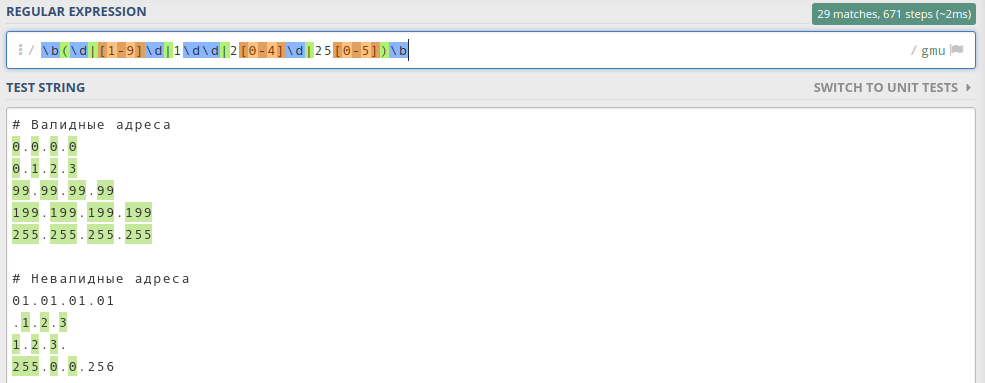
Regexp.prototype.test()
Содержание:
- «Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
- Ретроспективная проверка
- search()
- Примеры
- Статические свойства
- Квантификаторы
- Квантификаторы
- exec()
- Как использовать регулярные выражения с методами объекта String?
- Backreferences в паттерне и при замене
- Методы Javascript для работы с регулярными выражениями
- Упрощённый пример
- Метасимволы
- Содержимое скобок в match
- Удаляем заглавные буквы с помощью строк и регулярных выражений
- Правила написания шаблонов в JavaScript
- МетаСимволы
- Составление регулярных выражений
«Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст . Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как , так и |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт и |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт , , , и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт , , и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова , но проигнорирует |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор . К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>…) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^+$/ | Соответствует любому выражению , но не | |
| Если внутри квадратных скобок указать минус, то это считается диапазоном | /+/ | Аналог /\w/ui для JavaScript | |
| Если минус является первым или последним символом диапазона, то это просто минус | /+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) | |
| Квадратные скобки с «крышечекой» означают любой символ НЕ входящий в диапазон | //i | Найдёт любой символ, который не является буквой, числом или пробелом | |
| ] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Ретроспективная проверка
Опережающие проверки позволяют задавать условия на то, что «идёт после».
Ретроспективная проверка выполняет такую же функцию, но с просмотром назад. Другими словами, она находит соответствие шаблону, только если перед ним есть что-то заранее определённое.
Синтаксис:
- Позитивная ретроспективная проверка: , ищет совпадение с при условии, что перед ним ЕСТЬ .
- Негативная ретроспективная проверка: , ищет совпадение с при условии, что перед ним НЕТ .
Чтобы протестировать ретроспективную проверку, давайте поменяем валюту на доллары США. Знак доллара обычно ставится перед суммой денег, поэтому для того чтобы найти , мы используем – число, перед которым идёт :
Если нам необходимо найти количество индеек – число, перед которым не идёт , мы можем использовать негативную ретроспективную проверку :
search()
Первый метод, , ищет в строке заданный шаблон. Если он находит совпадение, то возвращает позицию в строке, где это совпадение начинается. Если совпадения нет, возвращается . Нужно запомнить, что метод возвращает позицию только первого совпадения. После нахождения первого совпадения он прекращает работу.
// Синтаксис метода search()// 'проверяемый текст'.search(/шаблон/)// Создание текста для проверкиconst myString = 'The world of code is not full of code.'// Описание шаблонаconst myPattern = /code/// Использование search() для поиска//совпадения строки с шаблоном,//когда search() находит совпадениеmyString.search(myPattern)// -13// Вызов search() прямо на строке,// когда search() не находит совпадений'Another day in the life.'.search(myPattern)// -1
Примеры
Разберём скобки на примерах.
Без скобок шаблон означает символ и идущий после него символ , который повторяется один или более раз. Например, или .
Скобки группируют символы вместе. Так что означает , , и т.п.
Сделаем что-то более сложное – регулярное выражение, которое соответствует домену сайта.
Например:
Как видно, домен состоит из повторяющихся слов, причём после каждого, кроме последнего, стоит точка.
На языке регулярных выражений :
Поиск работает, но такому шаблону не соответствует домен с дефисом, например, , так как дефис не входит в класс .
Можно исправить это, заменим на везде, кроме как в конце: .
Итоговый шаблон:
Статические свойства
Ну и напоследок — еще одна совсем оригинальная особенность регулярных выражений.
Вот — одна интересная функция.
Запустите ее один раз, запомните результат — и запустите еще раз.
function rere() {
var re1 = /0/, re2 = new RegExp('0')
alert()
re1.foo = 1
re2.foo = 1
}
rere()
В зависимости от браузера, результат первого запуска может отличаться от второго. На текущий момент, это так для Firefox, Opera. При этом в Internet Explorer все нормально.
С виду функция создает две локальные переменные и не зависит от каких-то внешних факторов.
Почему же разный результат?
Ответ кроется в стандарте ECMAScript, :
Цитата…
A regular expression literal is an input element that is converted to a RegExp object (section 15.10)
when it is scanned. The object is created before evaluation of the containing program or function begins.
Evaluation of the literal produces a reference to that object; it does not create a new object.
То есть, простыми словами, литеральный регэксп не создается каждый раз при вызове .
Вместо этого браузер возвращает уже существующий объект, со всеми свойствами, оставшимися от предыдущего запуска.
В отличие от этого, всегда создает новый объект, поэтому и ведет себя в примере по-другому.
Квантификаторы
Квантификаторы используются, когда необходимо указать количество символов или выражений, по которым производится сопоставление.
/* Квантификатор - Значение */* - 0 или более совпадений с предшествующим выражением.+ - 1 или более совпадений с предшествующим выражением.? - Предшествующее выражение необязательно (то есть совпадений 0 или 1).x{n} - "n" должно быть целым положительным числом. Количество вхождений предшествующего выражения "x" равно "n".x{n, } - "n" должно быть целым положительным числом. Количество вхождений предшествующего выражения "x" равно, как минимум, "n".x{n, m} - "n" может быть равно 0 или целому положительному числу. "m" - целое положительное число. Если "m" > "n", количество вхождений предшествующего выражения "x" равно минимум "n" и максимум "m".
Примеры:
// * - 0 или более совпадений с предшествующим выражениемconst myPattern = /bo*k/console.log(myPattern.test('b'))// falseconsole.log(myPattern.test('bk'))// trueconsole.log(myPattern.test('bok'))// true// + - 1 или более совпадений с предшествующим выражениемconst myPattern = /\d+/console.log(myPattern.test('word'))// falseconsole.log(myPattern.test(13))// true// ? - Предшествующее выражение необязательно, совпадений 0 или 1const myPattern = /foo?bar/console.log(myPattern.test('foobar'))// trueconsole.log(myPattern.test('fooobar'))// false// x{n} - Количество вхождений предшествующего выражения "x" равно "n"const myPattern = /bo{2}m/console.log(myPattern.test('bom'))// falseconsole.log(myPattern.test('boom'))// trueconsole.log(myPattern.test('booom'))// false// x{n, } - Количество вхождений предшествующего выражения "x" равно, как минимум, "n"const myPattern = /do{2,}r/console.log(myPattern.test('dor'))// falseconsole.log(myPattern.test('door'))// trueconsole.log(myPattern.test('dooor'))// true// x{n, m} - Количество вхождений предшествующего выражения "x" равно минимум "n" и максимум "m"const myPattern = /zo{1,3}m/console.log(myPattern.test('zom'))// falseconsole.log(myPattern.test('zoom'))// trueconsole.log(myPattern.test('zooom'))// trueconsole.log(myPattern.test('zoooom'))// false
Квантификаторы
| Символ | Описание |
|---|---|
| n* | Сопостовление происходит с любой строкой, содержащей ноль или более вхождений символа n. |
| n+ | Сопостовление происходит с любой строкой, содержащей хотя бы один символ n. |
| n? | Сопостовление происходит с любой строкой с предшествующим элементом n ноль или один раз. |
| n{x} | Соответствует любой строке, содержащей последовательность символов n определенное количество раз x. X должно быть целым положительным числом. |
| n{x,} | Соответствует любой строке, содержащей по крайней мере x вхождений предшествующего элемента n. X должно быть целым положительным числом. |
| n{x, y} | Соответствует любой строке, содержащей по крайней мере x, но не более, чем с y вхождениями предшествующего элемента n. X и y должны быть целыми положительными числами. |
| n*? n+? n?? n{x}? n{x,}? n{x,y}? |
Сопостовление происходит по аналогии с квантификаторами *, +, ? и {…}, однако при этом поиск идет минимально возможного сопоставления. По умолчанию используется «жадный» режим, ? в конце квантификатора позволяет задать «нежадный» режим при котором повторение сопоставления происходит минимально возможное количество раз. |
| x(?=y) | Позволяет сопоставить x, только если за x следует y. |
| x(?!y) | Позволяет сопоставить x, только если за x не следует y. |
| x|y | Сопоставление происходит с любой из указанных альтернатив. |
exec()
Ещё один метод, который можно использовать — . Если есть совпадение, метод возвращает массив. Массив содержит в себе информацию об используемом шаблоне, позиции, на которой было найдено совпадение, проверяемом тексте и наборах. Если совпадений нет, метод возвращает .
Необходимо запомнить одну вещь: метод возвращает информацию только о первом найденном в тексте совпадении. Он прекращает работу после нахождения первого совпадения. Не используйте этот метод, если хотите получить множественные совпадения.
// Синтаксис метода exec()// /шаблон/.exec('проверяемый текст')// Создание строки для проверкиconst myString = 'The world of code is not full of code.'// Описание шаблонаconst myPattern = /code/// Использование exec() для проверки текста,// когда exec() находит совпадениеmyPattern.exec(myString)// [// 'code',// index: 13,// input: 'The world of code is not full of code.',// groups: undefined// ]// Описание другого шаблонаconst myPatternTwo = /JavaScript/// Использование exec() с новым шаблоном для новой проверки текста,// когда exec() не находит совпаденийmyPatternTwo.exec(myString)// null
Как использовать регулярные выражения с методами объекта String?
и — не единственные методы, которые можно использовать для поиска совпадений строки с шаблоном. Есть ещё , и . Эти методы принадлежат не объекту RegExp, а строкам. Несмотря на это, они позволяют применять регулярные выражения.
Чтобы использовать эти методы, нужно инвертировать синтаксис. Поскольку методы вызываются на строках, а не на шаблонах, в качестве аргумента надо передать не строку, а шаблон.
Backreferences в паттерне и при замене
Иногда нужно в самом паттерне поиска обратиться к предыдущей его части.
Например, при поиске BB-тагов, то есть строк вида , и . Или при поиске атрибутов, которые могут быть в одинарных кавычках или двойных.
Обращение к предыдущей части паттерна в javascript осуществляется как \1, \2 и т.п., бэкслеш + номер скобочной группы:
text = ' a b c ' var reg = /\)\](.*?)\[\//*u*/\1/*/u*/\]/ text = text.replace(reg, '<$1>$2</$1>') alert(text)
Обращение к скобочной группе в строке замены идет уже через доллар: . Не знаю, почему, наверное так удобнее..
P.S. Понятно, что при таком способе поиска bb-тагов придется пропустить текст через замену несколько раз — пока результат не перестанет отличаться от оригинала.
Методы Javascript для работы с регулярными выражениями
В Javascript Существует 6 методов для работы с регулярными выражениями. Чаще всего мы будем использовать только половину из них.
Метод exec()
Метод RegExp, который выполняет поиск совпадения в строке. Он возвращает массив данных. Например:
var str = 'Some fruit: Banana - 5 pieces. For 15 monkeys.'; var re = /(\w+) - (\d) pieces/ig; var result = re.exec(str); window.console.log(result); // result = // Так же мы можем посмотреть позицию совпадения - result.index
В результате мы получим массив, первым элементом которого будет вся совпавшая по паттерну строка, а дальше содержимое скобочных групп. Если совпадений с паттерном нету, то .
Метод test()
Метод RegExp, который проверяет совпадение в строке, возвращает либо true, либо false. Очень удобен, когда нам необходимо проверить наличие или отсутствие паттерна в тексте. Например:
var str = 'Balance: 145335 satoshi'; var re = /Balance:/ig; var result = re.test(str); window.console.log(result); // true
В данном примере, есть совпадение с паттерном, поэтому получаем true.
Метод search()
Метод String, который тестирует на совпадение в строке. Он возвращет индекс совпадения, или -1 если совпадений не будет найдено. Очень похож на метод indexOf() для работы со строками. Минус этого метода — он ищет только первое совпадение. Для поиска всех совпадений используйте метод match().
var str = "Умея автоматизировать процессы, можно зарабатывать миллионы"; window.console.log(str.search(/можно/igm)); // 60 window.console.log(str.search(/атата/igm)); // -1
Метод match()
Метод String, который выполняет поиск совпадения в строке. Он возвращет массив данных либо null если совпадения отсутствуют.
// Без использования скобочных групп
var str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
var regexp = //gi;
var matches_array = str.match(regexp);
window.console.log(matches_array); //
// С использованием скобочных групп без флага g
var str = 'Fruits quantity: Apple - 5, Banana - 7, Orange - 12. I like fruits.';
var found = str.match(/(\d{1,2})/i);
window.console.log(found); // Находит первое совпадение и возвращает объект
// {
// 0: "5"
// 1: "5"
// index: 25
// input: "Fruits quantity: Apple -...ge - 12. I like fruits."
// }
// С использованием скобочных групп с флагом g
var found = str.match(/(\d{1,2})/igm);
window.console.log(found); //
Если совпадений нету — возвращает null.
Метод replace()
Метод String, который выполняет поиск совпадения в строке, и заменяет совпавшую подстроку другой подстрокой переданной как аргумент в этот метод. Мы уже использовали эту функцию для работы о строками, регулярные выражения привносят новые возможности.
// Обычная замена var str = 'iMacros is awesome, and iMacros is give me profit!'; var newstr = str.replace(/iMacros/gi, 'Javascript'); window.console.log(newstr); // Javascript is awesome, and Javascript is give me profit! // Замена, используя параметры. Меняем слова местами: var re = /(\w+)\s(\w+)/; var str = 'iMacros JS'; var newstr = str.replace(re, '$2, $1'); // в переменных $1 и $2 находятся значения из скобочных групп window.console.log(newstr); // JS iMacros
У метода replace() есть очень важная особенность — он имеет свой каллбэк. То есть, в качестве аргумента мы можем подавать функцию, которая будет обрабатывать каждое найденное совпадение.
Нестандартное применение метода replace():
var str = `
I have some fruits:
Orange - 5 pieces
Banana - 7 pieces
Apple - 15 pieces
It's all.
`;
var arr = []; // Сюда складируем данные о фруктах и их количестве
var newString = str.replace(/(\w+) - (\d) pieces/igm, function (match, p1, p2, offset, string) {
window.console.log(arguments);
arr.push({
name: p1,
quantity: p2
});
return match;
});
window.console.log(newString); // Текст не изменился, как и было задумано
window.console.log(arr); // Мы получили удобный массив объектов, с которым легко и приятно работать
Как вы видите, мы использовали этот метод для обработки каждого совпадения. Мы вытащили из паттерна название фрукта и количество и поместили эти значения в массив объектов, как мы уже делали ранее
Обратите внимание на аргумент функции offset — это будет индекс начала совпадения, этот параметр нам потом пригодится. В нашем случае, мы имеем 2 скобочные группы в паттерне, поэтому у нас в функции 5 аргументов, но их там может быть и больше
Метод split()
Метод String, который использует регулярное выражение или фиксированую строку чтобы разбить строку на массив подстрок.
var str = "08-11-2016";
// Разбиваем строку по разделителю
window.console.log(str.split('-')); //
// Такой же пример с регэкспом
window.console.log(str.split(/-/)); //
Упрощённый пример
В чём же дело? Почему регулярное выражение «зависает»?
Чтобы это понять, упростим пример: уберём из него пробелы . Получится .
И, для большей наглядности, заменим на . Получившееся регулярное выражение тоже будет «зависать», например:
В чём же дело, что не так с регулярным выражением?
Внимательный читатель, посмотрев на , наверняка удивится, ведь оно какое-то странное. Квантификатор здесь выглядит лишним. Если хочется найти число, то с тем же успехом можно искать .
Действительно, это регулярное выражение носит искусственный характер, но, разобравшись с ним, мы поймём и практический пример, данный выше. Причина их медленной работы одинакова. Поэтому оставим как есть.
Что же происходит во время поиска в строке (укоротим для ясности), почему всё так долго?
-
Первым делом, движок регулярных выражений пытается найти . Плюс является жадным по умолчанию, так что он хватает все цифры, какие может:
Затем движок пытается применить квантификатор , но больше цифр нет, так что звёздочка ничего не даёт.
Далее по шаблону ожидается конец строки , а в тексте символ , так что соответствий нет:
-
Так как соответствие не найдено, то «жадный» квантификатор уменьшает количество повторений, возвращается на один символ назад.
Теперь – это все цифры, за исключением последней:
-
Далее движок снова пытается продолжить поиск, начиная уже с позиции ().
Звёздочка теперь может быть применена – она даёт второе число :
Затем движок ожидает найти , но это ему не удаётся, ведь строка оканчивается на :
-
Так как совпадения нет, то поисковый движок продолжает отступать назад. Общее правило таково: последний жадный квантификатор уменьшает количество повторений до тех пор, пока это возможно. Затем понижается предыдущий «жадный» квантификатор и т.д.
Перебираются все возможные комбинации. Вот их примеры.
Когда первое число содержит 7 цифр, а дальше число из 2 цифр:
Когда первое число содержит 7 цифр, а дальше два числа по 1 цифре:
Когда первое число содержит 6 цифр, а дальше одно число из 3 цифр:
Когда первое число содержит 6 цифр, а затем два числа:
…И так далее.
Существует много способов как разбить на числа набор цифр . Если быть точным, их , где – длина набора.
В случае их порядка миллиона, при – ещё в тысячу раз больше. На их перебор и тратится время.
Что же делать?
Может нам стоит использовать «ленивый» режим?
К сожалению, нет: если мы заменим на , то регулярное выражение всё ещё будет «зависать». Поменяется только порядок перебора, но не общее количество комбинаций.
Некоторые движки регулярных выражений содержат хитрые проверки и конечные автоматы, которые позволяют избежать полного перебора в таких ситуациях или кардинально ускорить его, но не все движки и не всегда.
Метасимволы
Метасимволы — специальные символы, которые указывают на поиск символов или цифр в диапазоне:
- . — точка обозначает любой один символ кроме перевода строки;
- \w — находит любой буквенный символ;
- \W — находит любой небуквенный символ;
- \d — любой символ, соответствующий цифре;
- \D — любой символ не соответствующий цифре;
- \s — соответствует пробельному символу;
- \S — соответствует любому символу кроме пробела;
- \b — соответствие символу, с которого начинается искомая строка;
- \n — соответствует символу перевода строки;
- \t — соответствует tab символу;
- \xxx — указывается символ кода в десятичной системе исчисления;
- \xdd — символ в шестнадцатиричной системе исчисления;
- \udddd — находит символ юникода по десятичному коду.
Пример:
Содержимое скобок в match
Скобочные группы нумеруются слева направо. Поисковый движок запоминает содержимое, которое соответствует каждой скобочной группе, и позволяет получить его в результате.
Метод , если у регулярного выражения нет флага , ищет первое совпадение и возвращает его в виде массива:
- На позиции будет всё совпадение целиком.
- На позиции – содержимое первой скобочной группы.
- На позиции – содержимое второй скобочной группы.
- …и так далее…
Например, мы хотим найти HTML теги и обработать их. Было бы удобно иметь содержимое тега (то, что внутри уголков) в отдельной переменной.
Давайте заключим внутреннее содержимое в круглые скобки: .
Теперь получим как тег целиком , так и его содержимое в виде массива:
Скобки могут быть и вложенными.
Например, при поиске тега в нас может интересовать:
- Содержимое тега целиком: .
- Название тега: .
- Атрибуты тега: .
Заключим их в скобки в шаблоне: .
Вот их номера (слева направо, по открывающей скобке):
В действии:
По нулевому индексу в всегда идёт полное совпадение.
Затем следуют группы, нумеруемые слева направо, по открывающим скобкам. Группа, открывающая скобка которой идёт первой, получает первый индекс в результате – . Там находится всё содержимое тега.
Затем в идёт группа, образованная второй открывающей скобкой – имя тега, далее в будет остальное содержимое тега: .
Соответствие для каждой группы в строке:
Даже если скобочная группа необязательна (например, стоит квантификатор ), соответствующий элемент массива существует и равен .
Например, рассмотрим регулярное выражение . Оно ищет букву , за которой идёт необязательная буква , за которой, в свою очередь, идёт необязательная буква .
Если применить его к строке из одной буквы , то результат будет такой:
Массив имеет длину , но все скобочные группы пустые.
А теперь более сложная ситуация для строки :
Длина массива всегда равна . Для группы ничего нет, поэтому результат: .
Удаляем заглавные буквы с помощью строк и регулярных выражений
Теперь у нас есть строка с кучей ненужных прописных букв. Вы догадались, как их удалить? Во-первых, нам нужно выбрать все заглавные буквы. Затем используем поиск набора символов с помощью глобального модификатора //g. Мы снова будем использовать метод replace, но как в этот раз сделать строчной символ?
Пример:
Квадратные скобки задают диапазон символов (в данном случае — любые буквы английского алфавита в нижнем регистре). Все, что попадает в этот диапазон, будет соответствовать шаблону. Диапазоны символов могут быть разными. Это могут быть буквы в верхнем регистре (тогда диапазон будет выглядеть как ) или цифры ().
Если ваш диапазон должен охватывать все буквенно-цифровые символы и символ подчеркивания, то шаблон может выглядеть следующим образом: .
Правила написания шаблонов в JavaScript
К самим выражением мы подойдем чуть позже, а пока разберем, что же под собой подразумевает такой параметр, как флаг.
Итак, flag – это инструмент для установки глобального или регистронезависимого поиска. В JS можно использовать четыре вида флага. При этом вы можете их прописывать как по отдельности, так и комбинировать в разном порядке и количестве. Хочу заметить, что от смены порядка результат выполнение не изменится.
| Флаг | Предназначение |
| m | Определяет многострочный поиск, т.е. образец сравнивается со всеми буквами, цифрами или другими знаками, которые разделены между собой известными пробельными символами. |
| i | Поиск подстрок осуществляется без учета регистра. |
| y | Выполнение проверки переменных начинается от символа, находящегося на позиции свойства под названием lastIndex. |
| g | Задает глобальный поиск, после выполнения которого будут выведены все возможные совпадения. |
Ну а теперь давайте рассмотрим первый простой пример для понимания происходящего. С помощью переменной regExp я проверяю, есть ли вхождение в text слова «вариант». При этом я хочу, чтобы вывелись все случаи вхождения без учета регистра.
1 2 3 4 5 6 |
<script> var regExp = /вариант/gi; var text = "Вариант 1. напишите стих, состоящий из четырех строк. Вариант 2. Допишите стих из варианта 1."; var myArray = text.match(regExp ); alert(myArray); </script> |
МетаСимволы
Для указания регулярных выражений используются метасимволы. В приведенном выше примере ( ) является метасимволом.
Метасимволы — это символы, которые интерпретируются особым образом механизмом RegEx. Вот список метасимволов:
[]. ^ $ * +? {} () \ |
— Квадратные скобки
Квадратные скобки указывают набор символов, которые вы хотите сопоставить.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 2 совпадения | ||
| Не совпадает | ||
| 5 совпадений |
Здесь будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любой из символов , или .
Вы также можете указать диапазон символов, используя дефис в квадратных скобках.
то же самое, что и .
то же самое, что и .
то же самое, что и .
Вы можете дополСтрока (инвертировать) набор символов, используя символ вставки в начале квадратной скобки.
означает любой символ, кроме или или .
означает любой нецифровой символ.
— Точка
Точка соответствует любому одиночному символу (кроме новой строки ).
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение | ||
| 1 совпадение | ||
| 2 совпадения (содержит 4 символа) |
— Каретка
Символ каретки используется для проверки того, начинается ли строка с определенного символа.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| Не совпадает | ||
| 1 совпадение | ||
| Нет совпадений (начинается с , но не сопровождается ) |
— доллар
Символ доллара используется для проверки того, заканчивается ли строка определенным символом.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| Не совпадает |
— Звездочка
Символ звездочки соответствует предыдущему символу повторенному 0 или более раз. Эквивалентно {0,}.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение | ||
| 1 совпадение | ||
| 1 совпадение | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Плюс
Символ плюс соответствует предыдущему символу повторенному 1 или более раз. Эквивалентно {1,}.
| Выражение | Строка | Совпадения |
|---|---|---|
| Нет совпадений (нет символа) | ||
| 1 совпадение | ||
| 1 совпадение | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Вопросительный знак
Знак вопроса соответствует нулю или одному вхождению предыдущего символа. То же самое, что и {0,1}. По сути, делает символ необязательным.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение (0 вхождений а) | ||
| 1 совпадение | ||
| Нет совпадений (более одного символа) | ||
| Нет совпадений ( не следует ) | ||
| 1 совпадение |
— Фигурные скобки
Рассмотрим следующий код: . Это означает, по крайней мере , и не больше повторений предыдущего символа. При m=n=1 пропускается..
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (в ) | ||
| 2 совпадения (при и ) | ||
| 2 совпадения (при и ) |
Посмотрим еще один пример. Это RegEx соответствует как минимум 2 цифрам, но не более 4-х цифр.
| Выражение | Строка | Совпадения |
|---|---|---|
| 1 совпадение (совпадение в ) | ||
| 3 совпадения ( , , ) | ||
| Не совпадает |
— Альтернация (или)
Альтернация (вертикальная черта) – термин в регулярных выражениях, которому в русском языке соответствует слово «ИЛИ». (оператор ).
Например: gr(a|e)y означает точно то же, что и gry.
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (совпадение в ) | ||
| 3 совпадения (в ) |
Здесь сопоставьте любую строку, содержащую либо, либо
Чтобы примеСтрока альтернацию только к части шаблона, можно заключить её в скобки:
- найдёт или .
- найдёт или .
— Скобочные группы
Круглые скобки используются для группировки подшаблонов. Так, например, соответствует любой строке, которая соответствует либо или или с последующим
| Выражение | Строка | Совпадения |
|---|---|---|
| Не совпадает | ||
| 1 совпадение (совпадение в ) | ||
| 2 совпадения (в ) |
— обратная косая черта
Обратная косая черта используется для экранирования различных символов, включая все метасимволы. Например,
соответствует, если строка содержит , за которым следует . Здесь механизм RegEx не интерпретирует особым образом.
Если вы не уверены, имеет ли символ особое значение или нет, вы можете экранировать его косой чертой . Это гарантирует, что экранированный символ не будет компилироваться по-особенному.
Составление регулярных выражений
Для поиска символов определенного вида в регулярных выражениях есть «классы символов». Например ищет одну цифру. Есть и другие классы.
Основные классы
- – цифры.
- – не-цифры.
- – пробельные символы, переводы строки.
- – всё, кроме \s.
- – латиница, цифры, подчёркивание ‘_’.
- – всё, кроме \w.
- – символ табуляции
- – символ перевода строки
- – точка обозначает любой символ, кроме перевода строки.
Помимо классов, есть наборы символов, причем помимо стандартных, можно самому создавать набор символов, используя .
Наборы символов
- – произвольный символ от a до z
- произвольный символ от B до G в верхнем регистре
- – то же самое, что и \d, любая цифра от 0 до 9
- – любая цифра или буква, можно комбинировать диапазоны
- – диапазон «кроме», ищет любые символы, кроме цифр
Обратите внимание, в квадратных скобках, большинство специальных символов можно использовать без экранирования
Не экранируем в квадратных скобках
- Точка .
- Плюс .
- Круглые скобки .
- Дефис , если он находится в начале или конце квадратных скобок, то есть не выделяет диапазон.
- Символ каретки , если не находится в начале квадратных скобок.
- А также открывающая квадратная скобка .
Квантификаторы +, *, ? и {n}
- Количество {n} — 5 цифр — одна или больше цифр — от одной до 5 цифр
- Один или более +, аналог {1,} — одна или более цифр — одна или более букв от a до z
- Ноль или один ?, аналог {0,1} — найдет color и colour
- Означает «ноль или более» *, аналог {0,} — найдет «1» и «100» в строке «1 100», символ может повторяться много раз или вообще отсутствовать.
Скобочные группы
Вы можете заключить одну или несколько частей шаблона в скобки — это и будет называться скобочной группой. Основной профит — при использовании методов match, exec, replace — можно вытащить значения в скобках в отдельный элемент массива. И еще, если поставить квантификатор после скобки, то он применится ко всей скобке, а не к одному символу. Еще вы можете использовать вложенные скобки, то есть разбивать большой шаблон на несколько маленьких.
Пример использования вы можете посмотреть выше — в нестандартном применении метода replace().
Простым языком, это «ИЛИ».
— аналог \d -любая цифра — найдет «imacros» или «js»
Начало строки ^ и конец $
Знак каретки ‘^’ и доллара ‘$’ имеют в регулярном выражении особый смысл. Их называют «якорями» (anchor – англ.).
Каретка совпадает в начале текста, а доллар – в конце. Знак доллара $ используют, чтобы указать, что паттерн должен заканчиваться в конце текста, знак каретки ^ — что паттерн должен начинаться с первого символа строки.