Парсинг — что это? виды и примеры парсинга
Содержание:
- Маркерные запросы
- Находим упущенные ключевые слова
- Способ 3. Подбор ключевых слов конкурентов с дальнейшим углублением
- Полезные инструменты проверки количества запросов и ключевых слов
- Как работать в программе
- Расширения для браузера Яндекс Wordstat
- Мутаген
- Виды парсеров по сферам применения
- Наборы инструментов
- Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
- Как пользоваться парсером Wordstat от Click.ru
- Что делает парсер?
- Как работают парсеры поисковых запросов
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:
Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:
Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам
Как найти маркерные запросы?
Вариант №1: можно получить поисковые запросы из Яндекс Метрики. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?
Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т.е. логических гипотез
Важно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Находим упущенные ключевые слова
Собрать все ключи и объявления конкурентов полезно для общего анализа и понимания ситуации
Но если у вас уже запущены рекламные кампании, важно понимать другое: какие слова используют ваши конкуренты, а вы – нет
Как это сделать
1. Подготовьте список ключевых слов, по которым у вас запущена реклама.
2. Перейдите в инструмент «Слова и объявления конкурентов». Укажите домены конкурентов (которые хотите спарсить). В блоке профессиональных настроек вставьте ключи в поле «Минус-слова».

Все слова, добавленные в поле «Минус-слова», система исключит при парсинге. В результатах будут только те ключи, которые вы еще не использовали.
Важно! В блоке профессиональных настроек парсера также есть опция «Точное вхождение без учета морфологии». Если она включена, система не будет собирать указанные ключи в базовом виде, а также с изменением падежа
3. Запустите парсинг и скачайте результаты. На выходе вы получите готовый набор ключей, с помощью которого можете расширить семантику.
Способ 3. Подбор ключевых слов конкурентов с дальнейшим углублением
Этот способ заключается в следующем: собираем ключевые слова, под которые оптимизированы сайты ваших конкурентов, а затем углубляем семантику. Таким образом мы можем собрать ключевые слова, которые упустили.
Собрать семантику конкурентов и углубить можно с помощью платформы PromoPult. Зарегистрируйте аккаунт (это бесплатно), создайте проект. На этапе выбора инструмента кликните по инструменту «Поисковое продвижение SEO».
На следующем этапе укажите URL вашего сайта, регион, а также укажите название проекта.
Нажмите «Создать проект». Система переведет вас на следующий шаг и автоматически подберет запросы, по которым страницы вашего сайта ранжируются в топ-50 Яндекс и/или Google. С этой семантикой также можно поработать и подобрать фразы «с хвостами». Но мы будем собирать семантику конкурентов, поэтому переключаемся на вкладку «Слова ваших конкурентов».
Добавляем адреса сайтов, с которых хотим собрать семантику, затем жмем «Показать слова всех конкурентов».
Система проанализирует сайты, URL которых вы указали, и покажет список найденных ключевых слов.
Просмотрите список и выберите слова, которые будете использовать для углубления семантики. Проставьте на этих словах галочки и добавьте к опорному списку (на его основе мы будем расширять семантику).
В профессиональном режиме можно по-разному работать с опорными словами – например, спарсить левую колонку Яндекс.Вордстата или подобрать фразы-ассоциации (с правой колонки Вордстата).
Мы добавили в опорный список 5 фраз и будем использовать для углубления семантики инструмент «СЧ НЧ».
Результат: система подобрала 2186 ключевых фраз (обратите внимание, в опорном списке было всего пять фраз). Подобранные ключи можно добавить в опорный список и снова использовать инструмент «СЧ НЧ», углубляя семантику уже по собранным запросам
После того как вы соберете достаточное количество ключей, выгрузите их с помощью функции экспорта.
Обратите внимание! Сбор семантики конкурентов и ее углубление в PromoPult бесплатны. Весь функционал доступен без ограничений – можно запускать любое количество проверок и собирать любое количество ключевых слов
Полезные инструменты проверки количества запросов и ключевых слов
Key Collector
Самый популярный сервис сбора ключевых слов и формирования семантического ядра. Распространяется на платной основе. Им пользуются профессионалы в области поисковой оптимизации.
Для первичной настройки программы требуется проделать следующее:
- Добавьте в Key Collector до 10 аккаунтов Яндекс.
- Добавьте в программу сервис анти-капчи. Настройки — Анти-капчи.
- Проведите настройку Вордстат. Настройки — Парсинг — Yandex.Wordstat.
Key Collector позволяет парсить десятки страниц и эффективно выгружать очищенные запросы в неограниченном количестве. Для работы сервиса парсинг производится в Яндекс.Директ.
Также доступен сбор статистики для Google Ads и социальных сетей. Для этого проведите настройки согласно инструкции на сайте разработчика.
Когда парсинг завершён, и вы работаете со списком слов, воспользуйтесь функцией фильтрации. Она помогает очистить выборку от неподходящих фраз и даже оставить только некоторые словоформы, удалив часть того или иного слова.
Также фильтрация помогает удалить повторяющиеся слова — для этого предусмотрена отдельная функция. Затем вы можете удалить специальные и нежелательные символы, такие как цифры и латинские буквы. Более того, если вам знакомы регулярные выражения, это окажется плюсом, так как они поддерживаются программой.
Один из важных этапов сбора семантического ядра — удаление стоп-слов. Эта функция реализована в Key Collector. Например, вы можете удалить лишние прилагательные, описывающие второстепенные свойства продукта: самый, лучший, красивый. Сюда относятся и свойства цены: недорогой, бесплатный, купить.
Slovoeb
Данное приложение позволяет проводить парсинг ключевых слов и сбор частотности определённых запросов. Это бесплатное приложение, которое анализирует выдачу через Яндекс.Директ. Чтобы начать работу, так же, как и в случае с Key Collector, настройте Яндекс аккаунты и анти-капчу.
Функционал программы повторяет концепцию Key Collector, так как является предтечей последнего, и содержит урезанный функционал. Если вам интересно профессионально заниматься SEO, приобретите Key Collector. В случае грамотного использования вложения окупятся весьма быстро.
Ahrefs
Сервис Ahrefs предлагает инструмент Keywords Explorer для анализа ключевых слов. Он поддерживает поиск по 3 миллиардам ключевиков, более 100 стран, статистику кликов, анализ SERP и целый ряд полезных функций для фильтрации слов.
Добавьте через запятую интересующие вас запросы, выберите регион и запустите анализ. Или используйте сквозную аналитику Calltouch.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Keyword Tool
Это маркетинговый инструмент, который помогает в поиске ключевых слов и работает с функцией автозаполнения Google. Он генерирует сотни ключевых слов, одинаковых по значению, но отличающихся по форме. С помощью функции автозаполнения пользователи быстрее могут найти информацию в поисковике на основании предложенных системой слов. Keyword Tool оценивает подсказки, выдаваемые поисковиком, и структурирует их в удобном для пользователя виде.
Как работать в программе
Теперь мы кратко разберемся, как пользоваться этой программой. Сложностей тут никаких нет. Но все равно стоит дать небольшую инструкцию, которая будет включать в себя последовательность действий и обзор некоторых функций.
Для начала вы должны создать проект. Идем в главное меню (кнопочка Еб в углу), нажимаем на “Создать проект”. Выскочит окно нашего файлового менеджера, где нам будет предложено заполнить поле “Имя” и сохранить наш файл проекта в каком-то месте.
Это все делается на ваше усмотрение. Но лучше сохранять проекты в той же папке, где и сам Словоеб. После того, как вы кликнете “Сохранить”, проект откроется в окне программы.
В нижней части программы мы видим настройки регионов для Яндекса и Гугла. Самая первая отвечает за Яндекс.Вордстат, вторая – за Директ, третья – Гугл. Также тут есть кнопка обновления, которая поможет вам в случае, если программа начнет тупить.
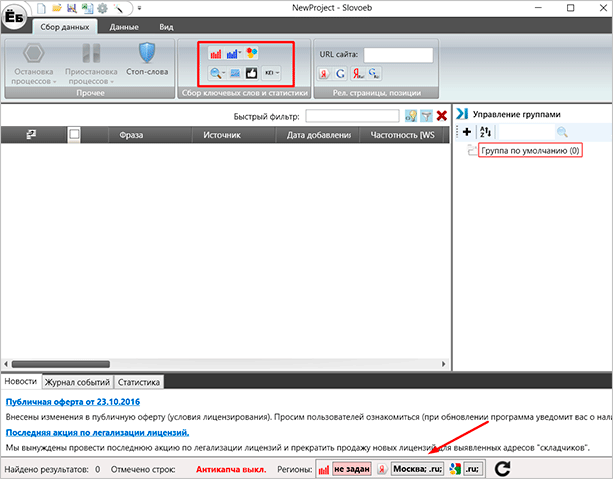
Чуть выше вы можете видеть вкладки: “Новости” – которых уже не было 2 года, “Журнал событий” – лог всех операций, производимых через утилиту, и “Статистика” – тут будет отображаться статистика по собранным ключевикам.
Еще выше у нас расположилось большое поле, где будут все запросы и их частотности. Вся информация представлена в виде удобной таблицы.
Рядом “Управление группами”. С помощью этого инструмента вы сможете разбивать запросы на группы и работать уже с ними.
В самом верху у нас находятся инструменты для работы с семантическим ядром. Самая первая из доступных нам кнопок позволяет работать с минус-словами. Туда можно вписать слова и фразы, которые программа должна игнорировать при сборе ядра.
Рядом идут инструменты для работы с Вордстатом и поисковыми подсказками. Вы можете собрать ключи из левой колонки Вордстата (с наличием самого ключа в запросах), правой колонки (похожие запросы). После этого можно собрать поисковые подсказки или проверить корректность словоформ. Здесь же инструменты для вычисления KEI и сбора частотностей.
Для добавления своих поисковых фраз вы должны перейти во вкладку “Данные”, нажать на кнопку “Добавить фразы”. У вас выскочит окно, куда вы сможете ввести одну или несколько поисковых фраз.
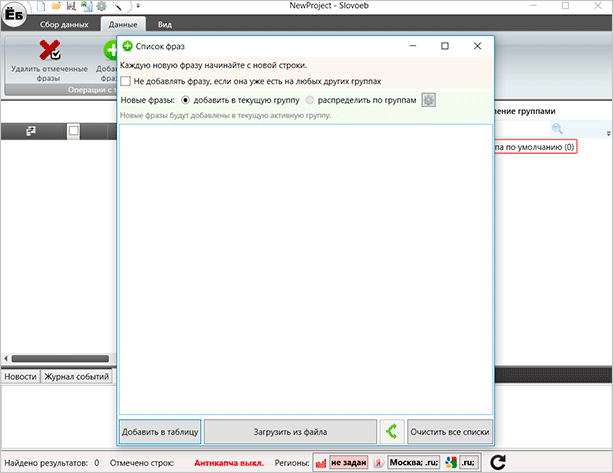
Поисковые фразы можно добавлять в текущую группу, либо же создать новую. Также вы можете воспользоваться функцией “Загрузить из файла”. Программа работает только с TXT-файлами, поэтому если вы сохраняли поисковые фразы где-то еще – самое время перенести их в блокнот. После этого вы сможете собрать частотности или провести любые другие операции с этими данными.
Как только работа по сбору семантического ядра и очистке его от лишнего мусора будет закончена, вы должны экспортировать всю информацию в файл. Для этого найдите в левом верхнем углу иконку с Excel-файлом и кликните на нее. Далее вновь откроется окно файлового менеджера, используя которое вы и сохраните файлик с таблицей.
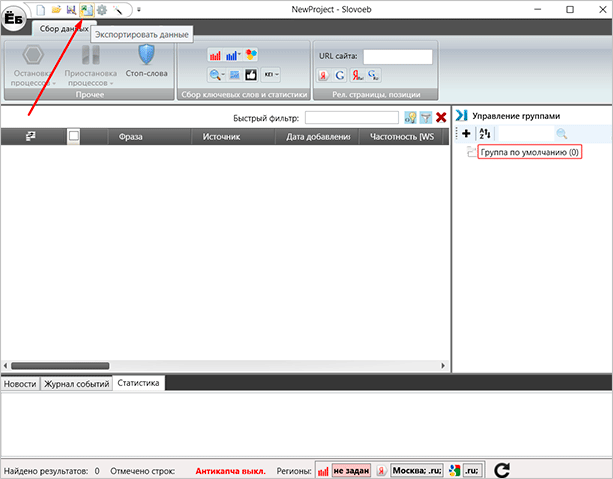
Вы можете сохранить проект и вернуться к работе над ним позже. Для этого нажмите на иконку сохранения, также выберите папку через файловый менеджер и кликните на “Сохранить”.
Расширения для браузера Яндекс Wordstat
Использовать Яндекс Wordstat по старинке, то есть копипастить подходящие запросы – вчерашний день. Использование бесплатных расширений для браузера дает гораздо больше возможностей.
Рассмотрим основные из них на примере плагина Wordstat Assistant. После установки его панель управления находится в левой области страницы Яндекс Wordstat.
Итак, плагины Вордстата позволяют:
1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.
Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь:
Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:
2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;
3) Добавлять собственные ключи:
Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.
4) Сортировать список ключей по частотности, алфавиту и порядку добавления.
5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.
Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.
WordStater включает три вкладки:
1) Общий список из результатов Wordstat;
2) Список минус-слов;
3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.
В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):
Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.
1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
- Ctrl+Shift+A – для добавления ключей с текущей страницы;
- Ctrl+Shift+(стрелка вправо) – со следующей, и т.д.
Так вы быстрее соберете много фраз, однако есть риск «схватить» за это капчу.
2) Исключение из выдачи Вордстата ранее минус-слов, заданных вручную или собранных из выдачи.
Активируйте минусацию, откройте вкладку «Сбор минус-слов»:
Или исключите слова прямо в выдаче Вордстата:
3) Генерация ключевых фраз в «Комбинаторе слов»:
Работает она по принципу перемножения:
Подробнее об этих и других возможностях расширений Яндекс Вордстат смотрите здесь.
Мутаген
Следующий прекрасный сервис — это Мутаген. Помимо базового показа количества показов ключа в месяц, тут еще можно посмотреть уровень конкуренции по заданной фразе. А весь список собранных ключей потом экспортировать.
Давайте взглянем на интерфейс:
Вводим ключ в поле и получаем следующее:
Уровень конкуренции определяет то, насколько сложно выйти в топ поисковой выдачи по этому ключу. Максимальная конкуренция — это 25, а минимальная — 1.
По своему опыту скажу, что нормальная конкуренция — это примерно до 12. Тогда вы сможете попасть в поисковую выдачу без особых трудностей. Если конкуренция выше 12, будет сложно. Нужно потратить много времени на написание действительно интересной и хорошо оптимизированной статьи.
Поэтому важно выбирать ключевые запросы с более низким уровнем конкуренции, в этом и помогает сервис Мутаген. Как и в Яндекс.Wordstat, при нажатии на один из ключей списка вы получите статистику уже конкретно по нему
Как и в Яндекс.Wordstat, при нажатии на один из ключей списка вы получите статистику уже конкретно по нему.
Если по вашей тематике вам не удается найти много ключей, чтобы собрать для статьи большую базу, не стоит брать запросы более высокого уровня конкуренции. Это не поможет. Соберите все ключи, которые вы найдете для вашей ниши, и используйте только их. Даже если их мало.
Пример: запрос «seo копирайтинг заказать» имеет уровень конкуренции 10, но вы не можете найти схожие ключи для расширения семантики. Не стоит в таком случае брать ключ «копирайтинг заказать».
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Наборы инструментов
1. Утилиты для работы с контекстной рекламой от Алексея Ярошенко:
- Генератор объявлений Google AdWords;
- Утилита для массовой генерации объявлений в Директе;
- Генератор UTM-меток для AdWords, Директа и ВКонтакте;
- Утилита для работы с типами соответствия Google AdWords;
- Утилита проверки автоподставновки ключа в заголовок;
- Утилита для быстрого сбора ключевых слов в Яндекс.Директе;
- Сервис отправки транзакций в Google Analytics;
- Сервис для А/Б-тестирования страниц;
- Утилита для кросс-минусации в Директе;
- Утилиты для быстрой фильтрации ключевых слов.
2. Excel для контекстной рекламы от Дмитрия Тумайкина. Инструкция по работе с !SEMTools.
3. Snacks — бесплатные инструменты от K50:
- Минусатор — инструмент для автоматического определения нерелевантных ключевых слов, площадок, временных отрезков в Яндекс.Директ;
- Лемматизатор — получает список слов, отдает лемматизированные версии (приводит к единственном числу именительному падежу);
- YML=>CSV преобразователь — получает YML файл для Яндекс-Маркета, а отдает CSV таблицу с товарами и характеристиками.
4. Google Analytics Demos & Tools — больше 15 инструментов:
- Компоновщик URL;
- Hit Builder;
- Query Explorer.
5. Инструменты для сбора и работы с минус-словами:
- Сервисы для автоматического формирования списка минус-слов;
- Списки минус-слов по тематикам (28 шт);
- Подробное руководство по работе с минус-словами.
6. Онлайн-инструменты для работы с текстами и семантикой:
- Генерация текстов по шаблону;
- Приведение слов в запросах к нужному числу и падежу;
- Нормализация;
- Подсчет слов в ключевы фразах;
- Группировка и чистка фраз;
- Кросс-минусация.
UPD. Бесплатные инструменты от «Пиксель Тулс». Для использования любой утилиты нужна регистрация.
- Лемматизация и удаление дублей ключевых фраз;
- Инструмент для генерации UTM-меток
- Парсинг подсказок на YouTube (нужна авторизация)
- Тестирование скорости загрузки страниц, размер документа
- Сервис для проверки ответа сервера
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.
Блок профессиональных настроек пока не трогаем (мы еще разберем его).
В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» — в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист — это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом — все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:
Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.
В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
| скачать видео бесплатно – 1 111 285 показов | “скачать видео бесплатно” – 8 493 показа |
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
| “!купить !телефон” – 37 909 показов | “!купить !телефоны” – 2 798 показов |
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
| – 4 213 показов | – 1 814 показов |
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
Здесь будут появляться отчеты со статистикой
Что делает парсер?
Ответить на вопрос, что делает парсер довольно просто. Механизм в соответствии с программой сверяет конкретный набор слов с тем, что нашлось в интернете. Дальнейшее действие касательно полученной информации будет задано в командной строке.

Стоит отметить, что программное обеспечение может иметь разные форматы представления, стилистику оформления, варианты доступности, языки и многое другое. Здесь, как и в тарифах контекстной рекламы имеет место быть большое количество возможных вариаций.
Работа всегда происходит в несколько этапов. Сначала происходит поиск сведений, загрузка и скачивание. Далее значения извлекаются из кода вэб-страницы так, что материал отделяется от программного кода страницы. В итоге формируется отчет в соответствии с заданными требованиями напрямую в базу данных или сохраняется в текстовой файл.
Парсер сайта дает много преимуществ при работе с массивами данных. Например, высокую скорость обработки материалов и их анализ даже в огромном объеме. Также автоматизируется процесс отбора сведений. Однако отсутствие своего контента негативно сказывается на SEO.
Как работают парсеры поисковых запросов
После того как вы собрали базу ключей и расширили ее с помощью Вордстат, можно воспользоваться платным сервисом, чтобы очистить значимые фразы и составить семантическое ядро. Рассмотрим, как это сделать, на примере Кей Коллектора
- Открываем «Файл» -> «Новый проект» и устанавливаем регион.
- Нажимаем «Пакетный сбор слов из левой колонки Yandex.Wordstat», копируем уже имеющийся список и нажимаем «Начать сбор».
Запросы с базовой частотностью (БЧ) ниже 5 являются мало запрашиваемыми и принесут мало трафика, поэтому их лучше удалить.
Чтобы автоматизировать этот процесс, перед началом сбора слов устанавливаем в настройках нижнюю границу БЧ, которая будет включена в конечный результат.
С помощью удобных программ и нехитрых действий вы сможете собрать базу ключей, даже если вы новичок.
Используете функцию парсинга ключевых запросов? Делитесь опытом в комментариях!