияние ИТ-руководителей в компаниях?
Новое в СХД
В России «Архив интернета» нередко используется российскими судами как доверенную третью сторону и источники информации, в том числе улик и доказательств расследования.
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в , после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
Затем нажимаем «Все ОК, собрать ZIP-архив»:
После этого нажимаем «Скачать архив»:
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
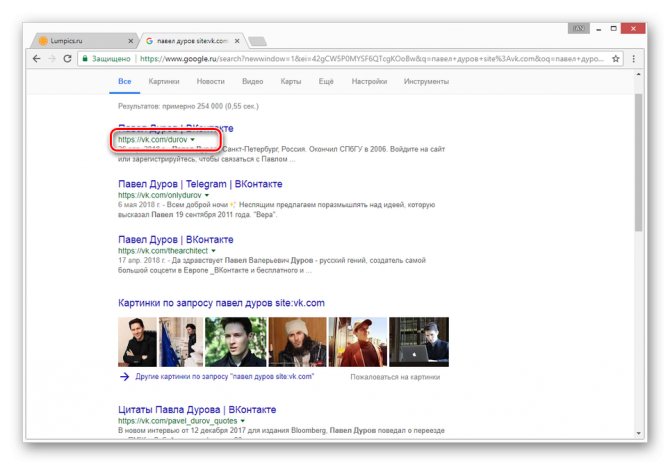
Из раскрывшегося списка выберите пункт «Сохраненная копия».
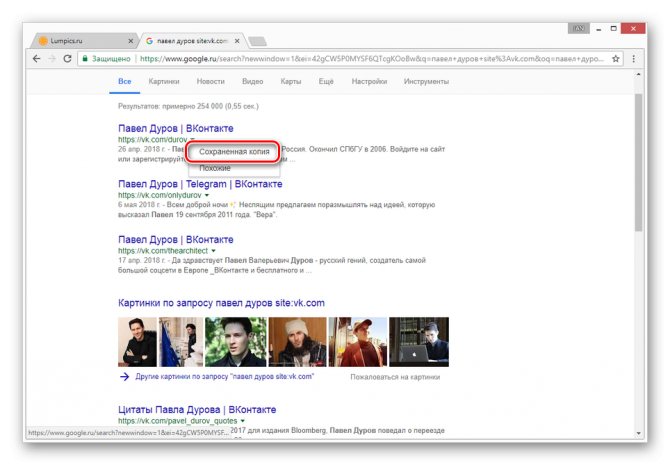
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
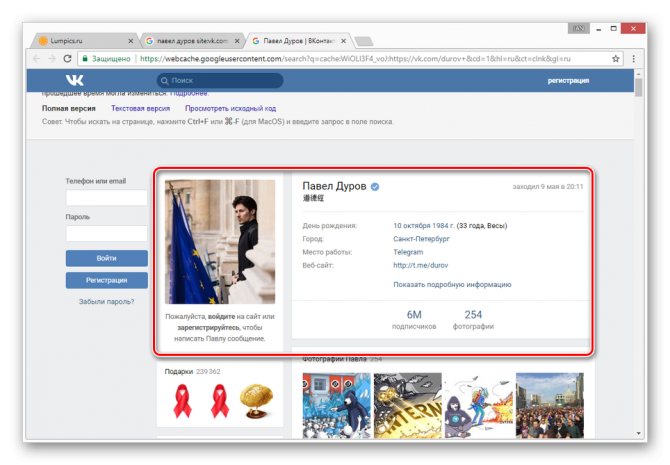
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
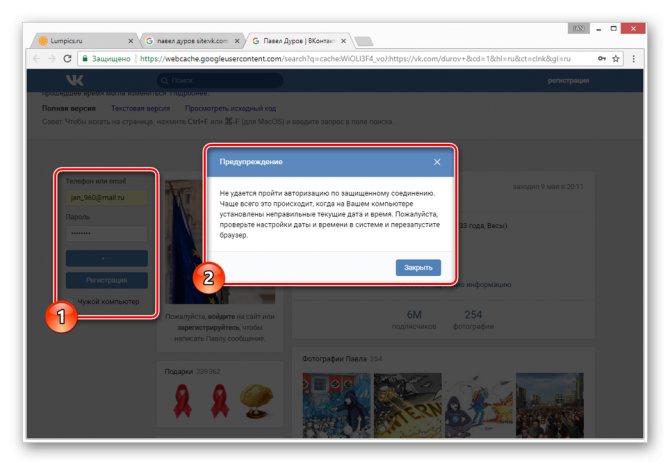
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
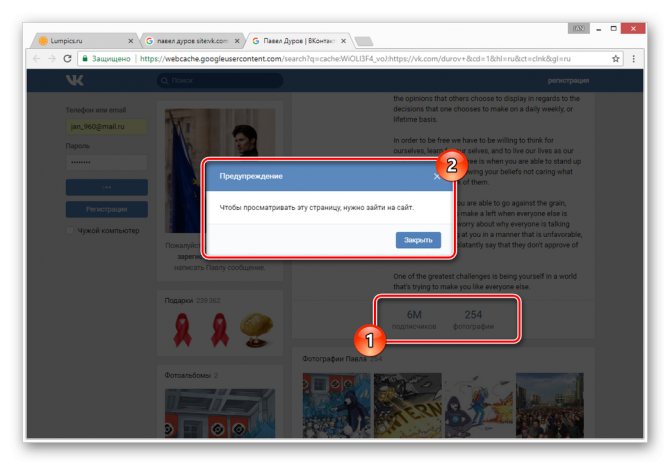
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
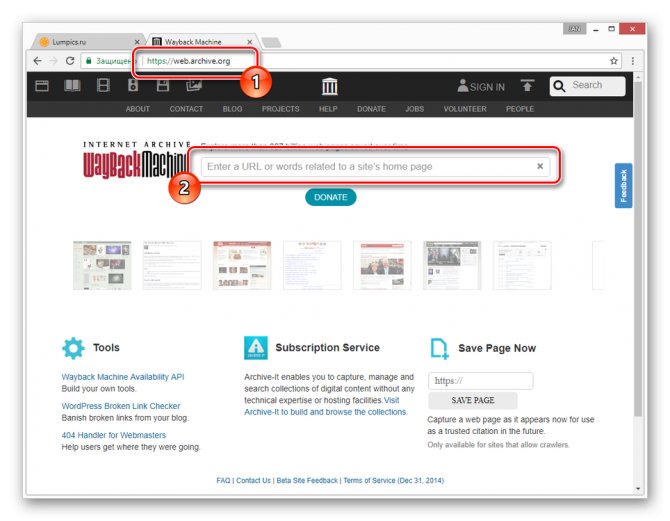
В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
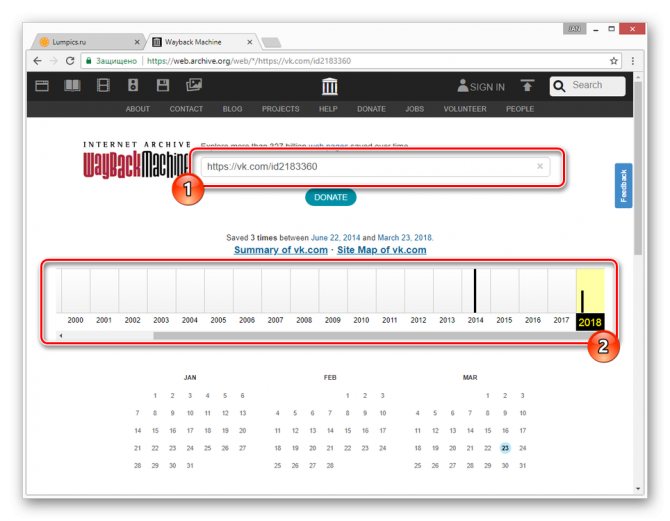
Переключитесь к нужной временной зоне, кликнув по соответствующему году.
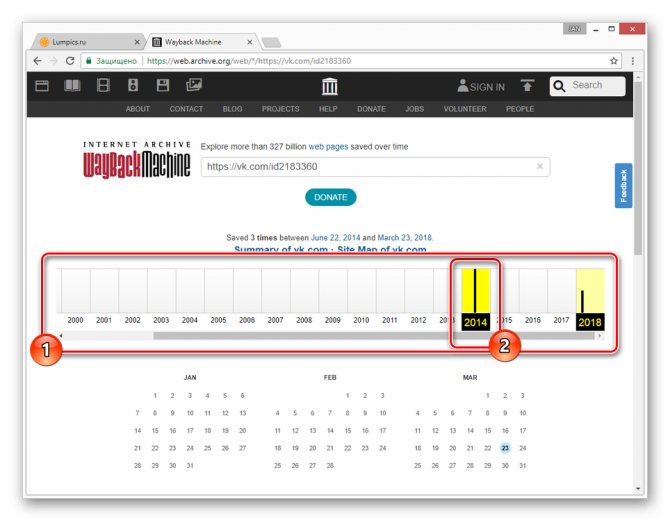
С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
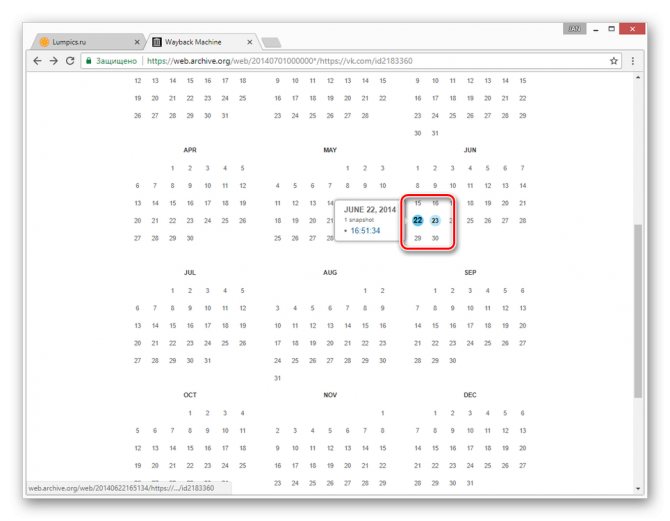
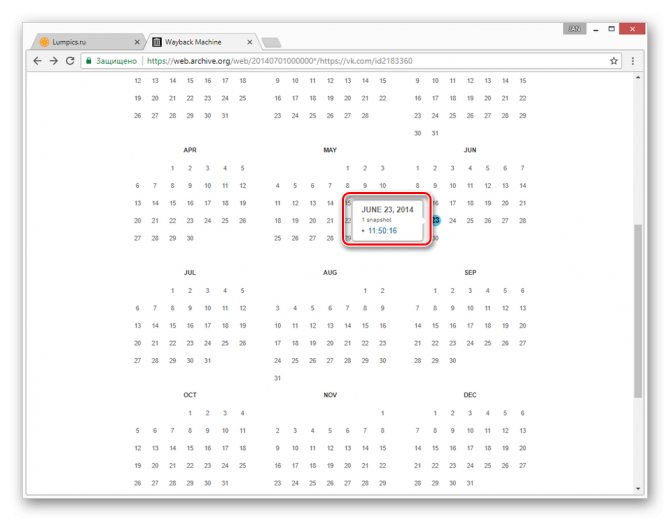
Теперь вам будет представлена страница пользователя, но лишь на английском языке.
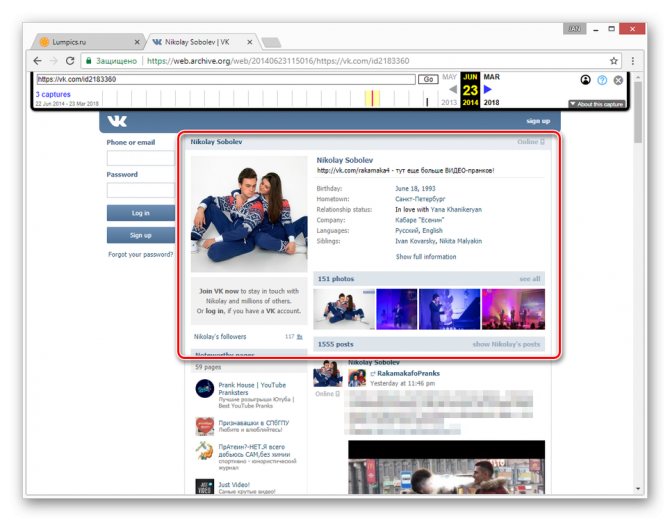
Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
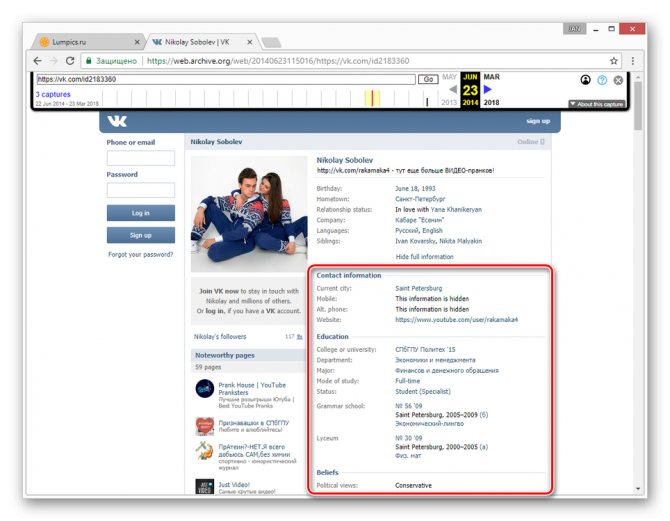
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Мнения в Сторис
Создатели социальной сети стараются вносить изменения и новые опции ВК, чтобы пользователям было интересно и весело. Теперь каждый может воспользоваться опцией мнения в сторис. Это функция позволяет выразить собственное мнение относительно того или иного вопроса, процесса, новости. Также можно другим юзерам, своим подписчикам. Чтобы воспользоваться такой опцией нужно:
- Открыть новости, где доступны сторис.
- Далее нажимаем на создание новой публикации.
Создаем новую публикацию
- Делаем селфи или же добавляем другое изображение.
- Жмем на кнопку в виде наклейки.
- Кликаем на стикер мнения.
- Из представленного перечня нужно выбрать тот, который вас заинтересовал, и вводим вопрос.
Такая история также будет храниться в архиве социальной сети, и при желании вы сможете ее просмотреть. После того как юзеры выберут ее, появится форма для ввода ответа на вопрос. Отвечающий при желании может указать имя или же остаться анонимом.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.
Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».
Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Как узнать историю сайта? Пошаговая инструкция
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.

Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив – www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:

История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:

Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:

Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.
Что такое веб-архив?
Для того, чтобы узнать, что такое веб-архив, стоит вспомнить события, произошедшие более 20 лет назад. В 1996 году по инициативе американского программиста, Брюстера Кайла, был создан сайт archiveorg. Благодаря этому ресурсу, любой пользователь может найти сохранённые копии сайтов разных лет.
Со временем библиотека Web archive расширилась и к 2016 году включала в себя 502 миллиарда копий веб-страниц. Это является одним из лучших примеров коллаборации с целью принести обществу пользу. Для того, чтобы посмотреть в реальном времени сайты, которые функционировали некоторое время назад, достаточно зайти в архив и найти его в системе.
Основной целью, которую преследовал Кайл, было сохранение исторические ценности интернет-пространства. Web archive может использовать каждый пользователь, при этом бесплатно. Для работы веб-архива по сохранению интернет-ресурсов может быть только одно препятствие. Если в настройках сайта нет запрета на сохранение информации с ресурса, такой сайт сможет войти в базу веб-архива.
Как происходит пополнение веб-архива? Для этого было создано программное обеспечение, посещающее и сохраняющее сайта с определённой частотой. Так же есть возможность делать сохранения ресурсов вручную. Например, при посещении сайта можно сохранить страницу о курсах СЕО для начинающих или любую другую часть ресурса. Это поможет сохранить информацию с течением времени.
Archive.is
Archive.is является еще одной хорошей альтернативой Wayback Machine и, возможно, лучше, чем скриншоты для большинства людей. Это не один из самых привлекательных веб-сайтов или простой в навигации, но его база данных и методы архивирования восполняют его.
Archive.is позволит вам выполнять поиск по истории веб-сайта и снимать скриншот любого домена по запросу, который будет сохранен для всеобщего просмотра. Это делает его идеальным решением для получения всех подробностей о веб-сайте, включая данные и графические данные.
Как это устроено
Archive.is архивирует веб-сайт по запросу или в соответствии с частотой действий на конкретном веб-сайте. Это займет и скриншот и код сайта во время архивирования. Однако, в отличие от Wayback Machine, он не отправляет сканеры для архивирования веб-страниц. Это означает, что веб-сайт не может остановить Archive.is от архивирования с использованием файла robot.txt.
Если существует веб-сайт, который может блокировать сканирование Wayback Machine своего сайта, вам следует выбрать Archive.is, чтобы получить доступ к нему.
Практическое использование
Веб-сайт Archive.is не так привлекателен, как Wayback Machine или Screenshots. Хотя, это довольно просто для навигации с наименьшим количеством вариантов для беспокойства. На главной странице вы найдете две панели поиска, одну красную сверху и другую синюю снизу. Красная панель поиска — это место, где вы можете запросить архивирование веб-страницы, а синим цветом вы можете просмотреть историю любого веб-сайта.
Архив спроса
В красной строке поиска вы можете потребовать архивирование любого веб-сайта, а Archive.is скопирует код и сделает его снимок экрана. Просто введите URL-адрес страницы веб-сайта в строку поиска и нажмите «сохранить страницу».
Archive.is начнет обработку и после небольшой задержки (в зависимости от размера страницы) вы увидите заархивированную страницу и снимок экрана с ней.
Примечание . Вы не ограничены простым добавлением URL-адреса целевой страницы определенного веб-сайта, вы можете добавить URL-адрес любой страницы веб-сайта. Просто зайдите на страницу, которую вы хотите заархивировать, и скопируйте / вставьте ее URL в архиве. При поиске он будет заархивирован.
Проверить архивную историю веб-сайта
В синей строке поиска ниже вы можете ввести URL-адрес веб-сайта, и вы увидите всю его историю. Будет два варианта: самый старый и самый новый. Самая старая содержит самую старую заархивированную веб-страницу, а самая новая содержит самые последние заархивированные страницы и возвращаясь оттуда.
Вы увидите все заархивированные страницы, начиная с самых последних и возвращаясь назад, вместе с данными, указанными под каждой веб-страницей. Вы можете просто нажать на любую веб-страницу, чтобы увидеть ее детали.
Откроется архивированная веб-страница, и вы можете легко перемещаться по ней. Вы можете нажать на «Снимок экрана», чтобы увидеть скриншот этой конкретной веб-страницы.
В наших результатах скриншоты архивировались 9gag 21 раз, а с другой стороны, Archive.is архивировал его 1063 раза. С этим небольшим примером вы можете взвесить частоту архивирования сайта.
Основные характеристики: архивирует как код, так и снимок экрана веб-страницы, огромную базу данных, обменивается результатами и загружает их, а также запрашивает архивирование любого веб-сайта в любое время.
Минусы: непривлекательный интерфейс, сложно ориентироваться на нужной веб-странице и не предоставляет много информации о конкретной веб-странице.
Компании, архивирующие интернет
Архив Интернета
Основная статья: Архив Интернета
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт. На начало 2009 года он содержал 85 миллиардов веб-страниц., в мае 2014 года — 400 миллиардов. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию, позднее был исключён из реестра.
WebCite
Основная статья: WebCite
«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us
Сервис peeep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца.
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров.
Archive.today
Основная статья: archive.today
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.