Проверка данных регулярными выражениями в php
Содержание:
- preg_match()
- Метасимволы
- Поиск текста функцией «preg_match_all»
- Примеры preg_replace PHP
- Как правильно писать регулярные выражения ¶
- Бекслеши
- Задачки (пока без картинок)
- Специальные конструкции в регулярках
- Строковые методы, поиск и замена
- Практические примеры сложных регулярных выражений
- preg_match_all()
- Основы основ
- Об ограничении «жадности»
- Алгоритм[править]
- Буквы, цифры, символы
- Обработка и замена при помощи «preg_replace_callback»
preg_match()
Функция preg_match() ищет в заданной строке совпадение для шаблона. Если совпадение найдено, возвращается TRUE, в противном случае возвращается FALSE.
Синтаксис функции preg_match():
int pregjnatch(string шаблон, string строка [, array совпадения})
При передаче необязательного параметра совпадения массив заполняется совпадениями различных подвыражений, входящих в основное регулярное выражение. В следующем примере функция preg_match() используется для проведения поиска без учета регистра:
$linе = "Vi is the greatest word processor ever created!";
// Выполнить поиск слова "Vi" без учета регистра символов:
if(preg_match("/\bVi\b\i", $line, $matcn)) :
print "Match found!";
endif;
// Команда if в этом примере возвращает TRUE
Метасимволы
В приведенных выше примерах использовались очень простые шаблоны. Метасимволы позволяют нам выполнять более сложные сопоставления с образцом, например проверять правильность адреса электронной почты. Давайте теперь посмотрим на часто используемые метасимволы.
| Метасимвол | Описание | Пример |
|---|---|---|
| . | Соответствует любому отдельному символу, кроме новой строки | /./ соответствует всему, что имеет один символ |
| ^ | Соответствует началу или строке/исключает символы | /^PH/ соответствует любой строке, начинающейся с PH |
| $ | Соответствует шаблону в конце строки | /ru$/ соответствует it-blog.ru и т.д. |
| * | Соответствует любому нулю (0) или более символов | /com*/ соответствует computer, communication и т. д. |
| + | Требуется, чтобы предшествующие символы появлялись хотя бы раз | /yah+oo/ соответствует yahoo |
| \ | Используется для экранирования метасимволов | /yahoo+\.com/ трактует точку как буквальное значение |
| Символы внутри скобках | // соответствует abc | |
| a-z | Соответствует строчным буквам | /a-z/ соответствует cool, happy и т.д. |
| A-Z | Соответствует заглавным буквам | /A-Z/ соответствует WHAT, HOW, WHY и т.д. |
| 0-9 | Соответствует любому числу от 0 до 9 | /0-4/ соответствует 0,1,2,3,4 |
Приведенный выше список содержит только наиболее часто используемые метасимволы в регулярных выражениях.
Давайте теперь рассмотрим довольно сложный пример, который проверяет действительность адреса электронной почты.
<?php
$my_email = "name@company.com
";
if (preg_match("/^+@+\.{2,5}$/", $my_email)) {
echo "$my_email это действительный адрес электронной почты";
}
else
{
echo "$my_email это не действительный адрес электронной почты";
}
?>

Поиск текста функцией «preg_match_all»
Для поиска текста внутри тегов воспользуемся функцией «preg_match_all». Зададим маску поиска и посмотрим, что она возвращает в качестве результата.
$sContent = "... <xx>наташа</xx> ... <xx>даша</xx> ... <xx>настя</xx> ...";
if (preg_match_all('|<xx>(.+)</xx>|isU', $sContent, $arr)) {
echo $arr . " " . $arr . " " . $arr . "<br />";
echo $arr . " " . $arr . " " . $arr;
}
//на выходе получаем:
//<xx>наташа</xx> <xx>даша</xx> <xx>настя</xx>
//наташа даша настя
В нулевой разряд массива записались значения с тегами, а в первый — только текст между ними. Если требуется автоматизировать вывод всего найденного, то лучше использовать цикл foreach. Его рассмотрим ниже.
Функция preg_match_all возвращает «1» в случае нахождения в тексте соответствия с указанной маской или «0», если соответствий не найдено. В качестве параметров принимает маску, строку где ищем и переменную, в которую будут записаны найденные совпадения.
Маска поиска обрамляется символами «|». За ними идут директивы — «isU» обозначает регистронезависимый поиск в многострочном тексте с кодировкой «UTF-8»
|<xx>(.+)</xx>|isU
В самом правиле содержатся теги, между которыми требуется заменить текст — «(.+)». Точка символизирует любой символ, а плюс — что он может повторяться один или больше раз. Скобки говорят о том, что содержимое между ними нужно записать в переменную с результатом.
Примеры preg_replace PHP
1.
$text = preg_replace("~<a href=\"http://www\.aaa\">+?</a>~",'',$text);
2.
$text = preg_replace('#<!--.*-->#sUi', '', $text);
3.
$text = preg_replace ("~(\\\|\*|\?|\|\(|\\\$|\))~", "",$text);
4.
$text = preg_replace('/(<(+)>)/U', '', $text);
5.
$text = preg_replace('#<script*>.*?</script>#is', '', $text);
6.
$text = str_replace('#39;', '', $text); // удаляем одинарные кавычки
$text = str_replace('"', '', $text); // удаляем двойные кавычки
$text = str_replace('&', '', $text); // удаляем амперсанд
$text = preg_replace('/(()_—«»#\/]+)/', '', $text); // удаляем недоспустимые символы
7.
$text = trim($text); // удаляем пробелы по бокам
$text = preg_replace('/ /', '', $text); // чистим обычные пробелы
$text = preg_replace("/ +/", " ", $text); // множественные пробелы заменяем на одинарные
8.
$text = preg_replace("/(\r\n){3,}/", "\r\n\r\n", $text); // убираем лишние переводы строк (больше 1 строки)
9.
$file = 'image.jpg';
$file = preg_replace("/.*?\./", '', $file); // выведет image
10.
function ProcessText($text)
{
$text = trim($text); // удаляем пробелы по бокам
$text = stripslashes($text); // удаляем слэши
$text = htmlspecialchars($text); // переводим HTML в текст
$text = preg_replace("/ +/", " ", $text); // множественные пробелы заменяем на одинарные
$text = preg_replace("/(\r\n){3,}/", "\r\n\r\n", $text); // убираем лишние переводы строк (больше 1 строки)
$test = nl2br ($text); // заменяем переводы строк на тег
$text = preg_replace("/^\"(+)\"/u", "$1«$2»", $text); // ставим людские кавычки
$text = preg_replace("/(«){2,}/","«",$text); // убираем лишние левые кавычки (больше 1 кавычки)
$text = preg_replace("/(»){2,}/","»",$text); // убираем лишние правые кавычки (больше 1 кавычки)
$text = preg_replace("/(\r\n){2,}/u", "</p><p />", $text); // ставим абзацы
return $text; //возвращаем переменную
}
11.
$string = preg_replace("!<title>(.*?)</title>!si","<НОВЫЙ_ТЕГ>\\1</НОВЫЙ_ТЕГ>",$string);
12.
$text = preg_replace('#(\.|\?|!|\(|\)){3,}#', '\1\1\1', $text);
13.
$string = preg_replace("/^/", "Начало: ", $string); // в начало
$string = preg_replace("/$/", " читать далее...", $string); // в конец
14.
$text = preg_replace('#(?<!\])\bhttp://+#i',
"<a href=\"$0\" target=_blank><u>Посмотреть на сайте</u></a>",
nl2br(stripslashes($text)));
15.
$str = preg_replace('/^(.+?)(\?.*?)?(#.*)?$/', '$1$3', $url);
16.
$string = preg_replace("/^/", "
", $string); // в начало всех строк
$string = preg_replace("/$/", "
", $string); // в конец всех строк
17.
// $document на выходе должен содержать HTML-документ.
// Необходимо удалить все HTML-теги, секции javascript,
// пробельные символы. Также необходимо заменить некоторые
// HTML-сущности на их эквивалент.
$search = array ("'<script*?>.*?</script>'si", // Вырезает javaScript
"'<[\/\!]*?*?>'si", // Вырезает HTML-теги
"'()+'", // Вырезает пробельные символы
"'&(quot|#34);'i", // Заменяет HTML-сущности
"'&(amp|#38);'i",
"'&(lt|#60);'i",
"'&(gt|#62);'i",
"'&(nbsp|#160);'i",
"'&(iexcl|#161);'i",
"'&(cent|#162);'i",
"'&(pound|#163);'i",
"'&(copy|#169);'i",
"'&#(\d+);'e"); // интерпретировать как php-код
$replace = array ("",
"",
"\\1",
"\"",
"&",
"<",
">",
" ",
chr(161),
chr(162),
chr(163),
chr(169),
"chr(\\1)");
$text = preg_replace($search, $replace, $document);
18.
$html = preg_replace( '/(\S+)@(+)/is', '<a href="mailto:$0">$0</a>', $text);
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли «Я хочу найти/заменить/удалить то-то и то-то». Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101.com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: «Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?». Затем нужен список валидных и невалидных адресов:
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой — любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
Обратите внимание, что я использовал границу слова \b, чтобы искать полные байты. Пробуем регулярку в деле:
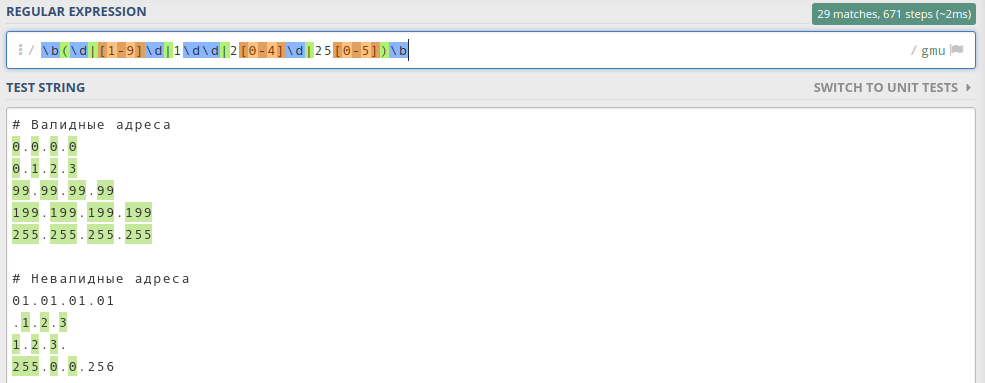
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
Результат выглядит так:

Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Бекслеши
Если ты смотрел другие учебники по регулярным выражениям, то наверно заметил,
что бекслеш везде пишут по-разному. Где-то пишут один бекслеш:
, а здесь в примерах он повторен 2 раза: .
Почему?
Язык регулярных выражений требует писать бекслеш один раз. Однако в
строках в одиночных и двойных кавычках в PHP бекслеш тоже имеет особое
значение: .
Ну например, если написать то PHP воспримет это как
специальную комбинацию и вставит в строку только символ
(и движок регулярных выражений не узнает о бекслеше перед ним). Чтобы
вставить в строку последовательность , мы должны удвоить бекслеш
и записать код в виде .
По этой причине в некоторых случаях (там, где последовательность символов
имеет специальный смысл в PHP) мы обязаны удваивать бекслеш:
- Чтобы написать в регулярке , мы пишем в коде
- Чтобы написать в регулярке , мы удваиваем каждый
бекслеш и пишем - Чтобы написать в регулярке бекслеш и цифру (),
бекслеш надо удвоить:
В остальных случаях один или два бекслеша дадут один и тот же
результат: и вставят в строку пару
символов — в первом случае 2 бекслеша это последовательность
для вставки бекслеша, во втором случае специальной последовательности
нет и символы вставятся как есть. Проверить, какие символы вставятся в строку,
и что увидит движок регулярных выражений, можно с помощью
echo: . Да, сложно, а что поделать?
Задачки (пока без картинок)
- На вход скрипта дан введенный пользователем номер телефона в
виде 8-911-404-44-11 или +7(812)6786767 (в начале 8 или +7, потом идут 10 цифр и, возможно, какие-то символы).
То есть, как и в прошлой задаче, человек вводит номер как хочет.
Надо проверить номер на правильность и привести любой номер к единому формату 89114044411
(то есть, заменить +7 на 8 и выкинуть весь мусор вроде пробелов, скобок и минусов, кроме цифр) - Автозамена. Напиши скрипт, заменяющий определенное слово на другое (например, слово
«дурак» на «хороший человек» в фразе «ты дурак»). Скрипт должен не пропускать слово,
если оно написано буквами в разном регистре (ДуРАк), с заменой русских букв
на похожие английские (а -> a), или через пробелы («ты — д у р а к») - Дан текст, содержащий в себе email’ы (адреса почты вроде you+me@some.domain-domain.com ). Напиши
скрипт, выводящий все email, встречающиеся в этом тексте - «Grammar Nazi». Напиши скрипт, проверяющий текст на наличие злостных ошибок:
- нет пробела после запятой, точки с запятой, восклицательного знака,
вопросительного знака, двоеточия - «жи» или «ши» написано с буквой ы
- в тексте есть слово «координально» или «сдесь», «зделал», «зделаю», «зделан»
- в тексте есть слова «а» или «но» без запятой перед ними.
- (можешь добавить еще несколько правил, если хорошо знаешь русский язык)
В случае обнаружения ошибки скрипт должен писать сообщение об этом и выводить
кусок текста с ошибкой (чтобы было понятно, что не так). - нет пробела после запятой, точки с запятой, восклицательного знака,
- Если ты сделал задачу про Grammar Nazi, сделай скрипт, которы вместо сообщения об ошибках будет
молча их исправлять.
Специальные конструкции в регулярках
-
ищет одну любую цифру, — один
любой символ, кроме цифры -
соответствует одной любой букве (любого алфавита), цифре
или знаку подчеркивания . соответствует
любому символу, кроме буквы, цифры, знака подчеркивания.
Также, есть удобное условие для указания на границу слова: .
Эта конструкция обозначает, что с одной стороны от нее должен стоять символ,
являющийся буквой/цифрой/знаком подчеркивания (), а с
другой стороны — не являющийся. Ну, например, мы хотим найти в тексте слово
«кот». Если мы напишем регулярку , то она
найдет последовательность этих букв в любом месте — например, внутри слова
«скотина». Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку: , то теперь
искаться будет только отдельно стоящее слово «кот».
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3059
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
preg_match_all()
Функция preg_match_all() находит все совпадения шаблона в заданной строке.
Синтаксис функции preg_match_all():
Int preg_match_all(string шаблон, string строка, array совпадения )
Порядок сохранения в массиве совпадения текста, совпавшего с подвыражениями, определяется необязательным параметром порядок. Этот параметр может принимать два значения:
- PREG_PATTERN_ORDER — используется по умолчанию, если параметр порядок не указан. Порядок, определяемый значением PREG_PATTERN_ORDER, на первый взгляд выглядит не совсем логично: первый элемент(с индексом 0) содержит массив совпадений для всего регулярного выражения, второй элемент(с индексом 1) содержит массив всех совпадений для первого подвыражения в круглых скобках и т.д.;
- PREG_SET_ORDER — порядок сортировки массива несколько отличается от принятого по умолчанию. Первый элемент (с индексом 0) содержит массив с текстом, совпавшим со всеми подвыражениями в круглых скобках для первого найденного совпадения. Второй элемент (с индексом 1) содержит аналогичный массив для второго найденного совпадения и т.д.
Следующий пример показывает, как при помощи функции preg_match_al() найти весь текст, заключенный между тегами HTML <b>…</b>:
$user_info = "Name: <b>Rasmus Lerdorf</b> <br> Title: <b>PHP Guru</b>";
preg_match_all("/<b>(.*)<\/b>/U", $userinfo, $pat_array);
print $pat_array." <br> ".pat_array."\n":
Результат:
Rasmus Lerdorf PHP Guru
Основы основ
Для начала нужно понять что в Regex есть специальные символы (например символ начала строки — ), если вы хотите просто найти данный символ, то нужно ввести обратный слеш перед символом для того, чтобы символ не работал как команда.
Для того чтобы найти текст, нужно собственно просто ввести этот текст:
Якори
— символ который обозначает начало строки
— символ который обозначает конец строки
Найдем строки которые начинаются с The Beginning:
Найдем строки, которые заканчиваются на The End:
Найдем строки, которые начинаются и заканчиваются на The Beginning and The End:
Найдем пустые строки:
Квантификаторы
— символ, который указывает на то, что выражение до него должно встретиться 0 или 1 раз
— символ, который указывает на то, что выражение до него должно встретиться один или больше раз
— символ, который указывает на то, что выражение до него должно встретиться 0 или неопределённое количество раз
— скобки с одним аргументом указывают сколько раз выражение до них должно встретиться
— скобки с двумя аргументами указывают на то, от скольки до скольки раз выражение до них должно встретиться
— скобки объединяют какое-то предложение в выражение. Обычно используется в связке с квантификаторами
Давайте попробуем найти текст, в котором будут искаться все слова, содержащие ext или ex:
Давайте попробуем найти текст, в котором слова будут содержать ext или e:
Найти все размеры одежды (XL, XXL, XXXL):
Найти все слова, у которых есть неограниченное число символов c, после которых идёт haracter:
Найти выражение, в котором слово word повторяется от одного до неограниченного количества раз:
Найти выражение, в котором выражение ch повторяется от 3 до неограниченного количества раз:
Выражение «или»
— символ, который обозначает оператор «или»
— выражение в квадратных скобках ставит или между каждым подвыражением
Найти все слова, в которых есть буквы a,e,c,h,p:
Найти все выражения в которых есть ch или pa:
Escape-последовательности
— отмечает один символ, который является цифрой (digit)\
— отмечает символ, который не является цифрой
— отмечает любой символ (число или букву (или подчёркивание)) (word)
— отмечает любой пробельный символ (space character)
— отмечает любой символ (один)
Выражения в квадратных скобках
Кроме того, что квадратные скобки служат оператором «или» между каждым символом, который в них заключён, они также могут служить и для некоторых перечислений:
— один символ от 0 до 9
— любой символ от a до z
— любой символ от A до Z
— любой символ кроме a — z
Найти все выражения, в которых есть английские буквы в нижнем регистре или цифры:
Флаги
Флаги — символы (набор символов), которые отвечают за то, каким именно образом будет происходить поиск.
Форма условия поиска в Regex выглядит вот так:
— флаг, который будет отмечать все выражения, которые соответствуют условиям поиска (по умолчанию поиск возвращает только первое выражение, которое подходит по условию) (global)
— флаг, который заставляет искать выражения вне зависимости от региста (case insensitive)
Теперь вы знаете базовые знания по Regex и можете использовать их в языках программирования, консольных утилитах или в программируемых редакторах (привет, Vim). Если вам интересен данный материал, а также интересны темы веб-разработки и администрирования Unix-подобных систем, то вы можете подписаться на мой телеграм-канал, там много всякого разного и полезного.
Об ограничении «жадности»
Для понимания, о чем идет речь, лучше сначала ознакомиться с примером:
Здесь шаблон поиска выглядит следующим образом: ‘a’, любой символ один и больше раз, ‘x’. Но выражение сработало не так, как ожидал разработчик: было захвачено максимально возможное число символов, т. е. закончилась не на первом ‘x’, а на последнем.
Данное поведение операторов повторения называют жадностью, т. к. они стремятся забрать как можно больше. Это особенность полезна, но не всегда, поэтому ее можно отменить, ограничив жадность. Для этого надо добавить к оператору повторения знак ‘?’: вместо жадных ‘+’ и » следует написать ‘+?’ и ‘?’, что ограничит эту самую жадность:
В примере выше шаблон поиска выглядит так: ‘a’, потом любой символ один либо больше раз (с ограничением жадности) и ‘x’.
Посредством ‘?’ была ограничена жадность плюсу, поэтому теперь поиск осуществляется до первого совпадения.
Жадность можно ограничивать для всех операторов повторения, включая ‘?’, ‘{}’ — выглядеть это будет так: ‘??’ и ‘{}?’.
Алгоритм[править]
Данный алгоритм работает быстрее недетерминированного конечного автомата, построенного по теореме Клини, но только для регулярных выражений, состоящих из символов:
- — один любой буквенный символ,
- — один любой символ,
- — символ начала текста,
- — символ конца текста,
- — предыдущий символ встречается ноль или более раз.
Например, для , очевидно, проще написать простой сопоставитель, чем строить НКА.
Псевдокодправить
function match(regexp: String, text: String): boolean
if regexp == '^'
return matchHere(regexp, text)
int i = 0
while i text.length
if matchHere(regexp, text)
return true
i++
return false
Функция проверяет есть ли вхождение регулярного выражения в любом месте в пределах текста. Если существует более одного вхождения, то найдется самое левое и самое короткое.
Логика функции проста. Если — первый символ регулярного выражения, то любое возможное вхождение должно начинаться в начале текста. То есть если — регулярное выражение, то должно входить в текст только с первой позиции текста, а не где-то в середине текста. Это проверяется путем сопоставления остатка регулярного выражения с текстом, начиная с первой позиции и нигде более.
В противном случае регулярное выражение может входить в текст в любой позиции. Это проверяется путем сопоставления регулярного выражения во всех позициях текста. Если регулярное выражение входит более одного раза в текст, то только самое левое вхождение будет распознано. То есть если — регулярное выражение, то для него найдется самое левое вхождение в текст.
function matchHere(regexp: String, text: String): boolean
if regexp == '\0'
return true
if regexp == '*'
return matchStar(regexp, regexp, text)
if regexp == '$' and regexp == '\0'
return text == '\0'
if text != '\0' and (regexp == '.' or regexp == text)
return matchHere(regexp, text)
return false
Основная часть работы сделана в , которая сопоставляет регулярное выражение с текстом в текущей позиции. Функция пытается сопоставить первый символ регулярного выражения с первым символом текста. В случае успеха мы можем сравнить следующий символ регулярного выражения со следующим символом текста, вызвав рекурсивно. Иначе нет совпадения с регулярным выражением в текущей позиции текста.
function matchStar(c: char, regexp: String, text: String): boolean
int i = 0
while i text.length and (text == c or c == '.')
if matchHere(regexp, text)
return true
i++
return false
Рассмотрим возможные случаи:
- Если в ходе рекурсии регулярное выражение осталось пустым то текст допускается этим регулярным выражением.
- Если регулярное выражение имеет вид , то вызывается функция которая пытается сопоставить повторение символа , начиная с нуля повторений и увеличивая их количество, пока не найдет совпадение с оставшимся текстом. Если совпадение не будет найдено, то регулярное выражение не допускает текст. Текущая реализация ищет «кратчайшее совпадение», которое хорошо подходит для сопоставления с образцом, как в grep, где нужно как можно быстрее найти совпадение. «Наидлиннейшее совпадение» более интуитивно и больше подходит для текстовых редакторов, где найденное заменят на что-то. Большинство современных библиотек для работы с регулярными выражениями предоставляют оба варианта.
- Если регулярное выражение это , то оно допускает этот текст тогда и только тогда, когда текст закончился.
- Если первый символ текста совпал с первым символом регулярного выражения, то нужно проверить совпадают ли следующий символ регулярного выражения со следующим символом текста, сделав рекурсивный вызов .
- Если все предыдущие попытки найти совпадения провалились, то никакая подстрока из текста не допускается регулярным выражением.
Модификацииправить
Немного изменим функцию для поиск самого левого и самого длинного вхождения :
- Найдем максимальную последовательность подряд идущих символов . Назовем ее .
- Сопоставим часть текста без с остатком регулярного выражения.
- Если части совпали, то текст допускается этим регулярным выражением. Иначе, если пусто, то текст не допускается этим регулярным выражением, иначе убираем один символ из и повторяем шаг .
Псевдокодправить
function matchStar(c: char, regexp: String, text: String): boolean
int i
for (i = 0; text != '\0' and (text == c or c == '.'); i++)
while i 0
if matchHere(regexp, text)
return true
i--
return false
Буквы, цифры, символы
В регулярных выражениях существуют два вида символов: обозначающие сами себя и символы, которые называют командами (спецсимволы).
Цифры и буквы обозначают сами себя, зато точка — спецсимвол, обозначающий «любой символ». Смотрим примеры:

По сути, в коде выше не существует разницы между функциями preg_replace и str_replace – функционируют они одинаково, разница заключается лишь в ограничителях.
В следующем примере можно увидеть, как использовался спецсимвол «точка» — такое уже нельзя сделать с помощью str_replace:

Раз точка — любой символ, то под регулярку подпадут все подстроки, причем по следующему шаблону: буква ‘x’, потом любой символ, потом снова ‘x’. Первые четыре подстроки попали под данный шаблон (xax xsx x&x x-x), поэтому они заменились на ‘!’. Последняя подстрока (xaax) не подпала по той причине, что внутри (между буквами ‘x’) находится не один, а два символа.
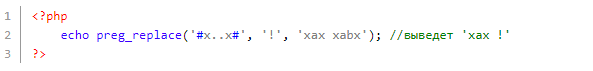
Раз точка — любой символ, а в регулярке мы видим 2 точки подряд, то под регулярку подпадут все подстроки по следующему шаблону: буква ‘x’, потом 2 любых символа, потом снова ‘x’. Первая подстрока не подпадет, т. к. она содержит лишь один символ между буквами ‘x’, в то время как последняя подстрока (xabx) шаблону соответствует.
Что тут важно запомнить: цифры и буквы обозначают сами себя, точка же заменяет любой символ. Также важно следующее: для функции preg_match точка на деле обозначает любой символ за исключением перевода строки
Дабы точка обозначала и его, необходим модификатор s.
Обработка и замена при помощи «preg_replace_callback»
Переходим к самому интересному. Если нужно над найденным фрагметом произвести какие-то действия и только потом осуществить замену, то следует использовать «preg_replace_callback». Рассмотрим как с помощью этой функции в именах сделать первую букву заглавной.
<html>
<head> <meta charset="utf-8"> </head>
<body>
<?php
$sContent = "<xx>наташа</xx> ... <xx>даша</xx> ... <xx>настя</xx>";
echo htmlspecialchars($sContent); echo "<br />";
$sContent = preg_replace_callback('|(<xx>)(.+)(</xx>)|iU', function($matches){
$matches = mb_substr(mb_strtoupper($matches, 'UTF-8'),0,1,'UTF-8').substr($matches, 2);
return $matches.$matches.$matches;
}
,$sContent);
echo htmlspecialchars($sContent);
?>
</body>
</html>
В качестве параметров передаём маску поиска, функцию с кодом обработки и строковую переменную в которой осуществляем поиск. Дополнительно могут ещё быть заданы два необязательных параметра. О них в следующем разделе статьи.
Переменная «$matches» это массив, содержащий элементы регулярного выражения. В нулевом элементе будет содержаться вся исходная строка, а в остальных — содержимое скобок.
Код обработки не описываю, но отмечу что для замены первой буквы на заглавную я использую PHP функции для работы со строками в UTF-8 кодировке. Если у Вас кодировка cp1251, то нужно отбросить префикс «mb_» и удалить последний параметр у функций.
ВНИМАНИЕ! Код в примере будет работать только при использовании PHP версии 5.3 и выше. Для более поздних версий требуется доработка