Построчное чтение файла в python 3
Содержание:
- Openpyxl Charts
- Извлечение текста с помощью PyPDF2
- Примеры построчного чтения файла.
- Функция open() – открытие файла
- Шаг 6 — Проверка кода
- Openpyxl images
- Чтение файлов CSV
- Открытие файла с помощью функции open()
- Чтение и запись файлов
- Запись в файл Python
- Чтение из файла
- File Positions
- Обработка PDF документов
- Общие советы
- Заключение
- Чтение файла
- Шаг 4 — Запись файла
- Openpyxl read multiple cells
Openpyxl Charts
The library supports creation of various charts, including
bar charts, line charts, area charts, bubble charts, scatter charts, and pie charts.
According to the documentation, supports chart creation within
a worksheet only. Charts in existing workbooks will be lost.
create_bar_chart.py
#!/usr/bin/env python
from openpyxl import Workbook
from openpyxl.chart import (
Reference,
Series,
BarChart
)
book = Workbook()
sheet = book.active
rows =
for row in rows:
sheet.append(row)
data = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=6)
categs = Reference(sheet, min_col=1, min_row=1, max_row=6)
chart = BarChart()
chart.add_data(data=data)
chart.set_categories(categs)
chart.legend = None
chart.y_axis.majorGridlines = None
chart.varyColors = True
chart.title = "Olympic Gold medals in London"
sheet.add_chart(chart, "A8")
book.save("bar_chart.xlsx")
In the example, we create a bar chart to show the number of Olympic
gold medals per country in London 2012.
from openpyxl.chart import (
Reference,
Series,
BarChart
)
The module has tools to work with charts.
book = Workbook() sheet = book.active
A new workbook is created.
rows =
for row in rows:
sheet.append(row)
We create some data and add it to the cells of the active sheet.
data = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=6)
With the class, we refer to the rows in the sheet that
represent data. In our case, these are the numbers of olympic gold medals.
categs = Reference(sheet, min_col=1, min_row=1, max_row=6)
We create a category axis. A category axis is an axis with the data
treated as a sequence of non-numerical text labels. In our case, we have
text labels representing names of countries.
chart = BarChart() chart.add_data(data=data) chart.set_categories(categs)
We create a bar chart and set it data and categories.
chart.legend = None chart.y_axis.majorGridlines = None
Using and attributes, we
turn off the legends and major grid lines.
chart.varyColors = True
Setting to , each bar has a different
colour.
chart.title = "Olympic Gold medals in London"
A title is set for the chart.
sheet.add_chart(chart, "A8")
The created chart is added to the sheet with the method.
 Figure: Bar chart
Figure: Bar chart
In this tutorial, we have worked with the openpyxl library. We have read data
from an Excel file, written data to an Excel file.
Visit Python tutorial or
list .
Извлечение текста с помощью PyPDF2
Начнём с . Ниже приведен скрипт, который позволяет извлечь из PDF‑файла текст и вывести него в консоль.
Сначала импортируем , помня о том, что пакет уже установлен. Задаём имя файла из папки (можете загрузить туда свой файл и поменять в скрипте на имя загруженного файла), открывает документ и получаем информацию о документе, используя метод и общее количество страниц . Далее в цикле читаем каждую страницу, получаем содержимое и печатаем в .
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов при извлекает первую страницу документа
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
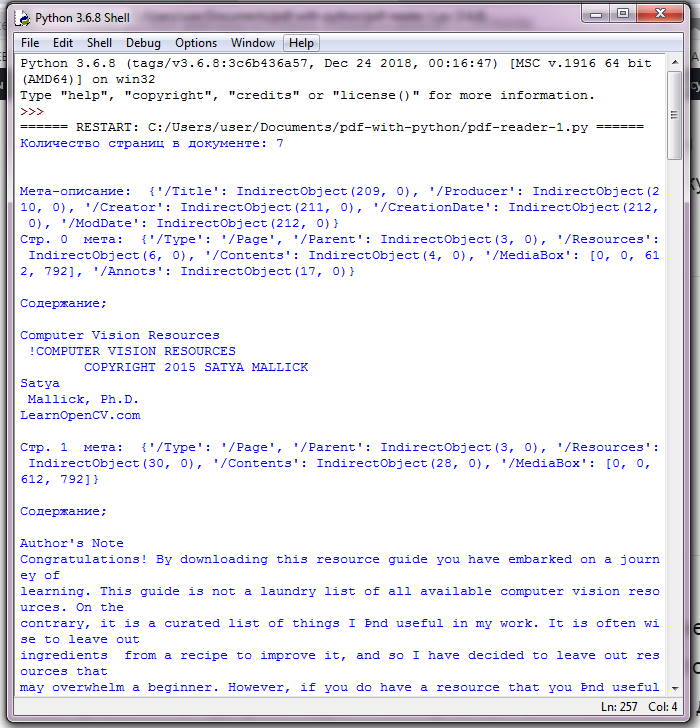 Извлечение текста с помощью PyPDF2
Извлечение текста с помощью PyPDF2
Как видите, извлеченный текст печатается сплошным потоком. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены на странице. В основном, это зависит от внутренней структуры документа PDF и от того, как поток инструкций, создан во время его записи, поэтому их использование может привести к неожиданностям, надо дополнительно «парсить», не очень удобно.
Примеры построчного чтения файла.
- ;
- ;
- .
Общий случай использования метода файла .
# подготовим файл 'foo.txt'
>>> text = 'This is 1st line\nThis is 2nd line\nThis is 3rd line\n'
>>> fp = open('foo.txt', 'w+')
# запишем текст в файл 'foo.txt'
>>> fp.write(text)
# 51
# указатель в начало файла
>>> fp.seek()
# 0
# начинаем читать построчно
>>> fp.readline()
# 'This is 1st line\n'
>>> fp.readline()
# 'This is 2nd line\n'
>>> fp.readline()
# 'This is 3rd line\n'
>>> fp.readline()
# ''
>>> fp.close()
Чтение файла при помощи цикла .
Так как операция открытия файла возвращает поток, представляющий из себя генератор строк из файла, то можно итерироваться по нему при помощи функции .
>>> fp = open('foo.txt', 'r')
>>> next(fp)
# 'This is 1st line\n'
>>> next(fp)
# 'This is 2nd line\n'
>>> next(fp)
# 'This is 3rd line\n'
>>> next(fp)
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# StopIteration
>>> fp.close()
Так как цикл делает то же самое, а именно при прохождении по последовательности вызывает , следовательно, более просто, читать файл построчно, без ущерба для оперативной памяти можно следующим образом.
Внимание! Функцию предпочтительнее использовать с оператором контекстного менеджера. При использовании оператора файл закрывать не нужно:
>>> with open('foo.txt', 'r') as fp
... for n, line in enumerate(fp, 1):
... # Обработка строки 'line'
... line = line.rstrip('\n')
... print(f"Вывод строки: {n}) - {line}")
...
# Вывод строки: 1) - This is 1st line
# Вывод строки: 2) - This is 2nd line
# Вывод строки: 3) - This is 3rd line
Чтение строк файла кусками при помощи цикла .
Возможно возникнет вопрос, зачем тогда вообще нужен метод файла , если все так просто. Ответы просты. А если необходимо прочитать только одну строку? А если строка файла (до разделителя строки ) очень длинная и не умещается в оперативной памяти, то тогда приходит на помощь метод файла , т.к. он умеет разбивать строку файла на куски.
>>> fp = open('foo.txt', 'r')
# будем читать строку по 10 байт
>>> line = fp.readline(10)
>>> while line
... line = line.rstrip('\n')
... print(line)
... line = fp.readline(10)
...
# This is 1s
# t line
# This is 2n
# d line
# This is 3r
# d line
>>> fp.close()
Функция open() – открытие файла
Открытие файла выполняется с помощью встроенной в Python функции . Обычно ей передают один или два аргумента. Первый – имя файла или имя с адресом, если файл находится не в том каталоге, где находится скрипт. Второй аргумент – режим, в котором открывается файл.
Обычно используются режимы чтения () и записи (). Если файл открыт в режиме чтения, то запись в него невозможна. Можно только считывать данные из него. Если файл открыт в режиме записи, то в него можно только записывать данные, считывать нельзя.
Если файл открывается в режиме , то все данные, которые в нем были до этого, стираются. Файл становится пустым. Если не надо удалять существующие в файле данные, тогда следует использовать вместо режима записи, режим дозаписи ().
Если файл отсутствует, то открытие его в режиме создаст новый файл. Бывают ситуации, когда надо гарантировано создать новый файл, избежав случайной перезаписи данных существующего. В этом случае вместо режима используется режим . В нем всегда создается новый файл для записи. Если указано имя существующего файла, то будет выброшено исключение. Потери данных в уже имеющемся файле не произойдет.
Если при вызове второй аргумент не указан, то файл открывается в режиме чтения как текстовый файл. Чтобы открыть файл как байтовый, дополнительно к букве режима чтения/записи добавляется символ . Буква обозначает текстовый файл. Поскольку это тип файла по умолчанию, то обычно ее не указывают.
Нельзя указывать только тип файла, то есть есть ошибка, даже если файл открывается на чтение. Правильно – . Только текстовые файлы мы можем открыть командой , потому что и и подразумеваются по-умолчанию.
Функция возвращает объект файлового типа. Его надо либо сразу связать с переменной, чтобы не потерять, либо сразу прочитать.
Шаг 6 — Проверка кода
Конечный результат должен выглядеть примерно так:
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read() new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w') title = 'Days of the Weekn' new_days.write(title) print(title) new_days.write(days) print(days) days_file.close() new_days.close()
После сохранения кода откройте терминал и запустите свой Python- скрипт, например:python files.py
Результат должен выглядеть так:
Вывод Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Теперь проверим код полностью, открыв файл new_days.txt. Если все пройдет хорошо, когда мы откроем этот файл, его содержимое должно выглядеть следующим образом:
new_days.txt
Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Openpyxl images
In the following example, we show how to insert an image into a sheet.
write_image.py
#!/usr/bin/env python
from openpyxl import Workbook
from openpyxl.drawing.image import Image
book = Workbook()
sheet = book.active
img = Image("icesid.png")
sheet = 'This is Sid'
sheet.add_image(img, 'B2')
book.save("sheet_image.xlsx")
In the example, we write an image into a sheet.
from openpyxl.drawing.image import Image
We work with the class from the
module.
img = Image("icesid.png")
A new class is created. The
image is located in the current working directory.
sheet.add_image(img, 'B2')
We add a new image with the method.
Чтение файлов CSV
Существует два способа чтения файлов CSV. Вы можете использовать функцию чтения модуля csv, или использовать класс DictReader. Мы рассмотрим оба метода. Но сначала, нам нужно получить файлы CSV, чтобы было над чем работать. В интернете есть много сайтов, предлагающих познавательную информацию в формате CSV. Мы используем сайт всемирной организации здравоохранения, чтобы скачать кое-какую информацию о туберкулёзе. Вы можете получить её здесь: http://www.who.int/tb/country/data/download/en/Как только вы скачаете файл, мы будем готовы начать. Готовы? Давайте взглянем на следующий код:
Python
import csv
def csv_reader(file_obj):
«»»
Read a csv file
«»»
reader = csv.reader(file_obj)
for row in reader:
print(» «.join(row))
if __name__ == «__main__»:
csv_path = «TB_data_dictionary_2014-02-26.csv»
with open(csv_path, «r») as f_obj:
csv_reader(f_obj)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
importcsv defcsv_reader(file_obj) «»» Read a csv file reader=csv.reader(file_obj) forrow inreader print(» «.join(row)) if__name__==»__main__» csv_path=»TB_data_dictionary_2014-02-26.csv» withopen(csv_path,»r»)asf_obj csv_reader(f_obj) |
Вот здесь мы остановимся. В первую очередь, нам нужно импортировать модуль csv. После этого, нам нужно создать очень простую функцию, под названием csv_reader, которая получает доступ к объекту файла. Внутри функции, мы передаем файл функции csv.reader, которая возвращает объект-считыватель. Объект-считыватель позволяет выполнить итерацию также, как это делает обычный объект file.
Это позволяет выполнять итерацию над каждым рядом в объекте-считывателе и отобразить строку данных, но без запятых. Это работает по той причине, что каждый ряд является списком, и мы можем объединить все элементы в списке вместе, создав одну большую строку. А теперь мы создадим наш собственный файл CSV и загрузим его в класс DictReader. Вот очень простой пример:
Python
first_name,last_name,address,city,state,zip_code
Tyrese,Hirthe,1404 Turner Ville,Strackeport,NY,19106-8813
Jules,Dicki,2410 Estella Cape Suite 061,Lake Nickolasville,ME,00621-7435
Dedric,Medhurst,6912 Dayna Shoal,Stiedemannberg,SC,43259-2273
|
1 2 3 4 |
first_name,last_name,address,city,state,zip_code Tyrese,Hirthe,1404 Turner Ville,Strackeport,NY,19106-8813 Jules,Dicki,2410 Estella Cape Suite 061,Lake Nickolasville,ME,00621-7435 Dedric,Medhurst,6912 Dayna Shoal,Stiedemannberg,SC,43259-2273 |
Давайте сохраним это в файле, под названием data.csv . Теперь мы готовы проанализировать файл при помощи класса DictReader. Давайте попробуем:
Python
import csv
def csv_dict_reader(file_obj):
«»»
Read a CSV file using csv.DictReader
«»»
reader = csv.DictReader(file_obj, delimiter=’,’)
for line in reader:
print(line),
print(line)
if __name__ == «__main__»:
with open(«data.csv») as f_obj:
csv_dict_reader(f_obj)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
importcsv defcsv_dict_reader(file_obj) «»» Read a CSV file using csv.DictReader reader=csv.DictReader(file_obj,delimiter=’,’) forline inreader print(line»first_name»), print(line»last_name») if__name__==»__main__» withopen(«data.csv»)asf_obj csv_dict_reader(f_obj) |
В данном примере мы открыли файл и привязали объект файла к нашей функции таким же образом, каким мы делали это раньше. Функция привязывает наш объект к нашему классу DictReader. Мы указываем классу DictReader, что разделителем является запятая. Не то, что бы это было необходимо в нашем коде, так как он работает и без этого аргумента. Тем не менее, это хорошая идея, так как это позволяет пролить свет на то, что именно происходит внутри кода. Далее, мы применяем цикл над объектом-считывателем, и обнаруживаем, что каждая строка в нем – это словарь. Это упрощает печать отдельных фрагментов линии. Теперь мы готовы научиться писать файл csv на диск.
Открытие файла с помощью функции open()
Первый шаг к работе с файлами в Python – научиться открывать файл. Вы можете открывать файлы с помощью метода open().
Функция open() в Python принимает два аргумента. Первый – это имя файла с полным путем, а второй – режим открытия файла.
Ниже перечислены некоторые из распространенных режимов чтения файлов:
- ‘r’ – этот режим указывает, что файл будет открыт только для чтения;
- ‘w’ – этот режим указывает, что файл будет открыт только для записи. Если файл, содержащий это имя, не существует, он создаст новый;
- ‘a’ – этот режим указывает, что вывод этой программы будет добавлен к предыдущему выводу этого файла;
- ‘r +’ – этот режим указывает, что файл будет открыт как для чтения, так и для записи.
Кроме того, для операционной системы Windows вы можете добавить «b» для доступа к файлу в двоичном формате. Это связано с тем, что Windows различает двоичный текстовый файл и обычный текстовый файл.
Предположим, мы помещаем текстовый файл с именем file.txt в тот же каталог, где находится наш код. Теперь мы хотим открыть этот файл.
Однако функция open (filename, mode) возвращает файловый объект. С этим файловым объектом вы можете продолжить свою дальнейшую работу.
#directory: /home/imtiaz/code.py
text_file = open('file.txt','r')
#Another method using full location
text_file2 = open('/home/imtiaz/file.txt','r')
print('First Method')
print(text_file)
print('Second Method')
print(text_file2)
Результатом следующего кода будет:
================== RESTART: /home/imtiaz/code.py ================== First Method Second Method >>>
Чтение и запись файлов
Python предлагает различные методы для чтения и записи файлов, где каждая функция ведет себя по-разному. Следует отметить один важный момент – режим работы с файлами. Чтобы прочитать файл, вам нужно открыть файл в режиме чтения или записи. В то время, как для записи в файл на Python вам нужно, чтобы файл был открыт в режиме записи.
Вот некоторые функции Python, которые позволяют читать и записывать файлы:
- read() – эта функция читает весь файл и возвращает строку;
- readline() – эта функция считывает строки из этого файла и возвращает их в виде строки. Он выбирает строку n, если она вызывается n-й раз.
- readlines() – эта функция возвращает список, в котором каждый элемент представляет собой одну строку этого файла.
- readlines() – эта функция возвращает список, в котором каждый элемент представляет собой одну строку этого файла.
- write() – эта функция записывает фиксированную последовательность символов в файл.
- Writelines() – эта функция записывает список строк.
- append() – эта функция добавляет строку в файл вместо перезаписи файла.
Возьмем пример файла «abc.txt» и прочитаем отдельные строки из файла с помощью цикла for:
#open the file
text_file = open('/Users/pankaj/abc.txt','r')
#get the list of line
line_list = text_file.readlines();
#for each line from the list, print the line
for line in line_list:
print(line)
text_file.close() #don't forget to close the file
Вывод:
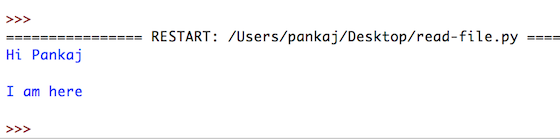
Теперь, когда мы знаем, как читать файл в Python, давайте продвинемся вперед и выполним здесь операцию записи с помощью функции Writelines().
#open the file
text_file = open('/Users/pankaj/file.txt','w')
#initialize an empty list
word_list= []
#iterate 4 times
for i in range (1, 5):
print("Please enter data: ")
line = input() #take input
word_list.append(line) #append to the list
text_file.writelines(word_list) #write 4 words to the file
text_file.close() #don’t forget to close the file
Вывод
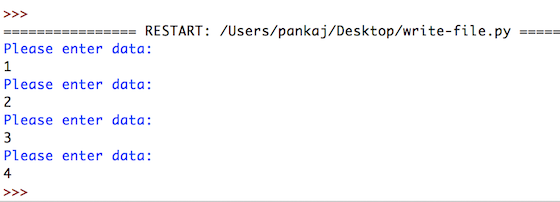
Запись в файл Python
Чтобы записать данные в файл в Python, нужно открыть его в режиме ‘w’, ‘a’ или ‘x’. Но будьте осторожны с режимом ‘w’. Он перезаписывает файл, если то уже существует. Все данные в этом случае стираются.
Запись строки или последовательности байтов (для бинарных файлов) осуществляется методом write(). Он возвращает количество символов, записанных в файл.
with open("test.txt",'w',encoding = 'utf-8') as f:
f.write("my first filen")
f.write("This filenn")
f.write("contains three linesn")
Эта программа создаст новый файл ‘test.txt’. Если он существует, данные файла будут перезаписаны. При этом нужно добавлять символы новой строки самостоятельно, чтобы разделять строки.
Чтение из файла
При открытии файла в режимах, допускающих чтение, можно использовать несколько подходов.
Для начала можно прочитать файл целиком и все данные, находящиеся в нем, записать в одну строку.
Используя эту функцию с целочисленным аргументом, можно прочитать определенное количество символов.
При этом будут получены только первые 16 символов текста
Важно понимать, что при применении этой функции несколько раз подряд будет считываться часть за частью этого текста — виртуальный курсор будет сдвигаться на считанную часть текста. Его можно сдвинуть на определенную позицию, при необходимости воспользовавшись методом
Другой способ заключается в считывании файла построчно. Метод считывает строку и, также как и с методом , сдвигает курсор — только теперь уже на целую строку. Применение этого метода несколько раз будет приводить к считыванию нескольких строк. Схожий с этим способом, другой метод позволяет прочитать файл целиком, но по строкам, записав их в список. Этот список можно использовать, например, в качестве итерируемого объекта в цикле.
Однако и здесь существует более pythonic way. Он заключается в том, что сам объект имеет итератор, возвращающий строку за строкой. Благодаря этому нет необходимости считывать файл целиком, сохраняя его в список, а можно динамически по строкам считывать файл. И делать это лаконично.
File Positions
The tell() method tells you the current position within the file; in other words, the next read or write will occur at that many bytes from the beginning of the file.
The seek(offset) method changes the current file position. The offset argument indicates the number of bytes to be moved. The from argument specifies the reference position from where the bytes are to be moved.
If from is set to 0, it means use the beginning of the file as the reference position and 1 means use the current position as the reference position and if it is set to 2 then the end of the file would be taken as the reference position.
Example
Let us take a file foo.txt, which we created above.
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10)
print "Read String is : ", str
# Check current position
position = fo.tell()
print "Current file position : ", position
# Reposition pointer at the beginning once again
position = fo.seek(0, 0);
str = fo.read(10)
print "Again read String is : ", str
# Close opend file
fo.close()
This produces the following result −
Read String is : Python is Current file position : 10 Again read String is : Python is
Обработка PDF документов
В Linux для работы с файлами PDF всё проще, есть мощные инструменты командной строки, такие как и . Но, поскольку, PDF — межплатформенный открытый формат электронных документов, хотелось бы с таким же удобством работать и в Windows, и в macOS. При этого нужна фантазия и усилия разработчика. Вот и совсем недавно встретилась задачка переноса информации из PDF‑файла в базу данных. Естественно, задача автоматизации здесь имеет свою уникальную специфику и без разработки здесь ну совсем никак.
Это руководство — начало небольшой серии, где будут рассмотрены полезные для разработчика библиотеки, позволяющие создавать собственные скрипты Python для решения рутинных задач автоматизации
В первой части внимание сконцентрировано на манипулировании существующими PDF‑файлами. Вы узнаете, как читать и извлекать содержимое (текст и изображения) и разбивать документы на отдельные страницы
Вторая часть будет посвящена наложению водяных знаков в документ. Третья часть посвящена исключительно написанию/созданию PDF‑файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Общие советы
Собеседование может быть тяжелым и напряженным, но вы не должны позволять этому охватить контроль над вами. Вы можете прочитать все вопросы и ответы, которые вы найдете в Интернете, и все же провалить это интервью. Почему же?
Прежде всего, ваш потенциальный работодатель спросит вас не только о том, как хорошо вы знаете Python основы. Он может спросить вас о вашем предыдущем опыте, умеете ли вы писать программы на Python, проверить, какой вы человек, узнать о ваших увлечениях — все эти факторы очень важны для того, чтобы устроиться на эту работу.
Хороший способ оставить хорошее впечатление — не вести себя так, как будто ваша жизнь зависит от результатов собеседования — если вы сидите там и пытаетесь ответить на технические вопросы по собеседованию на Python, в то же время сильно потея и дрожа, как лист на ветке, вы можете напугать человека, с которым вы разговариваете.
Кроме того, не будьте дерзкими — конечно, у вас может быть 20-летний опыт работы с Python, но вы можете не пройти интервью по Python если ведете себя как высокомерный человек?
Хорошо выспитесь ночью и не беспокойтесь об этом — покажите вашему потенциальному работодателю человека, которым вы действительно являетесь, и вы, вероятно, добьетесь успеха. Помните — эти люди — профессионалы, которые ежедневно имеют дело с сотрудниками — если вы попытаетесь лгать или обманывать, они, скорее всего, поймают вас в считанные секунды.
Заключение
Людей, которые знаю, как выглядит работа с файлами Python разбирают с руками и ногами. Когда вы отвечаете на такое количество вопросов по Python, вы становитесь увереннее. Просто помните — уверенность не равна дерзкости.
Итак, мы подошли к концу этой статьи для вопросов по интервью о Python. Я надеюсь, что вы нашли эту информацию интересной и будете использовать ее, чтобы получить эту работу!
Чтение файла
С помощью файлового метода можно прочитать файл целиком или только определенное количество байт. Пусть у нас имеется файл data.txt с таким содержимым:
one - 1 - I two - 2 - II three - 3 - III four - 4 - IV five - 5 - V
Откроем его и почитаем:
>>> f1 = open('data.txt')
>>> f1.read(10)
'one - 1 - '
>>> f1.read()
'I\ntwo - 2 - II\nthree - 3 - III\n
four - 4 - IV\nfive - 5 - V\n'
>>> f1.read()
''
>>> type(f1.read())
<class 'str'>
Сначала считываются первые десять байтов, которые равны десяти символам. Это не бинарный файл, но мы все равно можем читать по байтам. Последующий вызов считывает весь оставшийся текст. После этого объект файлового типа f1 становится пустым.
Заметим, что метод возвращает строку, и что конец строки считывается как .
Для того, чтобы читать файл построчно существует метод :
>>> f1 = open('data.txt')
>>> f1.readline()
'one - 1 - I\n'
>>> f1.readline()
'two - 2 - II\n'
>>> f1.readline()
'three - 3 — III\n'
Метод считывает сразу все строки и создает список:
>>> f1 = open('data.txt')
>>> f1.readlines()
Объект файлового типа относится к итераторам. Из таких объектов происходит последовательное извлечение элементов. Поэтому считывать данные из них можно сразу в цикле без использования методов чтения:
>>> for i in open('data.txt'):
... print(i)
...
one - 1 - I
two - 2 - II
three - 3 - III
four - 4 - IV
five - 5 - V
>>>
Здесь при выводе наблюдаются лишние пустые строки. Функция преобразует в переход на новую строку. К этому добавляет свой переход на новую строку. Создадим список строк файла без :
>>> nums = []
>>> for i in open('data.txt'):
... nums.append(i)
...
>>> nums
Переменной i присваивается очередная строка файла. Мы берем ее срез от начала до последнего символа, не включая его. Следует иметь в виду, что это один символ, а не два.
Шаг 4 — Запись файла
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
files.py
title = 'Days of the Weekn'
Также нужно сохранить дни недели в строковой переменной days. Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days.
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read()
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/. Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt. Мы записываем его в переменную new_path. Затем открываем новый файл в режиме записи, используя функцию open() с режимом w.
files.py
new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w')
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя <file>.write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
iles.py
new_days.write(title) print(title) new_days.write(days) print(days)
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
Openpyxl read multiple cells
We have the following data sheet:
Figure: Items
We read the data using a range operator.
read_cells2.py
#!/usr/bin/env python
import openpyxl
book = openpyxl.load_workbook('items.xlsx')
sheet = book.active
cells = sheet
for c1, c2 in cells:
print("{0:8} {1:8}".format(c1.value, c2.value))
In the example, we read data from two columns using a range operation.
cells = sheet
In this line, we read data from cells A1 — B6.
for c1, c2 in cells:
print("{0:8} {1:8}".format(c1.value, c2.value))
The function is used for neat output of data
on the console.
$ ./read_cells2.py Items Quantity coins 23 chairs 3 pencils 5 bottles 8 books 30
This is the output of the program.