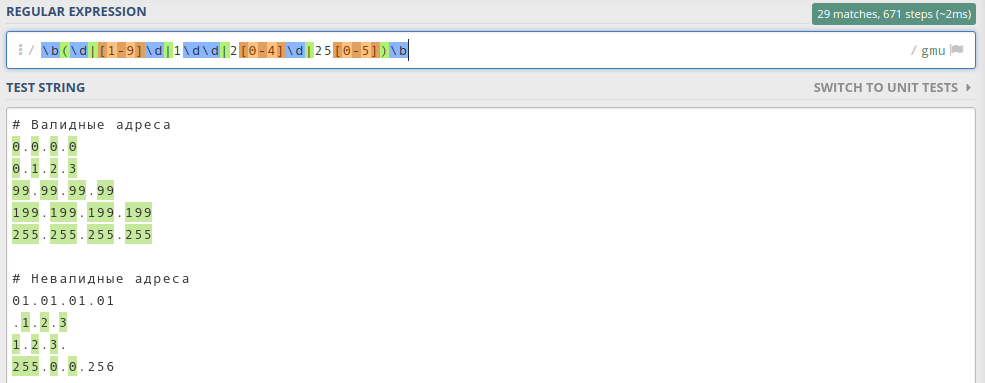
Методы regexp и string
Содержание:
- Special characters
- Нечёткие регулярные выражения
- Мультипликаторы
- Экранирование
- Принцип работы регулярных выраженийHow regular expressions work
- Unicode. Алфавиты и блоки: \р, \Р
- Оптимизация RegExp
- Inline Modifiers
- Алгоритм[править]
- Look arounds
- Characters
- Диапазоны символов
- Anchors
- Используем флаги в регулярных выражениях
- Grabbing HTML Tags
- Основы основ
- Заключение
Special characters
Escapes also allow you to specify individual characters that are otherwise hard to type. You can specify individual unicode characters in five ways, either as a variable number of hex digits (four is most common), or by name:
-
: 2 hex digits.
-
: 1-6 hex digits.
-
: 4 hex digits.
-
: 8 hex digits.
-
, e.g. matches the basic smiling emoji.
Similarly, you can specify many common control characters:
-
: bell.
-
: match a control-X character.
-
: escape ().
-
: form feed ().
-
: line feed ().
-
: carriage return ().
-
: horizontal tabulation ().
-
match an octal character. ‘ooo’ is from one to three octal digits, from 000 to 0377. The leading zero is required.
Нечёткие регулярные выражения
В некоторых случаях регулярные выражения удобно применить для анализа текстовых фрагментов на естественном языке, то есть написанных людьми, и, возможно, содержащих опечатки либо нестандартные варианты употреблений слов. Например, если проводить опрос (допустим, на веб-сайте) «какой станцией метро вы пользуетесь», может оказаться, что «Невский проспект» посетители могут указать как:
- Невский
- Невск. просп.
- Нев. проспект
- наб. Канала Грибоедова («Канал Грибоедова» — это название второго выхода ст. м. Невский проспект)
Здесь обычные регулярные выражения неприменимы, в первую очередь из-за того, что входящие в образцы слова могут совпадать не очень точно (нечётко), но, тем не менее, было бы удобно описывать регулярными выражениями структурные зависимости между элементами образца,
например, в нашем случае, указать, что совпадение может быть с образцом «Невский проспект» ИЛИ «Канал Грибоедова», притом «проспект» может быть сокращено до «пр» или отсутствовать, а перед «Канал» может находиться сокращение «наб.»
Эта задача сродни полнотекстовому поиску, отличаясь в том, что здесь короткий фрагмент должен сравниваться с набором образцов, а при полнотекстовом поиске, наоборот, образец обычно один, в то время как фрагмент текста очень большой, или задаче разрешения лексической многозначности, которая, однако, не позволяет задать структурирующие отношения между элементами образца.
Существует небольшое количество библиотек, реализующих механизм регулярных выражений с возможностью нечёткого сравнения:
- TRE — бесплатная библиотека на С, использующая синтаксис регулярных выражений, похожий на POSIX (стабильный проект);
- FREJ — open-source библиотека на Java, использующая Lisp-образный синтаксис и лишённая многих возможностей обычных регулярных выражений, но сосредоточенная на различного рода автоматических заменах фрагментов текста (бета-версия).
Мультипликаторы
Мультипликаторы позволяют увеличить количество раз появления элемента в нашем регулярном выражении. Вот основной набор мультипликаторов:
— значение встречается 0 или более раз;
— значение встречается 1 или более раз;
— значение встречается 0 или 1 раз;
— значение встречается 5 раз;
— значение встречается от 3 до 7 раз;
— значение встречается не менее 2 раз.
Их действие распространяется на всё, что находится прямо перед ними. Это может быть обычный символ, например:
В примере, приведенном выше, мы ищем символ , за которым следует символ ноль или более раз. Вот почему в слове также является совпадением (это , за которым идет символ ноль раз).
Или это может быть метасимвол, например:
На первый взгляд такой результат может показаться вам немного странным. Регулярное выражение соответствует повторению ноль или более раз любого символа. Вы могли бы подумать, что при нахождении первого , будет сказано «да, я нашел совпадение», но на самом деле говорится, что « является любым символом, поэтому давайте посмотрим, на сколько длинным может быть соответствие», и поиск продолжится, пока не будет найден последний в строке.
Это то, что называется «жадным сопоставлением». Это нормальное поведение — пытаться найти самую большую строку, которая может соответствовать шаблону. Мы можем изменить это поведение и сделать его «нежадным», поместив вопросительный знак () после мультипликатора (что может показаться немного запутанным, поскольку вопросительный знак сам по себе является множителем):
Экранирование
Иногда нам может потребоваться найти один из символов, который является метасимволом. Для этого мы используем то, что называется экранированием. Поместив обратную косую черту () перед метасимволом, мы можем удалить его особое значение. Допустим, что нам нужно найти появление слова , которое является последним словом в предложении.
Если бы мы сделали следующее:
То нашли бы как в конце предложения, так и в начале, потому что точка в регулярном выражении обычно соответствует любому символу.
Решением будет следующее:
Совет: Когда метасимволы являются частью вашей искомой строки, то очень легко забыть об их экранировании. Если в результатах ваших регулярных выражений что-то не так, то внимательно обследуйте метасимволы, которые вы, возможно, забыли экранировать.
Принцип работы регулярных выраженийHow regular expressions work
Главный компонент обработки текста с помощью регулярных выражений — это механизм регулярных выражений, представленный в .NET объектом System.Text.RegularExpressions.Regex.The centerpiece of text processing with regular expressions is the regular expression engine, which is represented by the System.Text.RegularExpressions.Regex object in .NET. Как минимум, для обработки текста с использованием в регулярных выражений механизму регулярных выражений необходимо предоставить два следующих элемента:At a minimum, processing text using regular expressions requires that the regular expression engine be provided with the following two items of information:
-
Шаблон регулярного выражения для определения текста.The regular expression pattern to identify in the text.
В .NET шаблоны регулярных выражений определяются специальным синтаксисом или языком, который совместим с регулярными выражениями Perl 5 и добавляет дополнительные возможности, например сопоставление справа налево.In .NET, regular expression patterns are defined by a special syntax or language, which is compatible with Perl 5 regular expressions and adds some additional features such as right-to-left matching. Дополнительные сведения см. в разделе Элементы языка регулярных выражений. Краткий справочник.For more information, see Regular Expression Language — Quick Reference.
-
Текст, который будет проанализирован на соответствие шаблону регулярного выражения.The text to parse for the regular expression pattern.
Методы класса Regex позволяют выполнять следующие операции:The methods of the Regex class let you perform the following operations:
-
Получить один или все экземпляры текста, соответствующего шаблону регулярного выражения с помощью метода Regex.Match или Regex.Matches.Retrieve one or all occurrences of text that matches the regular expression pattern by calling the Regex.Match or Regex.Matches method. Первый метод возвращает объект System.Text.RegularExpressions.Match, который предоставляет сведения о соответствующем тексте.The former method returns a System.Text.RegularExpressions.Match object that provides information about the matching text. Второй метод возвращает объект MatchCollection, содержащий один объект System.Text.RegularExpressions.Match для каждого соответствия, обнаруженного в обработанном тексте.The latter returns a MatchCollection object that contains one System.Text.RegularExpressions.Match object for each match found in the parsed text.
-
Заменить текст, соответствующий шаблону регулярного выражения, с помощью метода Regex.Replace.Replace text that matches the regular expression pattern by calling the Regex.Replace method. Примеры использования метода Replace для изменения форматов даты и удаления недопустимых символов из строки см. в разделах Руководство. Исключение недопустимых символов из строки и Руководство. Изменение форматов даты.For examples that use the Replace method to change date formats and remove invalid characters from a string, see How to: Strip Invalid Characters from a String and Example: Changing Date Formats.
Обзор объектной модели регулярных выражений см. в разделе Объектная модель регулярных выражений.For an overview of the regular expression object model, see The Regular Expression Object Model.
Дополнительные сведения о языке регулярных выражений см. в кратком справочнике по элементам языка регулярных выражений или в одной из следующих брошюр, который вы можете скачать и распечатать:For more information about the regular expression language, see Regular Expression Language — Quick Reference or download and print one of these brochures:
- Краткий справочник в формате Word (DOCX);Quick Reference in Word (.docx) format
- Краткий справочник в формате PDF (PDF).Quick Reference in PDF (.pdf) format
Unicode. Алфавиты и блоки: \р, \Р
Свойства Unicode, алфавиты и блоки: \р{свойство}, \Р{свойство}. На концептуальном уровне Юникод представляет собой отображение множества символов на множество кодов, но стандарт Юникода не сводится к простому перечислению пар. Он также определяет атрибуты символов (например, «этот символ является строчной буквой», «этот символ пишется справа налево», «этот символ является диакритическим знаком, который должен объединяться с другим символом» и т. д.).
Уровень поддержки этих атрибутов зависит от конкретной программы, но многие программы с поддержкой Юникода позволяют находить хотя бы некоторые из них при помощи конструкций \p{атрибут} (символ, обладающий указанным атрибутом) и \P{атрибут} (символ, не обладающий атрибутом).
Оптимизация RegExp
Рекомендации по оптимизации регулярных выражений.
- Ускоренное достижение совпадения. Руководствуясь знаниями принципов работы традиционного механизма НКА, можно привести механизм к совпадению по ускоренному пути. Рассмотрим пример this|that. Каждая альтернатива начинается с th, если у первой альтернативы не найдется совпадение для th, то th второй альтернативы тоже заведомо не совпадет, поэтому такая попытка заведомо завершится неудачей. Чтобы время не тратилось даром, можно сформулировать то же выражение в виде th(?:is|at). В этом случае th проверяется всего один раз, а относительно затратная конструкция выбора откладывается до момента, когда она становится действительно необходимой. Кроме того, в выражении th(?:is|at) проявляется начальный литерал th, что позволяет задействовать ряд других оптимизаций.
- Привязка к началу текста/логической строки. Эта разновидность оптимизации понимает, что регулярные выражения, начинающиеся с ^, могут совпасть только от начала строки, поэтому их не следует применять с других позиций.
- Привязка к концу текста/логической строки. Эта разновидность оптимизации основана на том, что совпадения некоторых регулярных выражений, завершающихся метасимволом $ или другими якорями конца строки, должны отделяться от конца строки определенным количеством байтов. Например, для выражения regex(es)?$ совпадение должно начинаться не более чем за восемь символов от конца строки, поэтому механизм может сразу перейти к этой позиции. При большой длине целевого текста это существенно сокращает количество начальных позиций поиска. Восемь, а не семь, потому что во многих диалектах $ может совпадать перед завершающим символом новой строки.
- Исключение по первому символу/классу/подстроке. Данный вид оптимизации руководствуется информацией (любое совпадение должно начинаться с конкретного символа или подстроки), на основании которой производится быстрая проверка и применение регулярного выражения только с соответствующих позиций строки. Например, выражение this|that|other может совпадать только в позициях, начинающихся с ; механизм проверяет все символы строки и применяет выражение только с соответствующих позиций, что может привести к огромной экономии времени. Чем длиннее проверяемая строка, тем меньше вероятность ложной идентификации начальных позиций.
- Используйте несохраняющие круглые скобки. Если вы не используете текст, совпадающий с подвыражениями в круглых скобках, используйте несохраняющие скобки (?:…). Помимо прямого выигрыша из-за отсутствия затрат на сохранение появляется побочная экономия – состояния, используемые при возврате, становятся менее сложными и поэтому быстрее восстанавливаются.
Inline Modifiers
(?s)(?m)
| Modifier | Legend | Example | Sample Match |
|---|---|---|---|
| (?i) |
(except JavaScript) |
(?i)Monday | monDAY |
| (?s) | (except JS and Ruby). The dot (.) matches new line characters (\r\n). Also known as «single-line mode» because the dot treats the entire input as a single line | (?s)From A.*to Z | From Ato Z |
| (?m) |
(except Ruby and JS) ^ and $ match at the beginning and end of every line |
(?m)1\r\n^2$\r\n^3$ | 123 |
| (?m) | : the same as (?s) in other engines, i.e. DOTALL mode, i.e. dot matches line breaks | (?m)From A.*to Z | From Ato Z |
| (?x) |
(except JavaScript). Also known as comment mode or whitespace mode |
(?x) # this is a# commentabc # write on multiple# linesd # spaces must be# in brackets | abc d |
| (?n) | Turns all (parentheses) into non-capture groups. To capture, use . | ||
| (?d) | The dot and the ^ and $ anchors are only affected by \n | ||
| (?^) | Unsets ismnx modifiers |
Алгоритм[править]
Данный алгоритм работает быстрее недетерминированного конечного автомата, построенного по теореме Клини, но только для регулярных выражений, состоящих из символов:
- — один любой буквенный символ,
- — один любой символ,
- — символ начала текста,
- — символ конца текста,
- — предыдущий символ встречается ноль или более раз.
Например, для , очевидно, проще написать простой сопоставитель, чем строить НКА.
Псевдокодправить
function match(regexp: String, text: String): boolean
if regexp == '^'
return matchHere(regexp, text)
int i = 0
while i text.length
if matchHere(regexp, text)
return true
i++
return false
Функция проверяет есть ли вхождение регулярного выражения в любом месте в пределах текста. Если существует более одного вхождения, то найдется самое левое и самое короткое.
Логика функции проста. Если — первый символ регулярного выражения, то любое возможное вхождение должно начинаться в начале текста. То есть если — регулярное выражение, то должно входить в текст только с первой позиции текста, а не где-то в середине текста. Это проверяется путем сопоставления остатка регулярного выражения с текстом, начиная с первой позиции и нигде более.
В противном случае регулярное выражение может входить в текст в любой позиции. Это проверяется путем сопоставления регулярного выражения во всех позициях текста. Если регулярное выражение входит более одного раза в текст, то только самое левое вхождение будет распознано. То есть если — регулярное выражение, то для него найдется самое левое вхождение в текст.
function matchHere(regexp: String, text: String): boolean
if regexp == '\0'
return true
if regexp == '*'
return matchStar(regexp, regexp, text)
if regexp == '$' and regexp == '\0'
return text == '\0'
if text != '\0' and (regexp == '.' or regexp == text)
return matchHere(regexp, text)
return false
Основная часть работы сделана в , которая сопоставляет регулярное выражение с текстом в текущей позиции. Функция пытается сопоставить первый символ регулярного выражения с первым символом текста. В случае успеха мы можем сравнить следующий символ регулярного выражения со следующим символом текста, вызвав рекурсивно. Иначе нет совпадения с регулярным выражением в текущей позиции текста.
function matchStar(c: char, regexp: String, text: String): boolean
int i = 0
while i text.length and (text == c or c == '.')
if matchHere(regexp, text)
return true
i++
return false
Рассмотрим возможные случаи:
- Если в ходе рекурсии регулярное выражение осталось пустым то текст допускается этим регулярным выражением.
- Если регулярное выражение имеет вид , то вызывается функция которая пытается сопоставить повторение символа , начиная с нуля повторений и увеличивая их количество, пока не найдет совпадение с оставшимся текстом. Если совпадение не будет найдено, то регулярное выражение не допускает текст. Текущая реализация ищет «кратчайшее совпадение», которое хорошо подходит для сопоставления с образцом, как в grep, где нужно как можно быстрее найти совпадение. «Наидлиннейшее совпадение» более интуитивно и больше подходит для текстовых редакторов, где найденное заменят на что-то. Большинство современных библиотек для работы с регулярными выражениями предоставляют оба варианта.
- Если регулярное выражение это , то оно допускает этот текст тогда и только тогда, когда текст закончился.
- Если первый символ текста совпал с первым символом регулярного выражения, то нужно проверить совпадают ли следующий символ регулярного выражения со следующим символом текста, сделав рекурсивный вызов .
- Если все предыдущие попытки найти совпадения провалились, то никакая подстрока из текста не допускается регулярным выражением.
Модификацииправить
Немного изменим функцию для поиск самого левого и самого длинного вхождения :
- Найдем максимальную последовательность подряд идущих символов . Назовем ее .
- Сопоставим часть текста без с остатком регулярного выражения.
- Если части совпали, то текст допускается этим регулярным выражением. Иначе, если пусто, то текст не допускается этим регулярным выражением, иначе убираем один символ из и повторяем шаг .
Псевдокодправить
function matchStar(c: char, regexp: String, text: String): boolean
int i
for (i = 0; text != '\0' and (text == c or c == '.'); i++)
while i 0
if matchHere(regexp, text)
return true
i--
return false
Look arounds
These assertions look ahead or behind the current match without “consuming” any characters (i.e. changing the input position).
-
: positive look-ahead assertion. Matches if matches at the current input.
-
: negative look-ahead assertion. Matches if does not match at the current input.
-
: positive look-behind assertion. Matches if matches text preceding the current position, with the last character of the match being the character just before the current position. Length must be bounded
(i.e. no or ). -
: negative look-behind assertion. Matches if does not match text preceding the current position. Length must be bounded
(i.e. no or ).
These are useful when you want to check that a pattern exists, but you don’t want to include it in the result:
Characters
| Character | Legend | Example | Sample Match |
|---|---|---|---|
| \d | Most engines: one digitfrom 0 to 9 | file_\d\d | file_25 |
| \d | .NET, Python 3: one Unicode digit in any script | file_\d\d | file_9੩ |
| \w | Most engines: «word character»: ASCII letter, digit or underscore | \w-\w\w\w | A-b_1 |
| \w | .Python 3: «word character»: Unicode letter, ideogram, digit, or underscore | \w-\w\w\w | 字-ま_۳ |
| \w | .NET: «word character»: Unicode letter, ideogram, digit, or connector | \w-\w\w\w | 字-ま‿۳ |
| \s | Most engines: «whitespace character»: space, tab, newline, carriage return, vertical tab | a\sb\sc | a bc |
| \s | .NET, Python 3, JavaScript: «whitespace character»: any Unicode separator | a\sb\sc | a bc |
| \D | One character that is not a digit as defined by your engine’s \d | \D\D\D | ABC |
| \W | One character that is not a word character as defined by your engine’s \w | \W\W\W\W\W | *-+=) |
| \S | One character that is not a whitespace character as defined by your engine’s \s | \S\S\S\S | Yoyo |
Диапазоны символов
Символ точки () позволяет нам установить соответствие любому символу. Но иногда нам необходимо быть более конкретными. В этом случае будут полезны диапазоны. Мы указываем диапазон символов, заключая их в квадратные скобки :
В регулярном выражении, приведенном выше, мы ищем символ , за которым следует либо символ , либо , и за которым следует символ .
Количество символов, которые вы можете поместить в квадратные скобки, не ограничено. Вы можете разместить один символ, например, (это было бы немного глупо, но, тем не менее, это не нарушает правила) или вы можете указать несколько символов, например, .
Anchors
Anchors do not match any characters. They match a position. ^ matches at the start of the string, and $ matches at the end of the string. Most regex engines have a “multi-line” mode that makes ^ match after any line break, and $ before any line break. E.g. ^b matches only the first b in bob.
\b matches at a word boundary. A word boundary is a position between a character that can be matched by \w and a character that cannot be matched by \w. \b also matches at the start and/or end of the string if the first and/or last characters in the string are word characters. \B matches at every position where \b cannot match.
Используем флаги в регулярных выражениях
Флаги могут использоваться для указания того, как следует интерпретировать регулярное выражение. Вы можете использовать флаги по одиночке или сочетать их в любом порядке. В JavaScript допустимо использовать следующие пять флагов.
g – находятся все совпадения с указанным выражением в тексте(глобальный поиск);
i – делает поиск нечувствительным к регистру. В этом случае такие слова, как “Apple”, “aPPLe” и “apple” попадут в результаты поиска;
m – флаг включает многострочный поиск;
u – этот флаг позволит вам использовать в вашем регулярном выражении escape-последовательности кода Unicode;
y – Указывает JavaScript вести поиск соответствия в текущей позиции в целевой строке;
Флаги для регулярного выражения в JavaScript можно использовать 2 способами: либо путем добавления их в конец литерала регулярных выражений, либо путем передачи их в конструктор RegExp. Например, /cat/i, соответствующее всех вхождениям слова “cat” независимо от регистра и RegExp(«cat», ‘i’) будут работать одинаково.
Grabbing HTML Tags
<TAG\b^>*>(.*?)</TAG> matches the opening and closing pair of a specific HTML tag. Anything between the tags is captured into the first backreference. The question mark in the regex makes the star lazy, to make sure it stops before the first closing tag rather than before the last, like a greedy star would do. This regex will not properly match tags nested inside themselves, like in <TAG>one<TAG>two</TAG>one</TAG>.
<(A-ZA-Z-9*)\b^>*>(.*?)</\1> will match the opening and closing pair of any HTML tag. Be sure to turn off case sensitivity. The key in this solution is the use of the backreference \1 in the regex. Anything between the tags is captured into the second backreference. This solution will also not match tags nested in themselves.
Основы основ
Для начала нужно понять что в Regex есть специальные символы (например символ начала строки — ), если вы хотите просто найти данный символ, то нужно ввести обратный слеш перед символом для того, чтобы символ не работал как команда.
Для того чтобы найти текст, нужно собственно просто ввести этот текст:
Якори
— символ который обозначает начало строки
— символ который обозначает конец строки
Найдем строки которые начинаются с The Beginning:
Найдем строки, которые заканчиваются на The End:
Найдем строки, которые начинаются и заканчиваются на The Beginning and The End:
Найдем пустые строки:
Квантификаторы
— символ, который указывает на то, что выражение до него должно встретиться 0 или 1 раз
— символ, который указывает на то, что выражение до него должно встретиться один или больше раз
— символ, который указывает на то, что выражение до него должно встретиться 0 или неопределённое количество раз
— скобки с одним аргументом указывают сколько раз выражение до них должно встретиться
— скобки с двумя аргументами указывают на то, от скольки до скольки раз выражение до них должно встретиться
— скобки объединяют какое-то предложение в выражение. Обычно используется в связке с квантификаторами
Давайте попробуем найти текст, в котором будут искаться все слова, содержащие ext или ex:
Давайте попробуем найти текст, в котором слова будут содержать ext или e:
Найти все размеры одежды (XL, XXL, XXXL):
Найти все слова, у которых есть неограниченное число символов c, после которых идёт haracter:
Найти выражение, в котором слово word повторяется от одного до неограниченного количества раз:
Найти выражение, в котором выражение ch повторяется от 3 до неограниченного количества раз:
Выражение «или»
— символ, который обозначает оператор «или»
— выражение в квадратных скобках ставит или между каждым подвыражением
Найти все слова, в которых есть буквы a,e,c,h,p:
Найти все выражения в которых есть ch или pa:
Escape-последовательности
— отмечает один символ, который является цифрой (digit)\
— отмечает символ, который не является цифрой
— отмечает любой символ (число или букву (или подчёркивание)) (word)
— отмечает любой пробельный символ (space character)
— отмечает любой символ (один)
Выражения в квадратных скобках
Кроме того, что квадратные скобки служат оператором «или» между каждым символом, который в них заключён, они также могут служить и для некоторых перечислений:
— один символ от 0 до 9
— любой символ от a до z
— любой символ от A до Z
— любой символ кроме a — z
Найти все выражения, в которых есть английские буквы в нижнем регистре или цифры:
Флаги
Флаги — символы (набор символов), которые отвечают за то, каким именно образом будет происходить поиск.
Форма условия поиска в Regex выглядит вот так:
— флаг, который будет отмечать все выражения, которые соответствуют условиям поиска (по умолчанию поиск возвращает только первое выражение, которое подходит по условию) (global)
— флаг, который заставляет искать выражения вне зависимости от региста (case insensitive)
Теперь вы знаете базовые знания по Regex и можете использовать их в языках программирования, консольных утилитах или в программируемых редакторах (привет, Vim). Если вам интересен данный материал, а также интересны темы веб-разработки и администрирования Unix-подобных систем, то вы можете подписаться на мой телеграм-канал, там много всякого разного и полезного.
Заключение
Резюмируем то, что мы узнали:
— соответствует любому символу;
— совпадает с символом из диапазона, содержащемуся в квадратных скобках;
— соответствует символам, которые не входят в диапазон, содержащийся в квадратных скобках;
— совпадение 0 или более раз с указанным элементом;
— совпадение 1 или более раз с указанным элементом;
— совпадение 0 или 1 раз с указанным элементом;
— точное совпадение раз с указанным элементом;
— точное совпадение от до раз с указанным элементом;
— точное совпадение или более раз с указанным элементом;
— экранирование или отмена специального значения указанного символа.