Http
Содержание:
- Переход на https — зачем мне это?
- 13 популярных ошибок при переходе сайта на https
- Погружение в код
- HTTP-сессия
- Преимущества и недостатки протокола
- Обслуживание соединения со стороны сервера
- Основы TCP/IP
- Библиотеки для работы с HTTP — jQuery AJAX
- HTTP-заголовки
- Резюме¶
- Конвейерная обработка HTTP (pipelining)
- Hyper Text Transfer Protocol
- 1.2. Пишем наш первый HTTP запрос
- Загрузка нескольких ресурсов
- История
- Основы HTTP
- Как подключить HTTP/2
- Как работает HTTPS протокол сайта
- В чем различия между http и https?
- HTTP/1.1 – 1999
- Заключение о протоколе HTTP
Переход на https — зачем мне это?
Я бы выделил 4 причины:
- Забота о безопасности данных: сейчас по этой теме сходят все с ума (раньше все клали с пробором, но теперь…). Для сайтов работающих с деньгами и онлайн оплатой — это острая необходимость, т.к. шифруются все данные. Для простых информационных ресурсов — вас все равно заставят перейти на https, т.ч. выбора особо нет.
-
Это фактор ранжирования: и Яндекс и Google открыто об этом говорили. Если раньше только Гугл заставлял переводить сайты на https, то сейчас за это взялось зеркало Рунета и с 24 января 2019 года в вебмастере уже многие увидели предупреждение:
Т.е. это благотворно скажется на ваших позициях и трафике с поисковых систем (на самом деле нет, чаще вообще никак не скажется )
-
Больше доверия со стороны пользователей. Когда посетитель видит в браузере метку:
Это может его отпугнуть/насторожить, особенно если это человек не сильно понимающий сути происходящего.
- Ради HTTP/2 и большей скорости, которая так же является фактором ранжирования. В среднем прирост по скорости достигает 20-30% практически за 20-30 минут работы.
Ну а теперь перейдем к пошаговому плану по переходу с http на защищенный протокол https.
13 популярных ошибок при переходе сайта на https
Пишу самые популярные моменты, которые знаю из своего опыта или опыта коллег:
- Сделать 302 редирект вместо 301 для склейки версий http с https;
- Сделать редирект всех внутренних страниц на главную;
- Допустить цикличные редиректы;
- Забыл, что твой сайт без www, но склеить с https://www.site.ru;
- Забыл прописать новый путь для sitemap.xml;
- Пропустил этап с заменой абсолютных ссылок;
- Не изменил урлы в скриптах и медиа-контенте;
- В карте сайта указаны урлы на версию с http;
- Описался при наборе домена при получении сертификата;
- Может сломаться 1С, если забыли обновить данные;
- Сайт интегрирован с различными API и вы забыли изменить адреса;
- Косяки с rel=”canonical” на старые страницы;
- Не очистил кэш и начал сам себе выдумывать проблемы.
А с какими косяками вы сталкивались?
Погружение в код
Если вы хотите следовать этому примеру, создайте новый HTML-документ и добавьте в него следующую разметку:
Внутри тега script добавьте следующий код, который составляет наш веб-запрос:
После того как вы добавили эти строки, сохраните изменения и протестируйте свою страницу в браузере. Вы ничего не увидите на экране, но если вы откроете консоль с помощью инструментов разработчика браузера, то увидите, как будет отображаться ваш IP-адрес:
Это уже что-то! Теперь, когда наш IP-адрес отображается на нашей консоли, давайте на минутку вернемся к коду и посмотрим, что именно он делает. С помощью нашей первой строки кода мы вызываем fetch и предоставляем URL-адрес, на который хотим сделать запрос:
URL-адрес, по которому мы отправляем наш запрос, таков ipinfo.io/json. Как только эта строка будет запущена, служба будет запущена ipinfo.io пришлет нам кое-какие данные. Это зависит от нас, чтобы обработать эти данные, и следующие два блока then отвечают за эту обработку:
Одна действительно важная деталь, которую следует упомянуть, заключается в том, что ответ, возвращаемый fetch, является обещанием. Эти блоки являются частью того, как обещания работают асинхронно, чтобы позволить нам обрабатывать результаты. Охват обещаний выходит за рамки этой статьи, но документация MDN отлично объясняет, что это такое.
На данный момент нужно знать, что у нас есть цепочка блоков then, где каждый блок вызывается автоматически после завершения предыдущего. Поскольку все это асинхронно, все это делается в то время, как остальная часть нашего приложения делает свое дело.
Нам не нужно делать ничего лишнего, чтобы убедиться, что наш код, связанный с запросом, не блокирует и не замораживает наше приложение в ожидании медленного результата работы сети или обработки большого объема данных.
Возвращаясь к коду, в нашем первом блоке then мы указываем, что нам нужны необработанные данные JSON, которые возвращает наш вызов fetch:
В следующем блоке then, который вызывается после завершения предыдущего, мы обрабатываем возвращенные данные дальше, сужая свойство, которое даст нам IP-адрес, и печатая его на консоли:
Как мы узнаем, что IP-адрес будет сохранен свойством ip из наших возвращенных данных Google? Самый простой способ-это обратиться к ipinfo.io документация разработчика! Каждый веб — сервис будет иметь свой собственный формат для возврата данных по запросу. Нам нужно потратить несколько минут и выяснить, как будет выглядеть ответ, какие параметры нам, возможно, потребуется передать в качестве части запроса, чтобы настроить ответ, и как нам нужно написать наш код, чтобы получить нужные данные.
В качестве альтернативы чтению документации разработчика вы всегда можете проверить ответ, возвращенный запросом, с помощью инструментов разработчика. Используйте тот подход, который вам удобен.
Мы еще не закончили с нашим кодом. Иногда обещание приводит к ошибке или неудачному ответу. Когда это произойдет, наше обещание перестанет идти вниз по цепочке блоков then и вместо этого будет искать блок catch. Then будет выполнен код в этом блоке catch. Наш блок catch выглядит следующим образом:
Мы не делаем ничего новаторского с нашей обработкой ошибок. Мы просто выводим сообщение об ошибке на консоль.
HTTP-сессия
HTTP-сеанс — это последовательность сетевых транзакций запрос – ответ. Клиент HTTP инициирует запрос, устанавливая соединение протокола управления передачей (TCP) с определенным портом на сервере (обычно порт 80, иногда порт 8080; см. Список номеров портов TCP и UDP ). HTTP-сервер, прослушивающий этот порт, ожидает сообщения запроса от клиента. После получения запроса сервер отправляет обратно строку состояния, например « HTTP / 1.1 200 OK », и собственное сообщение. Тело этого сообщения обычно является запрошенным ресурсом, хотя также может быть возвращено сообщение об ошибке или другая информация.
Постоянные соединения
В HTTP / 0.9 и 1.0 соединение закрывается после одной пары запрос / ответ. В HTTP / 1.1 был введен механизм keep-alive, при котором соединение можно было повторно использовать для более чем одного запроса. Такие постоянные соединения заметно сокращают задержку запроса, поскольку клиенту не нужно повторно согласовывать соединение TCP 3-Way-Handshake после отправки первого запроса. Еще один положительный побочный эффект заключается в том, что в целом соединение со временем становится быстрее из-за механизма TCP.
Версия 1.1 протокола также улучшила оптимизацию полосы пропускания для HTTP / 1.0. Например, в HTTP / 1.1 введено кодирование передачи по частям, позволяющее передавать контент в постоянных соединениях в потоковом режиме, а не в буфере. Конвейерная обработка HTTP дополнительно сокращает время задержки, позволяя клиентам отправлять несколько запросов, прежде чем ждать каждого ответа. Еще одним дополнением к протоколу было побайтовое обслуживание , когда сервер передает только часть ресурса, явно запрошенную клиентом.
Состояние сеанса HTTP
HTTP — это протокол без сохранения состояния . Протокол без сохранения состояния не требует, чтобы HTTP-сервер сохранял информацию или статус о каждом пользователе в течение нескольких запросов. Однако некоторые веб-приложения реализуют состояния или сеансы на стороне сервера, используя, например, файлы cookie HTTP или скрытые переменные в веб-формах .
Преимущества и недостатки протокола
Многолетняя практика выявила у протокола HTTP немало достоинств и недостатков. Несколько слов о тех и о других.
Достоинства:
- Простота. Протокол HTTP позволяет легко создавать необходимые клиентские приложения.
- Расширяемость. Исходные возможности протокола можно расширить, внедрив свои собственные заголовки, с помощью которых можно добиться необходимой функциональности, которая может потребоваться при решении специфических задач. Совместимость с другими серверами и клиентами от этого никак не пострадает: они будут игнорировать неизвестные им заголовки.
- Распространённость. Протокол поддерживается в качестве клиента многими программами и есть возможность выбирать среди хостинговых компаний с серверами HTTP. По этой причине протокол широко используют для решения различных задач. Кроме этого, существует документация на многих языках, что существенно облегчает работу с протоколом.
Недостатки:
- Отсутствие «навигации». У протокола HTTP отсутствуют в явном виде средства навигации среди ресурсов сервера. Например, клиент не может явным образом запросить список доступных файлов, как в протоколе FTP. Полностью эта проблема решена в расширяющем HTTP протоколе WebDAV с помощью добавленного метода PROPFIND. Данный метод позволяет не только получить дерево каталогов, но и список параметров каждого ресурса.
- Отсутствие поддержки распределённости. Изначально протокол HTTP разрабатывался для решения типичных бытовых задач, где само по себе время обработки запроса должно занимать незначительное время или вовсе не приниматься в расчёт. Однако со временем стало очевидно, что при промышленном использовании с применением распределённых вычислений при высоких нагрузках на сервер протокол HTTP оказывается непригоден. В связи с этим с 1998 году был предложен альтернативный протокол HTTP-NG (англ. HTTP Next Generation), но этот протокол до сих пор находится на стадии разработки.
Обслуживание соединения со стороны сервера
В основном сервер прослушивает входящие сообщения и обрабатывает их по мере поступления запросов. Операции сервера включают в себя:
- создание сокета для начала прослушивания 80-го (или другого) порта,
- получение запроса и анализ сообщения,
- обработку ответа,
- установку заголовка ответа,
- отправку ответа клиенту,
прерывание соединение, если возникло сообщение: Connection: close.
Естественно, это далеко не полный перечень операций. Для создания наиболее индивидуальных ответов веб-сайты и программы должны “понимать”, кто посылает запросы. За это отвечают процессы идентификации и аутентификации.
Основы TCP/IP
Стек протоколов TCP/IP (Transmission Control Protocol/Internet Protocol, протокол управления передачей/протокол интернета) — сетевая модель, описывающая процесс передачи цифровых данных. Она названа по двум главным протоколам, по этой модели построена глобальная сеть — интернет. Сейчас это кажется невероятным, но в 1970-х информация не могла быть передана из одной сети в другую, с целью обеспечить такую возможность был разработан стек интернет-протоколов также известный как TCP/IP.
Разработкой этих протоколов занималось Министерство обороны США, поэтому иногда модель TCP/IP называют DoD (Department of Defence) модель. Если вы знакомы с моделью OSI, то вам будет проще понять построение модели TCP/IP, потому что обе модели имеют деление на уровни, внутри которых действуют определенные протоколы и выполняются собственные функции. Мы разделили статью на смысловые части, чтобы было проще понять, как устроена модель TCP/IP:
Библиотеки для работы с HTTP — jQuery AJAX
Поскольку jQuery очень популярен, в нём также есть инструментарий для обработки HTTP ответов при AJAX запросах. Информацию о jQuery.ajax(settings) можете найти на официальном сайте.
Передав объект настроек (settings), а также воспользовавшись функцией обратного вызова beforeSend, мы можем задать заголовки запроса, с помощью метода setRequestHeader().
$.ajax({
url: 'http://www.articles.com/latest',
type: 'GET',
beforeSend: function (jqXHR) {
jqXHR.setRequestHeader('Accepts-Language', 'en-US,en');
}
});
Прочитать объект jqXHR можно с помощью метода jqXHR.getResponseHeader().
Если хотите обработать статус запроса, то это можно сделать так:
$.ajax({
statusCode: {
404: function() {
alert("page not found");
}
}
});
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
Резюме¶
Протокол HTTP это:
- однонаправленный (запрос/ответ)
- текстовый протокол
- не хранит состояния
- работает на сетевом уровне только через TCP
- может передавать любые данные
- используется не только в браузерах
- обслуживает львиную долю Интернет трафика
Достоинства
-
Простота. Протокол HTTP позволяет легко создавать необходимые клиентские
приложения. -
Расширяемость. Исходные возможности протокола можно расширить,
внедрив свои собственные заголовки, с помощью которых можно добиться
необходимой функциональности, которая может потребоваться при решении
специфических задач. Совместимость с другими серверами и клиентами от
этого никак не пострадает: они будут игнорировать неизвестные им
заголовки. -
Распространённость. Протокол поддерживается в качестве клиента
многими программами и есть возможность выбирать среди хостинговых
компаний с серверами HTTP. По этой причине протокол широко используют для
решения различных задач. Кроме этого, существует документация на многих
языках, что существенно облегчает работу с протоколом.
Недостатки
-
Избыточность передаваемой информации, и как следствие, большой размер
сообщений по сравнению с передачей двоичных данных. Это нивелируется
внедрением кэширования на стороне клиента, компрессии передаваемых данных
от сервера. Также улучшает ситуацию использование прокси-серверов,
позволяющих передавать информацию клиенту с наиболее близкого сервера,
diff-кодирование, благодаря которому клиенту передается не весь объем
данных, а только измененная их часть. -
Отсутствие навигации. У протокола отсутствую средства навигации среди
ресурсов сервера. Клиент не может, как в FTP запросить список доступных
файлов. Протокол предполагает, что пользователю уже известен URI
интересующего его ресурса.Эта особенность достаточно прозрачна для пользователя, но неудобна для
приложения, которому это иногда требуется. Разработчиками это решается
вводом дополнительных компонентов. Со стороны клиента это может быть
например веб-паук, проходящий по всем гиперссылкам документа, и
собирающий данную информации. Со стороны сервера это например, карта
сайта—специальная страница с перечислением доступных клиенту ресурсов.Карта сайта может использоваться как пользователем, так и
роботами-пауками поисковых систем, уменьшая для них глубину
просмотра—минимально необходимое количество переходов с главной страницы.
Аналогичную функцию выполняют и файлы sitemap, но только для
приложений. Данная проблема полностью решена в протоколе более высокго
уровня WebDAV с помощью добавленного метода PROPFIND, который
позволяет получить не только дерево каталогов, но и список параметров
каждого ресурса. -
Отсутствие поддержки распределённости. Изначально протокол HTTP
разрабатывался для решения типичных бытовых задач, где само по себе время
обработки запроса должно занимать незначительное время или вовсе не
приниматься в расчёт. Однако со временем стало очевидно, что при
промышленном использовании с применением распределённых вычислений при
высоких нагрузках на сервер протокол HTTP оказывается непригоден. В
связи с этим с 1998 году был предложен альтернативный протокол HTTP-NG (англ. HTTP Next
Generation), но этот протокол до сих пор находится на стадии разработки.
Конвейерная обработка HTTP (pipelining)
Другая технология, которая позволяет увеличить скорость передачи данных HTTP, называется HTTP pipelining, по-русски конвейерная обработка. Она заключается в следующем, после того как сделали запрос на получение HTML странички, получили ответ, браузер проанализировал ответ и извлек перечень всех ресурсов которые нужно загрузить с сервера.
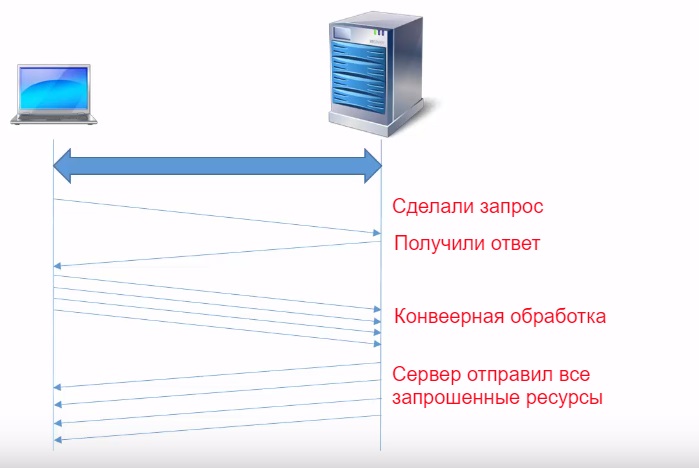
Конвейерная обработка позволяет передать от клиента серверу сразу несколько запросов для загрузки ресурсов не дожидаясь получения ответа.
Сервер получив несколько запросов, в ответ отправляют сразу все запрошенные ресурсы. Недостатком технологии является то, что ресурсы должны передаваться в том же порядке в котором пришли запросы.
Однако если с загрузкой какого-то ресурса возникли проблемы, то другие ресурсы передавать нельзя даже если они уже готовы к передачи. Это проблема решена в протоколе HTTP 2.0, где можно нумеровать запросы и передавать ресурсы от сервера клиенту в любом порядке. К сожалению конвейерная обработка на практике используется достаточно редко.
Hyper Text Transfer Protocol
Интернет протокол HTTP — Hyper Text Transfer Protocol является протоколом передачи гипертекста. Он предназначен для передачи различной информации между клиентом и сервером и является символьно-ориентированным клиент-серверным протоколом.
Интернет протокол HTTP
В основе протокола лежит технология «клиент-сервер». Это предполагает наличие потребителей – клиентов. Клиенты инициализируют соединение и посылают запрос и наличие поставщиков – серверов. Сервер ждет соединения чтобы получить запрос, производит нужные операции и возвращает клиенту сообщение с результатом.
Всего было четыре версии протокола. Самый первый вариант интернет протокола HTTP 0.9 был выпущен в 1991 году и впервые издан в январе 1992 года. Он привел к урегулированию норм и правил взаимосвязи между клиентами и серверами HTTP, а соответственно к точному разграничению функций между этими элементами. Были запротоколированы основные синтаксические и семантические принципы и положения.
В феврале 2015 года вышли последние редакции черновика очередной версии протокола. Протокол HTTP 2 отличает от предшествующих протоколов то, что он является бинарным. Его основные ключевые особенности: мультиплексирование запросов, последовательность приоритетов для запросов, уплотнение заголовков. Можно загружать несколько элементов параллельно, при помощи одного TCP-соединения, поддержка push-уведомлений серверной стороны.
1.2. Пишем наш первый HTTP запрос
Если Вы думаете, что все слишком сложно, то Вы ошибаетесь. Человек так устроен, что просто не способен создавать что-то сложное, иначе он сам в этом запутается 🙂
Итак, есть браузер и есть Web-сервер. Инициатором обмена данными всегда выступает браузер. Web-сервер никому, никогда просто так ничего не пошлет, чтобы он что-нибудь отправил браузеру надо, чтобы браузер об этом попросил. Простейший HTTP запрос моет выглядеть, например, так:
GET http://www.php.net/ HTTP/1.0\r\n\r\n
- GET (В переводе с английского означает «получить») тип запроса, тип запроса может быть разным, например POST, HEAD, PUT, DELETE (часть из них мы рассмотрим ниже).
- http://www.php.net/ URI (адрес) от которого мы хотим получить хоть какую-нибудь информацию (естественно мы надеемся подучить HTML страницу).
- HTTP/1.0 тип и версия протокола, который мы будем использовать в процессе общения с сервером.
- \r\n конец строки, который необходимо повторить два раза, зачем, станет понятно немного позднее.
Загрузка нескольких ресурсов
Посмотрим как это реализуется. Прежде чем, что-то загружать с web-сервера, клиенту необходимо установить TCP соединение.

Затем выполняется запрос по протоколу HTTP.

GET возвращает web-страницу, после этого соединение закрывается.

Браузер анализирует содержимое web-страницы, видит, что необходимо загрузить целевой файл, большое количество картинок и другие элементы. Для того чтобы загрузить следующий ресурс, например стилевой файл необходимо открыть новое соединение.
После этого клиент передает запрос HTTP GET на загрузку стилевого файла.
Сервер в ответ передает этот файл.

После чего соединение снова закрывается. Таким образом, для того чтобы загрузить каждый элемент web-страницы, необходимо открыть отдельные tcp соединения.
История
Тим Бернерс-Ли
Термин гипертекст был введен Тедом Нельсоном в 1965 году в проекте Xanadu Project , который, в свою очередь, был вдохновлен видением Ванневаром Бушем 1930-х годов системы поиска и управления информацией на основе микрофильмов « memex », описанной в его эссе 1945 года « Как мы можем думать» «. Тиму Бернерсу-Ли и его команде в ЦЕРН приписывают изобретение оригинального HTTP, а также HTML и связанной с ним технологии для веб-сервера и текстового веб-браузера. Бернерс-Ли впервые предложил проект «WorldWideWeb» в 1989 году, ныне известный как World Wide Web . В первой версии протокола был только один метод, а именно GET, который запрашивал страницу с сервера. Ответ сервера всегда представлял собой HTML-страницу.
| Год | Версия HTTP |
|---|---|
| 1991 г. | 0,9 |
| 1996 г. | 1.0 |
| 1997 г. | 1.1 |
| 2015 г. | 2.0 |
| Драфт (2020) | 3.0 |
Основы HTTP
HTTP обеспечивает общение между множеством хостов и клиентов, а также поддерживает целый ряд сетевых настроек.
В основном, для общения используется TCP/IP, но это не единственный возможный вариант. По умолчанию, TCP/IP использует порт 80, но можно заюзать и другие.
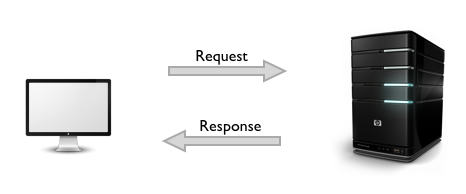
Общение между хостом и клиентом происходит в два этапа: запрос и ответ. Клиент формирует HTTP запрос, в ответ на который сервер даёт ответ (сообщение). Чуть позже, мы более подробно рассмотрим эту схему работы.
Текущая версия протокола HTTP — 1.1, в которой были введены некоторые новые фишки. На мой взгляд, самые важные из них это: поддержка постоянно открытого соединения, новый механизм передачи данных chunked transfer encoding, новые заголовки для кэширования. Что-то из этого мы рассмотрим во второй части данной статьи.
Как подключить HTTP/2
Эпоха HTTP/2 не за горами, многие браузеры уже поддерживают этот протокол. Его внедрение не требует никаких изменений в самом сайте: не нужно менять URL страниц, не нужно менять ссылки, ставить редиректы, добавлять или менять какую-то разметку или указывать дополнительные данные для Google Search Console или «Яндекс.Вебмастер».
Внедрение HTTP/2 происходит на той части сервера, которая отдает страницы пользователям, то есть на хостинге. Если вы пользуетесь внешним хостингом, то возможно, что ваши страницы уже отдаются в HTTP/2 для всех поддерживаемых браузеров.
Если вы используете собственный виртуальный или выделенный сервер, то поддержка HTTP/2 добавляется на уровне модуля к nginx (дополнительно потребуется установить SSL-сертификат и ключ на сервер): здесь неплохая инструкция.
Проверить поддержку HTTP/2 можно либо через браузерные расширения для Firefox или Chrome, либо через проверку скорости на сайте Айри.рф: в случае поддержки HTTP/2 в результатах проверки будет зеленая плашка [HTTP/2.0].
По материалам:
Блог CloudFlare Блог Джона Мюллера Блога Дэниеля Штейнберга Блога HttpWatch Блог FastCompany Блог Айри.рф
Читать по теме: Что нужно знать владельцам сайтов о протоколе HTTP/2
Мнение редакции может не совпадать с мнением автора. Если у вас есть, что дополнить — будем рады вашим комментариям. Если вы хотите написать статью с вашей точкой зрения — прочитайте правила публикации на Cossa.
Как работает HTTPS протокол сайта
HTTPS является расширенной версией HTTP. Главное отличие в том, что теперь запросы от клиента отправляются не в голом виде, а в зашифрованном благодаря криптографическим механизмам SSL и TLS. Использование этого протокола позволяет добиться такого результата, при котором запрос от клиента может быть действительно прочтен только на стороне сервера, и никак не может быть перехвачен третьей стороной где-то по середине. Этой третьей стороной могут выступать хакеры, вирусы-трояны, недобросовестные провайдеры, спецслужбы любых стран и так далее. Перехватив ваш незащищенный, отправленный по HTTP протоколу запрос, похититель может его видоизменить, может просто узнать ценную информацию и воспользоваться ей в корыстных целях. На данный момент HTTPS протокол является полностью нескомпрометированным методом взаимодействия устройств в интернете, и может выстоять против любой хакерской атаки, тем самым обеспечив максимально безопасное взаимодействие устройств в сети.
В чем различия между http и https?
Теперь перейдем к основному вопросу: в чем заключается главная разница между http и https? По ранее описанным особенностям протоколов можно понять, какие между ними отличия. Но если посмотреть более пристально, то можно понять, что есть и другие отличительные черты.
- Каждый из протоколов функционирует при помощи специальных портов. Но для работы http используется порт 80, а для https – 443.
- С учетом того, как работает https, мы ранее сделали вывод, что применяемое шифрование данных надежно защищает их от злоумышленников. Для их расшифровки используются специальные ключи, хранящиеся на сервере. Для http это не характерно.
- Защищенное соединение гарантирует полную сохранность данных. Даже если в них будут внесены незначительные коррективы, система моментально их зафиксирует.
- Протокол безопасности предоставляет аутентификацию. То есть, пользователь может быть уверен в том, что попадет именно на тот ресурс, который ищет. Такой подход помогает предотвратить любые посторонние вмешательства.
Есть еще несколько важных моментов, о которых нужно знать. Понимая, что означает https в адресе сайта, вы можете быть полностью уверенными в безопасном подключении к серверу. Но такой протокол «тянет» определенную часть ресурсов с этого самого сервера, поэтому загрузка сайта может несколько замедлиться.
На заметку. Если сайт использует http, то при перенаправлении на него поисковая система выдает уведомление о небезопасном подключении. Продолжать соединение или прервать его – это уже на ваше усмотрение.
Нужно ли переходить на HTTPS?
Если ваш сайт содержит информацию, которая быть надежно защищена, то переходить на безопасный протокол нужно обязательно. В противном случае в любой момент важные данные могут быть украдены и использованы в мошеннических целях. Но будьте готовы к тому, что за переход на https вам придется вносить дополнительную плату, если выберете платный SSL-сертификат. А также оплачивать услуги программиста фрилансера от 1000 до 3000 рублей.
При создании новых ресурсов лучше сразу подключать защищенный протокол, поскольку, как утверждают эксперты, в будущем преимущество будет отдаваться именно им. Например, в браузерах такие сайты будут помечены значками, что повысит их посещаемость.
Таким образом, http и https – это понятия во многом схожие, но между ними есть принципиальная разница. Зная, в чем она заключается, каждый сайтовладелец сможет выбрать для себя оптимальный вариант.
HTTP/1.1 – 1999
Прошло 3 года со времён HTTP/1.0, и в 1999 вышла новая версия протокола — HTTP/1.1, включающая множество улучшений:
- Новые HTTP-методы — PUT, PATCH, HEAD, OPTIONS, DELETE.
- Идентификация хостов. В HTTP/1.0 заголовок Host не был обязательным, а HTTP/1.1 сделал его таковым.
- Постоянные соединения. Как говорилось выше, в HTTP/1.0 одно соединение обрабатывало лишь один запрос и после этого сразу закрывалось, что вызывало серьёзные проблемы с производительностью и проблемы с задержками. В HTTP/1.1 появились постоянные соединения, т.е. соединения, которые по умолчанию не закрывались, оставаясь открытыми для нескольких последовательных запросов. Чтобы закрыть соединение, нужно было при запросе добавить заголовок Connection: close. Клиенты обычно посылали этот заголовок в последнем запросе к серверу, чтобы безопасно закрыть соединение.
- Потоковая передача данных, при которой клиент может в рамках соединения посылать множественные запросы к серверу, не ожидая ответов, а сервер посылает ответы в той же последовательности, в которой получены запросы. Но, вы можете спросить, как же клиент узнает, когда закончится один ответ и начнётся другой? Для разрешения этой задачи устанавливается заголовок Content-Length, с помощью которого клиент определяет, где заканчивается один ответ и можно ожидать следующий.
Замечу, что для того, чтобы ощутить пользу постоянных соединений или потоковой передачи данных, заголовок Content-Length должен быть доступен в ответе. Это позволит клиенту понять, когда завершится передача и можно будет отправить следующий запрос (в случае обычных последовательных запросов) или начинать ожидание следующего ответа (в случае потоковой передачи).
Но в таком подходе по-прежнему оставались проблемы. Что, если данные динамичны, и сервер не может перед отправкой узнать длину контента? Получается, в этом случае мы не можем пользоваться постоянными соединениями? Чтобы разрешить эту задачу, HTTP/1.1 ввёл сhunked encoding — механизм разбиения информации на небольшие части (chunks) и их передачу.
- Chunked Transfers если контент строится динамически и сервер в начале передачи не может определить Content-Length, он начинает отсылать контент частями, друг за другом, и добавлять Content-Length к каждой передаваемой части. Когда все части отправлены, посылается пустой пакет с заголовком Content-Length, установленным в 0, сигнализируя клиенту, что передача завершена. Чтобы сказать клиенту, что передача будет вестись по частям, сервер добавляет заголовок Transfer-Encoding: chunked.
- В отличие от базовой аутентификации в HTTP/1.0, в HTTP/1.1 добавились дайджест-аутентификация и прокси-аутентификация.
- Кэширование.
- Диапазоны байт (byte ranges).
- Кодировки
- Согласование содержимого (content negotiation).
- Клиентские куки.
- Улучшенная поддержка сжатия.
- И другие…
Особенности HTTP/1.1 — отдельная тема для разговора, и в этой статье я не буду задерживаться на ней надолго. Вы можете найти огромное количество материалов по этой теме. Рекомендую к прочтению Key differences between HTTP/1.0 and HTTP/1.1 и, для супергероев, ссылку на RFC.
HTTP/1.1 появился в 1999 и пробыл стандартом долгие годы. И, хотя он и был намного лучше своего предшественника, со временем начал устаревать. Веб постоянно растёт и меняется, и с каждым днём загрузка веб-страниц требует всё больших ресурсов. Сегодня стандартной веб-странице приходится открывать более 30 соединений. Вы скажете: «Но… ведь… в HTTP/1.1 существуют постоянные соединения…». Однако, дело в том, что HTTP/1.1 поддерживает лишь одно внешнее соединение в любой момент времени. HTTP/1.1 пытался исправить это потоковой передачей данных, однако это не решало задачу полностью. Возникала проблема блокировки начала очереди (head-of-line blocking) — когда медленный или большой запрос блокировал все последующие (ведь они выполнялись в порядке очереди). Чтобы преодолеть эти недостатки HTTP/1.1, разработчики изобретали обходные пути. Примером тому служат спрайты, закодированные в CSS изображения, конкатенация CSS и JS файлов, доменное шардирование и другие.
Заключение о протоколе HTTP
Итак, постоянное соединение HTTP позволяет использовать одно и то же TCP соединение для загрузки нескольких ресурсов. Это позволяет сократить время на установку соединения TCP, нет необходимости каждый раз проходить процедуру трехкратного рукопожатия.
В стандарте http 1.0 не было поддержки постоянного соединения, эта возможность была добавлена уже после публикации стандарта в виде заголовка connection: keep-alive. В стандарте http 1.1 все соединения по умолчанию постоянны и заголовок connection: keep-alive использовать не обязательно.
Мы рассмотрели кэширование web и его поддержку в протоколе http. Если в страницу, ввести какой-то ресурс из кэша, то загрузка происходит значительно быстрее, чем если мы обращаемся за тем же самым ресурсом в сеть. Необходимо иметь ввиду, что данные кэшируется не только в кэше web-браузера, это так называемый частный кэш, который является отдельным для каждого пользователя, но и данные могут быть закэшированные в других местах. Например, на прокси-серверах, на обратных прокси-серверах, которые копируют запросы большого количества пользователей и такой кэш называется разделяемый.