Еще не зарегистрированы?
Содержание:
- Дополнительные возможности
- Как работать с Вордстатом
- Советы и рекомендации по использованию программ для парсинга
- Зачем нужен Вордстат?
- Метод перемножения
- Как перейти к низкочастотным запросам?
- Как правильно пользоваться Словоеб
- Как создать семантическое ядро?
- Различия между Словоеб_ом и Key Collector_ом
- Как пользоваться парсером Wordstat от Click.ru
- Маски для интернет-магазина
- Инструменты для определения частотностей
- Программы для подбора и фильтрации запросов
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.
Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.
Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.
Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.
Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.
Советы и рекомендации по использованию программ для парсинга
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).
Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
Какие категории использовать — решаете сами. Откуда брать варианты? Сайты конкурентов, словари синонимов, тематические форумы и блоги — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такое:
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Как перейти к низкочастотным запросам?
Снизу (после полученного списка) вы сразу увидите переход на следующую страницу. К сожалению, перейти в самый конец выдачи сервиса с помощью одного нажатия не получится, так как отлистывать можно лишь по одной странице. Напротив высветившихся запросов Вордстат показывает их количество и собирает все словосочетания, они же низкочастотные запросы, которые искали минимум 5 раз за последний месяц
Внимание: если листать страницы слишком быстро, а также при долгом пребывании на сервисе может появиться капча. Если Яндекс заставляет вас ввести указанный на картинке буквенно-цифровой код, то он просто хочет убедиться, что вы не робот, а живой человек
В Вордстате можно листать только на одну страницу вперед. Чтобы перейти на десятую страницу, придется нажать на кнопку «Далее» девять раз.
Если для дальнейшей работы с популярными запросами вам нужно вставить полученную статистику в Excel, нажмите Ctrl+C, выделив мышкой все необходимые данные в браузере, а затем в Экселе нажмите правую кнопку и укажите «Вставить как» => «Текст без форматирования». Так ваша таблица будет выглядеть красиво и аккуратно.
Как правильно пользоваться Словоеб
Если вы не против, то я буду показывать процесс работы опять-таки с помощью скриншотов из КейКоллектора. Конечно же вы не против. И давайте тогда рассмотрим например, как собрать ключевые слова для настройки Яндекс-Директа.
Парсинг базового ключа
Первым делом нам надо распарсить наш базовый ключ. Допустим, мы настраиваем рекламу для доставки пиццы на дом. Нашим базовым ключом в этом случае будет “доставка пицца” или просто “пицца”. Но ввести просто “пицца” – значит обречь себя на долгую ручную чистку списка ключей от всяких “рецептов пиццы в домашних условиях”.
Поэтому давайте возьмем “доставка пицца”. Создайте новый проект, и перед началом работы обязательно укажите регион, в котором вы собираетесь рекламироваться.
Если это вся Россия, то ничего не меняйте.
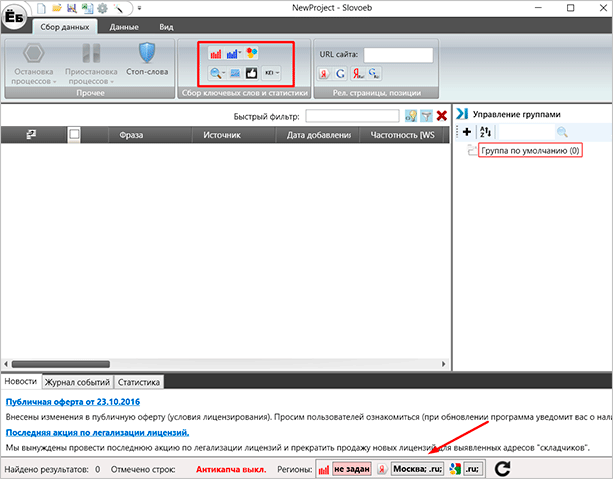
Теперь мы нажимаем на кнопочку парсинга Вордстат и вводим наш базовый ключ.
Программа начинает работать, а мы можем пока перекурить и оправиться.
Через некоторое время все процессы остановятся – значит парсинг завершен. И мы увидим список ключевых слов, которые нам подобрал Словоеб.
Но при этом он нам показывает только “базовую частотность”. То есть мы видим не точное количество запросов в месяц того или иного ключа, а общее количество запросов основного ключа + хвост.
Например, в списке, выданном Словоебом есть основной ключ “Телефон доставки пиццы”. И значение – 6560 запросов в месяц. Это значит 1000 запросов “телефон доставки пиццы” + еще 1000 запросов “телефон пицца доставка” + еще и еще.
А нам нужны точные значения, иначе мы никогда не сможем прогнозировать – какое количество трафика в месяц мы получим, и сколько мы с этого сможем заработать.
Поэтому переходим ко второй части парсинга – к Директу.
Узнаем точное количество запросов
Для того, чтобы узнать точное количество запросов к каждому ключу, мы нажимаем на синий значок Яндекс-Директа.
Обратите внимание на галочку “Целью запуска является сбор частотностей для колонок Вордстата”. То есть в основном эта функция как раз и используется для того, чтобы узнать точные показатели запросов. Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь
Слишком большая нагрузка на программу, и слишком неточные получаются результаты
Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь. Слишком большая нагрузка на программу, и слишком неточные получаются результаты.
Если вам нужны данные по точной словоформе, то можно еще поставить галочку в поле “!”. После этого нажимаем “Получить данные” и опять отправляемся пить кофе.
Вот что теперь мы имеем:
Как вы видите, наш такой перспективный ключ “телефон доставки пиццы” запрашивают на самом деле не шесть тысяч раз в месяц, а всего 22 раза в месяц. А мы-то уже губы раскатали.
Теперь, когда у нас есть объективные результаты, мы можем переходить к следующим этапам настройки. Это будет фильтр слов. То есть нам надо удалять те ключевые запросы, которые нам явно не подходят. Делать это можно прямо в интерфейсе Словоеба, или можете сначла выгрузить результаты в эксель и работать там. Давайте рассмотрим второй вариант.
Экспорт результатов
Для того, чтобы выгрузить полученные данные, нажмите на значок “эксель” в левом верхнем углу интерфейса, и укажите, куда надо сохранить файл.
Когда вы откроете файл, то увидите примерно вот такую картину:
Теперь вы можете спокойно удалять ненужные ключевые запросы, оставляя только те, по которым к вам точно придут клиенты. После этого вам еще надо будет создать рекламные объявления для каждого запроса. Об этом мы уже говорим подробнее в статье “Как самому настроить контекстную рекламу”.
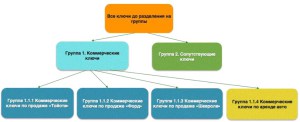
Как создать семантическое ядро?
Формирование семантического ядра — это комплексный процесс, включающий анализ тематики и структуры сайта, работу со специальными сервисами и программами, редактирование базы ключей вручную. Есть два основных принципа создания СЯ:
- подбор максимального количества ключей и дальнейшей очистки;
- подбор точных ключевых фраз с самого начала с последующим расширением базы.
Мы обратились к нескольким SEO-экспертам, чтобы узнать, какой подход они предпочитают.
Тарас Гуща, СЕО в SEO.UA, склоняется к первому методу:
Лучше много ключей и потом чистить. Потому как иногда можно упустить весьма стоящие ключевые фразы. Нам как профессионалам продвижения сайтов надо давать клиентам максимальный результат. Поэтому каждая ключевая фраза, которая может конвертировать потенциальную аудиторию в клиента, очень важна.
А вот Катерина Золотарева, Founder & CEO в Site24, считает, что в зависимости от выбранной стратегии можно использовать оба подхода:
Если проект небольшой или в сложной для формирования семантики нише, например, технологические услуги, то однозначно надо собирать все и даже больше, потом вычеркивать нерелевантное, а околотематические ключи отправлять в блог.
Также имеет смысл глубоко заниматься семантикой, если проект уже имеет позиции, трафик, а стандартные базовые ключи и так уже включены в метатеги и текст. Тогда глубокая проработка семантики поможет вам значительно улучшить видимость и трафик.
Этапы создания семантического ядра
Создание СЯ можно разделить на три этапа.
- Выбор подхода для создания СЯ.
Есть несколько стратегий того, как можно собрать семантического ядро. Их применяют в зависимости от того, имеет ли ресурс структуру или только находится в процессе разработки, какой у него уровень оптимизации, какие позиции по ключевым словам он занимает и т.д..
- Сбор запросов с помощью специальных инструментов.
Сервисы подбора ключевых слов дают возможность охватить максимальное число запросов и поисковых подсказок. Для лучшего результата стоит задействовать инструменты для анализа семантики конкурентов.
- Формирование СЯ из общей базы запросов.
Этапы преобразования облака тематических запросов в семантическое ядро включают два основных этапа:
- очистка базы ключей от ненужных запросов;
- кластеризация путем деления семантики на группы.
Также в процессе анализа ключей можно отделить минус-слова. Кластеризация базы запросов предшествует распределению ключевых фраз по URL. В следующих разделах мы рассмотрим все этапы разработки семантического ядра подробно.
Подходы при создании семантического ядра
Рассмотрим стандартные схемы для создания баз ключей. В зависимости от конкретного случая можно использовать один из подходов, приведенных ниже, или же индивидуальную стратегию.
ПЕРВЫЙ ПОДХОД — ФОРМИРОВАНИЕ СТРУКТУРЫ НОВОГО САЙТА НА ОСНОВЕ СЯ.
- Исследование рыночной ниши/торговой линейки/брифа клиента.
- Определение списка основных запросов (seed keywords).
- Сбор максимального количества фраз для каждого основного ключа.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Очистка полученного списка запросов от дублей и мусорных фраз (при наличии списка минус-слов).
- Автоматическая кластеризация через SE Ranking.
- Окончательная очистка запросов.
- Создание структуры сайта по разделам, категориям, страницам на основе кластеризации.
ВТОРОЙ ПОДХОД — СБОР СЯ ПОД ГОТОВУЮ СТРУКТУРУ САЙТА
- Анализ структуры и разделов сайта.
- Определение списка основных запросов.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Сбор максимального количества релевантных ключевых фраз для запросов из п. 2 и 3.
- Очистка от мусорных и нерелевантных фраз.
- Разделение собранных запросов под существующие категории и страницы.
ТРЕТИЙ ПОДХОД — ОБНОВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА ДЛЯ САЙТА.
- Анализ существующей семантики сайта.
- Поиск «слабых мест»: сбор актуальных запросов в тематике, изучение поисковых подсказок, анализ конкурентов для определения недостающих ключей.
- Создание списка упущенных запросов и распределение их по разделам, категориям, страницам.
Различия между Словоеб_ом и Key Collector_ом
Разницу между программами Словоёб и Key Collector вы можете увидеть в на следующем рисунке (в виде таблицы):
Пусть программа Slovoeb не может получать позиции запросов, выполнять пакетный сбор Google AdWords, производить интеллектуальный сбор поисковых подсказок, выполнять прогноз трафика по контексту и исполнять другие функции, включенные в КейКоллектор, однако другие её функции очень полезны.
Парсинг, анализ заранее введённых слов
Словоёб позволяет выполнять пакетный сбор слов из левой и правой колонки Яндекс.Вордстат, а также пакетный сбор из Рамблер.Адстат, а также собирать в пакетном режиме поисковые подсказки. Далее, полученные слова можно проанализировать — получить частотности, узнать количество вхождений в заголовки внутренних и главных страниц.
Анализ можно провести также для самостоятельно введённых слов.
Прокси-серверы в Словоеб_е
Словоеб поддерживает работу через HTTP прокси-сервера (в том числе и с защитой доступа по паролю). Доступна загрузка списка прокси-серверов из файла или их ручная формировка. После создание списка в ручном режиме, его можно будет экспортировать в файл, нажимая кнопку «Сохранить в файл». Чтобы указать программе прокси-сервер, который следует использовать, нужно отметить строку с этим сервером галочкой. Доступные настройки вы можете увидеть на рисунке:
«Использовать прокси-серверы» — если отметить, то программа начинает использовать прокси-сервера из таблицы прокси-серверов (зелёные, отмеченные флажками).
«Деактивировать на 360 сек. не прошедшие проверку прокси-серверы» — если эта опция включена и программа получила ошибку, то после выполнения быстрой проверки на доступность прокси-сервера и получения сообщения о его недоступности, сервер исключается из очереди прокси-серверов на 360 секунд.
«Отключать в настройках отброшенные при парсинге прокси-серверы» — указание для программы автоматически выключать отброшенный прокси-сервер в таблице прокси-серверов.
«Отключать в настройках деактивированные из-за капчи прокси-серверы» — если вы используете хорошие прокси, то капчу лучше распознавать, нежели отклонять её.
Системные требования
Если подразумевается обработка большого числа данных (количество ключевых слов исчисляется десятками и сотнями тысяч штук), то желательно иметь высокопроизводительный компьютер. В таком случае также важна оперативная память ПК — чем больше, тем лучше. Наиболее оптимальной оперативной памятью является 3Гб, но и при меньших объёмах программа будет работать, правда медленно и менее устойчиво.
Также есть минимальные рекомендуемые системные требования:
- Операционная система Windows 7/8/8.1/10 или Windows XP/Vista
- Объём оперативной памяти от 2 Гб
- Тактовая частота процессора от 1,8 ГГц
- Также требуются дополнительные модули Microsoft.NET Framework 4.5 Full(для Windows 7/8/8.1/10) или Microsoft.NET Framework 4.0 Full(для других версий Windows).
О том, как настроить и использовать эту программу читайте в следующих статьях!
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
| скачать видео бесплатно – 1 111 285 показов | “скачать видео бесплатно” – 8 493 показа |
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
| “!купить !телефон” – 37 909 показов | “!купить !телефоны” – 2 798 показов |
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
| – 4 213 показов | – 1 814 показов |
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
Здесь будут появляться отчеты со статистикой
Маски для интернет-магазина
Для e-commerce метод перемножения подходит лучше всего.
Покупатель выбирает товар по определенным свойствам. Это цвет, размер, высота, наличие морозильной камеры и других характеристик и функций. Здесь важна добавка гео. Например, холодильник. Запрос может быть максимально детальным: «Купить холодильник bosch kgn39nw13r в Перми с доставкой».
Ситуация следующая: компания продает разные категории товаров, но под одним брендом. Если брать только название бренда (как правило, однословник), вы получаете много «мусора», например:
Это сработает только в том случае, если на один бренд — одна категория товаров.
Вряд ли потенциальные клиенты будут искать непонятно что, но конкретной марки. Люди чаще ищут категории. Поэтому на практике нужны 2- и 3-словники.
Русский вариант написания — это отдельный спрос, по нему нужно отдельно собирать маски.
Инструменты для определения частотностей
А теперь к самому интересному – как же определить частотность?
Для этого можно использовать различные сервисы.
В Яндекс WordStat необходимо ввести запрос, выбрать регион, интересующее устройство, нажать «Подобрать», далее сервис покажет результат:
Можно посмотреть статистику по регионам и городам:
Яндекс.Директ – сервис для запуска рекламы в поисковой системе Яндекс. Посмотреть частотность запроса можно при создании рекламной кампании. Доходим до второго шага «Выбор аудитории», задаем регион и нажимаем «Подобрать фразы». При вводе фразы получаем статистику по ним.
Частота запросов в Яндекс.Директ может несколько отличаться от показателей Яндекс.Вордстат. Это происходит, потому что последний не учитывает вложенные запросы с прогнозом меньше пяти. Кроме того, данные берутся за последние 30 дней, но в Директе они обновляются чаще из-за чего могут быть расхождения в пару дней. И наконец, необходимо отслеживать нет ли минус-слов в Яндекс.Директе, которые могут повлиять на статистику.
В случае снятия данных за год, они могут отличаться от данных в сервисе WordStat и быть некорректными.
Google Keyword Planner – инструмент для подбора ключевых слов при создании рекламы в ПС Google. Поможет при сборе статистики по запросам в Google.
Необходимо зайти в инструмент, авторизоваться и выбрать «Найдите новые ключевые слова»:
Далее нужно ввести слова через запятую и нажать «Показать результаты»:
Далее необходимо отметить добавленные слова галочкой (расширить список можно будет дальше), выбрать соответствие (точное, широкое, фразовое) и нажать «Добавить ключевые слова»:
Рядом с каждым запросом появляется зеленый значок «В плане»:
Переходим в пункт меню «Ключевые слова», выбираем корректный регион вверху страницы, раскрываем график по стрелочке, выставляем максимальную цену за клик:
Для анализа нужно использовать столбец «Показы»:
Этот способ покажет точную статистику по Google, насколько это возможно в рамках данной поисковой системы.
SemRush – сервис, который может показать подробную информацию по ключевому слову, в том числе уровень конкурентности, вариации ключевого слова, поисковую выдачу и другие параметры. Часть инструментов в нем платная.
Ahrefs – еще один сервис для просмотра статистики по ключевому слову и подбора аналогов. Также является платным.
Серверы SemRush, Ahrefs и другие подобные инструменты получают данные о количестве запросов методом покупки сlickstream у крупных провайдеров, поэтому их данные будут отличаться от данных в Google Keyword Planner.
Программы для подбора и фильтрации запросов
- Key Collector — по признанию многих оптимизаторов — это лучшая программа для составления семантического ядра;
- Словоеб — младший брат Key Collector;
- Allsubmitter — многофункциональная программа, при помощи которой можно подбирать ключевые слова;
- Магадан — парсер ключевых слов Яндекс.Директа;
- Key Hunter — поиск и парсинг открытых Яндекс.Метрик;
- Metrica Spy — поиск и парсинг открытых Яндекс.Метрик, обсуждение;
- МегаЛемма — софт для морфологической обработки массивов ключевых слов и дальнейшей группировки;
- YWSCheck — парсер Яндекс.Вордстат и Яндекс.Директ;
- Yandex Key Checker — программа проверки ключей в Яндексе на частоту и конкурентность;
- Букварикс — программа для быстрого подбора ключевых слов, обсуждение;
- YaLiPa — парсер прямого эфира Яндекс;
- Kolyan — парсер прямого эфира Яндекс;